
HowMuch_YouWant2Pwn-1
HowMuch_YouWant2Pwn-1
cvestone- 描述
- 0x00 前言
- 0x01 打pwn需要准备的武器库
- 0x02 副武器
- 0x03 gcc的基本使用
- 0x04 主武器gdb
- 0x05 汇编指令补充辨析
- 0x06 cpu和寄存器和(虚拟)内存之间的关系
- 0x07 pwn题常见函数
- 0x08 pwn题远程部署
- 0x09 用python脚本打pwn的原因
描述
b站pwn启蒙元老级师傅国资社畜 《你想有多pwn》学习记录与补充
0x00 前言
qaq真的很感谢这个up主提供的pwn入门课程,对pwn新手真的特别友好,学pwn必备!感觉看了一部分《程序员的自我修养》和这个课,可以说打通了一小部分pwn的任督二脉了,总之算是学pwn的一个很好开头,希望今后的学习也能保持这种状态!
0x01 打pwn需要准备的武器库

0x02 副武器
- file 程序名:可查看文件类型以及一些大致信息
readelf -a 程序名:查看elf文件所有节、符号表等信息- hexdump 程序名:把指令数据等用十六进制表示出来
ldd 程序名:可以查看库函数所在库的位置objdump -d 程序名:输出反汇编后的汇编指令 (默认是采用att语法格式输出,如果要intel格式可以-M intel)checksec 程序名:检查程序开启的保护选项
上面的之所以是副武器,因为实际上并不算经常用或者用的不多。
0x03 gcc的基本使用
常用编译参数
(1)-o参数: gcc xx.c -o 程序名【直接编译成程序】
可以发现直接编译后所有的保护都已开启: 
(2)-S参数: gcc -S xx.c
【编译成汇编代码(注意这里和objdump反汇编出来的还是有点差别的,这个是程序对应的真正的汇编代码)】
两者的区别如下: 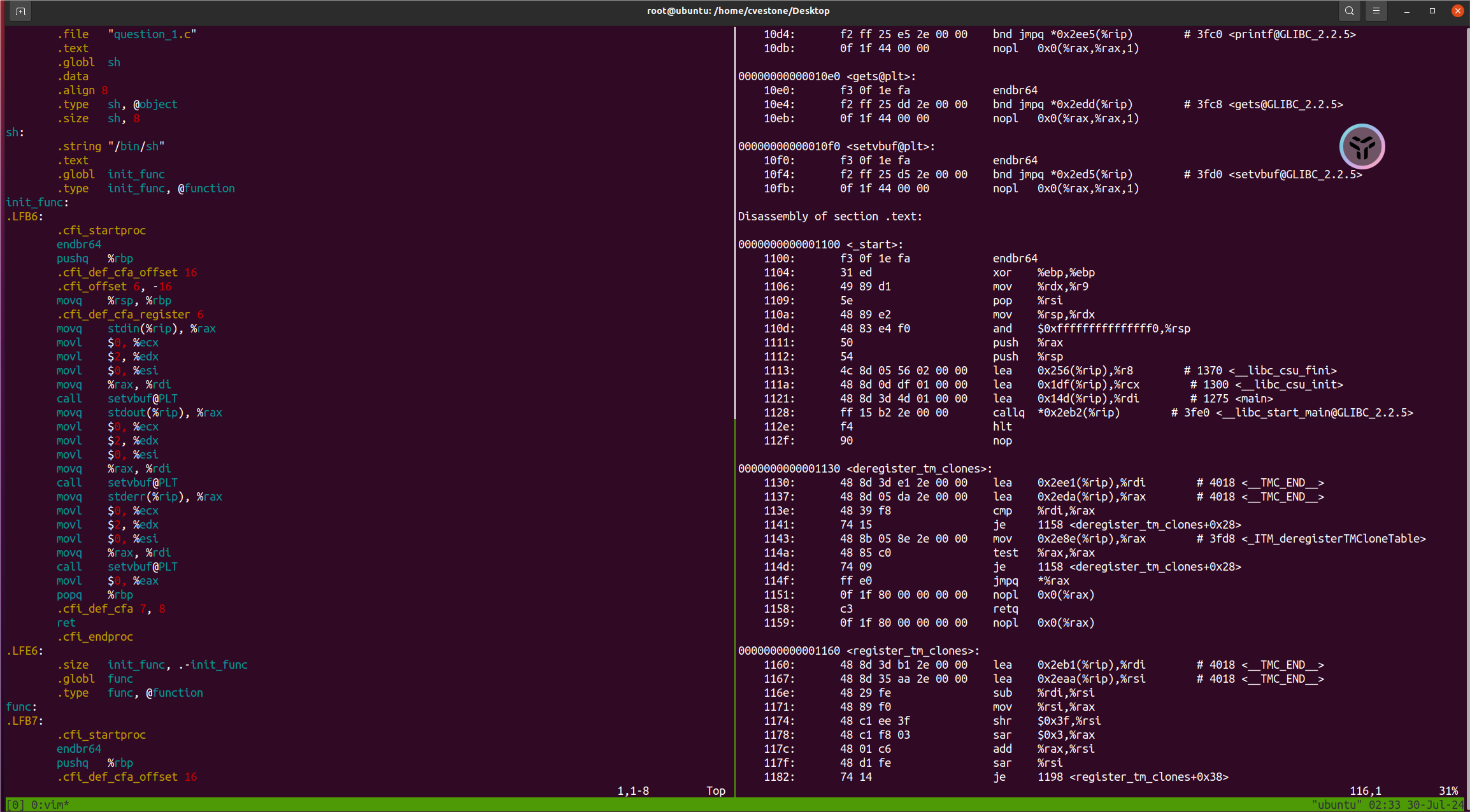 可以发现前者显示结果更加简洁,并且几乎只有汇编指令,也不像后者还有包含.plt等其他elf程序节中的细节信息
可以发现前者显示结果更加简洁,并且几乎只有汇编指令,也不像后者还有包含.plt等其他elf程序节中的细节信息

(3)-m32参数: 将程序用x86指令集编译成32位程序,但是要注意得提前安装好相应的库:
1 | sudo apt-get install gcc-multilib g++-multilib module-assistant |
(4)-O参数: 关于gcc的-O选项,有对应的等级,默认是1,意思是编译时优化的级别,比如课程中的源码:
