
ctfshow reverse record
ctfshow reverse record
cvestoneREVERSE
萌新赛
数学不及格
考察点:斐波那契数列、elf逆向还原函数参数、十六进制转可读字符串
丢到ida反编译后,首先我们要了解main函数尤其是括号内各参数的基本含义:
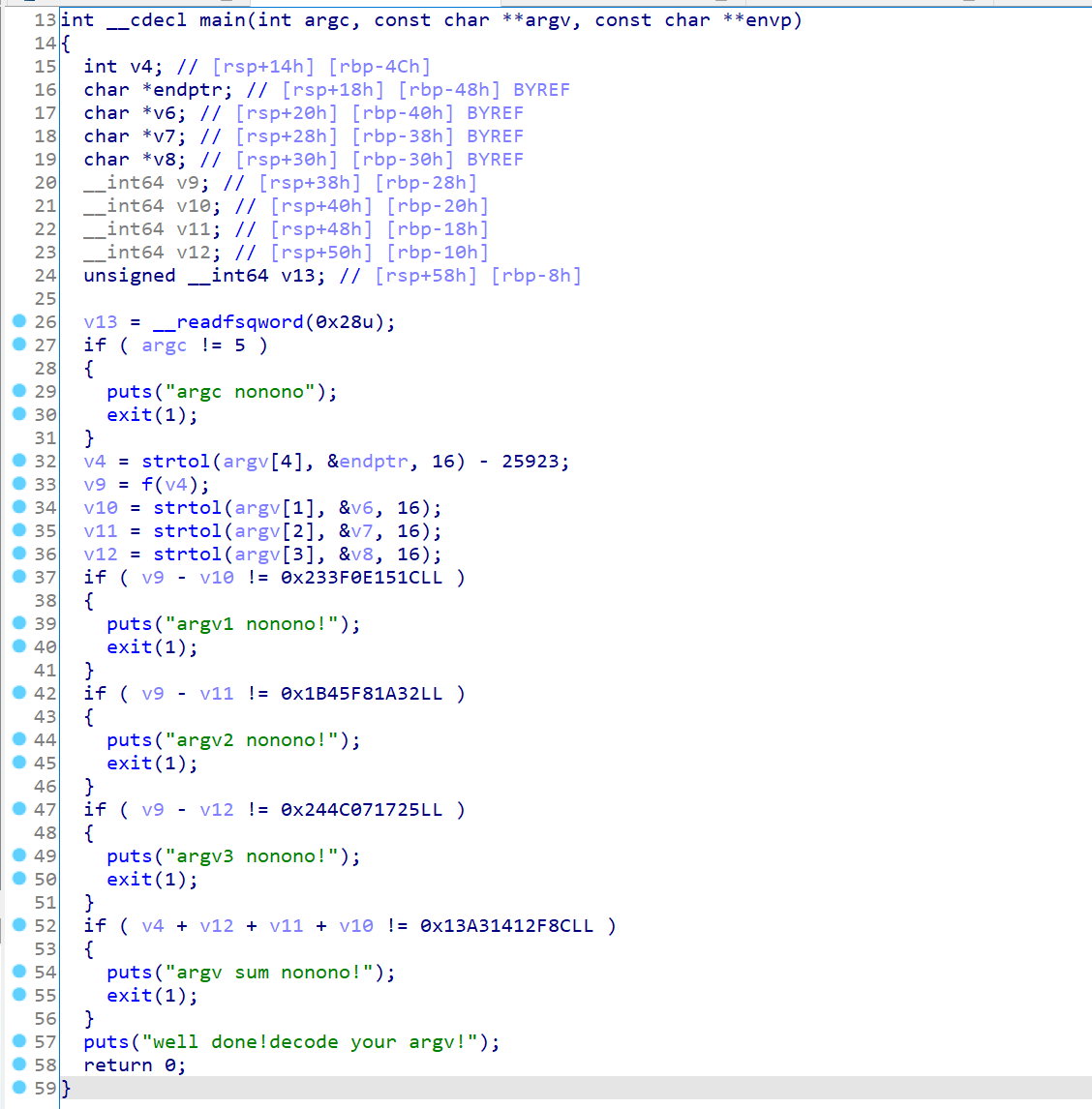
int argc:argc是一个整数,表示命令行参数的数量,包括程序名称本身。例如,如果命令行输入是./program arg1 arg2,则argc为 3。const char **argv:argv是一个指向字符串的指针数组,包含所有命令行参数。argv[0]是程序的名称,argv[1]是第一个参数,依此类推。const char **envp:envp是一个可选参数,指向环境变量的指针数组。每个环境变量都是一个字符串,格式为 “KEY=VALUE”。
注意:不是所有编译器都支持 envp 参数。
另外,这里的__cdecl是调用约定,指定如何调用函数(如参数如何传递和栈如何清理),它是
C 语言的默认调用约定,支持可变参数列表。
注意到这里用到了argv[],也能看出来这个main函数实际上是接收了4个参数,且都是十六进制数:

还有个较陌生的函数strtol,来自于c标准库,用于将字符串转换为长整型(long),分析其原型:

- nptr:要转换的字符