1 |
|
观察源码会发现这里的if体中不可能执行,因为一开始都没有为b[0]赋值,但是编译时如果采取默认的优化级别,编译器会本着实事求是的原则,既然写了,就让该部分被编译,所以我们最终能实现缓冲区溢出获取shell,但是如果编译时优化级别设置较高,比如-O3,那么编译器会认为其不可能执行,所以不将该部分编译,我们就获取不到shell,也就是不可能执行func(sh)
(5)-static参数:
gcc加参数-static即可静态编译,静态编译后的程序明显比默认用动态编译的程序占用空间大:
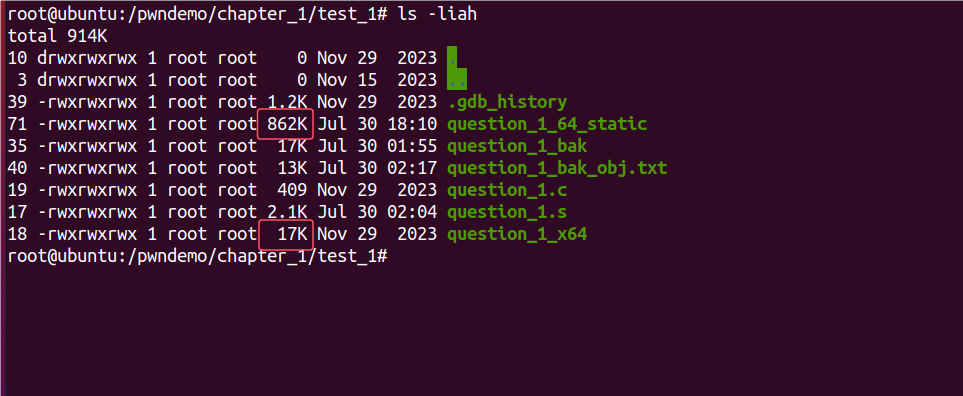
发现当检查保护的时候,同样都是默认编译的64位程序,静态程序则默认没有开启PIE:
 查看文件时也存在些差异:
查看文件时也存在些差异:  注意到静态程序是叫
注意到静态程序是叫executable,动态程序是叫shared object,发现既有标明静/动态链接,动态链接程序还标出了依赖外部的动态共享库文件/lib64/ld-linux-x86-64.so.2,而前者没有,因为静态链接可执行文件已包含了所有必需的库文件,不需要依赖外部的共享库
而且当查看两者的汇编指令时也能发现: 静态程序是:  而动态程序是:
而动态程序是: 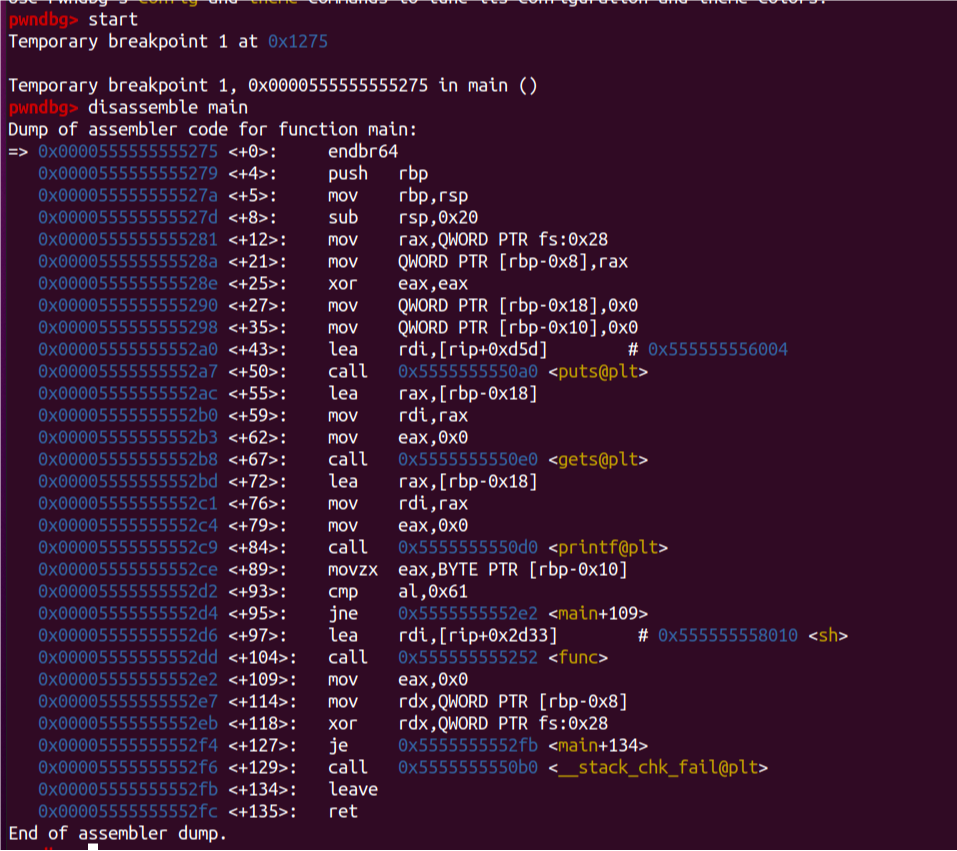 发现汇编代码几乎是一样的,只是偏移位置不一样,还有call调用函数时,动态链接程序是
发现汇编代码几乎是一样的,只是偏移位置不一样,还有call调用函数时,动态链接程序是xxx@plt,即得从plt表中寻找,因为前面提到过动态链接程序要依赖外部共享库
(6)-fno-omit-frame-pointer参数: 对解题的方法没啥区别,只是汇编指令部分发生了些变化。观察会发现原来基本都是以rbp/ebp为基准来计算、赋值的,加了该参数后,有些地方就可能以rsp/esp为基准。 同样还是以64位程序为例,只加该编译参数。
chatgpt对该参数的解释: 通过使用该选项,编译器将禁用帧指针的省略优化,确保帧指针在编译后的二进制文件中保留,例如,在进行调试或进行栈回溯(stack backtrace)时,帧指针可以提供更好的调试信息,帮助开发人员跟踪函数调用链和定位问题。
(7)-no-pie参数 效果看下面的实验。
0x04 主武器gdb
修改gdb默认反汇编显示格式
设置默认以intel格式输出反汇编代码:
1 | vim ~/.gdbinit |
最上面加上:
1 | set disassembly-flavor intel |
常用指令
gdb 程序名 【加载程序】 si 【步入】
ni 【步过】 finish 【步出】
start
【开始运行到程序入口点(注意是由gcc内部机制判断出来的,不一定完全准确,所以有些情况需要自己手动判断)】
i r 【这里是缩写,下文同理,查看当前所有用到的寄存器状态】
disassemble $rip 【反编译当前rip所在的指令上下文】
打印相关:
p $寄存器【打印寄存器中存的值(有时候还能用来计算寄存器的偏移地址,比如p
$rbp-0x10)】 p &函数名
【打印符号表中存在的某个函数地址】
断点相关:
b *地址【设置断点】
i b【查看所有设置的断点】 d 断点对应的序号
【删除指定断点(但是在实际运用中,一般不采用删除断点,而是让其失效,万一下次还要用到)】
disable b 断点对应的序号 【让指定断点失效】
enable b 断点对应的序号 【让已失效断点重新激活】
c(continue) 【运行到下一个断点为止】
内存相关重要指令
x指令:
x/20i 地址或$rip
【以汇编代码格式显示从该地址开始的20条内存单元中的数据】
(下面如果想要数据输出格式为十六进制,可以再加个x,如gx)
x/20b 地址或$rip
【以每1byte十进制格式显示从该地址开始的20条内存单元中的数据】
x/20g 地址或$rip
【以每8byte十进制格式显示从该地址开始的20条内存单元中的数据】
x/20s 地址或$rip 【以字符串格式…】
set指令:
set *地址=值 【将某个地址中的值设置为我们想要的值】
如果要设置寄存器中的值呢? 注意要强制转换一下先,如:
set *((unsigned int)$ebp)=0x18
vmmap指令:
用于显示当前线程的内存映射信息,通过查看内存映射信息,可以了解程序的内存布局,包括代码段、数据段、堆、栈以及共享库等的位置和属性。
0x05 汇编指令补充辨析
小背景:由于现在版本的编译器比起以前越来越智能,实际上很多指令在编译器编译时都很少用到了,一般都会做优化处理,而且时代变了,寄存器也不再像从前那样细分若干个并几乎各司其职,很多寄存器实际上编译时也用不到了,除了少部分寄存器几乎只履行自己职责外,如bp和sp类型寄存器一般用于栈操作、ip类型寄存器用于指向当前指令位置,大部分的很多寄存器其实都可以身兼多职。总之,ip类寄存器是老大,最重要的,bp类是老二,sp类是老三,因为内存离不开栈,栈需要bp和sp工作,剩余其他寄存器现在几乎都没啥区别了,也不是特别重要。
“已忘初心“lea指令
现在的编译器一般不用lea作为载入地址了(但是如果不加方括号的情况下是作为该原用途),一般用于计算,
比如 lea rax,[rbp-0x18]
【把rbp地址减去0x18后的地址给rax】
那么为什么不用
1 | sub rbp,0x18 |
因为这是编译器为了提高效率优化的方式,它占用的指令长度也更短。而且这种方式还不需要改变rbp的值就可以实现
异或指令xor
一般用于将寄存器的值归零,如xor eax,eax
cmp和sub
两个都是减,只是相减后的结果处理不同,cmp对相减后的结果不进行赋值存储,仅用于作判断,和条件跳转指令搭配着用,其实c语言中只要包含cmp的函数都是这个原理
test和and
and eax,eax test eax,eax ->
eax&eax, eax=0则结果为0;eax!=0则结果为!0
与sub和cmp的区别同理,test和and指令差不多,只是test只用于比较最后不赋值,而and赋值。
另外,这里的test eax,eax其实就相当于cmp eax,0,只是编译器为了优化而选用test而已。
move带单位PTR
如move eax,BYTE PTR [rbp-0x10],其中PTR代表指针,
意思是把[rbp-0x10]地址的值中取1个BYTE即8位给eax寄存器。
常见的单位还有:
1 | WORD DWORD QWORD |
0x06 cpu和寄存器和(虚拟)内存之间的关系
在传递数据时,cpu会优先从寄存器中取值,但是寄存器数量有限,如果定义的变量数目远超过寄存器数量,那么多余的变量会先存储在虚拟内存空间中,当需要时再和寄存器做交互传递值。比如上面的[rbp-0x10]就是从虚拟内存地址中找到然后传值的,然后像push就是把暂时用不到的先放到虚拟内存中。
0x07 pwn题常见函数
strcmp
这个函数常用于做字符串比较,实际看反汇编代码过程中其实当成cmp去识别就好了
0x08 pwn题远程部署
常用的部署命令:
1 | socat tcp-l:端口,fork exec:./程序名,reuseaddr |
0x09 用python脚本打pwn的原因
因为有些时候比如题目中的比较字符是一个不可打印字符,如0x10,虽然我们在gdb调试中可以试着将虚拟内存中对应的数据改成0x10从而getshell,但是在shell中运行程序时是输入不了像0x10这样的不可打印字符的,如果我们输入它,会被当成字符串,也就是会把0x10拆分着看,而不是将其当作一个整体,所以这时候要用到python脚本中已有的模块来实现
打pwn简单python脚本模板
1 | import socket |






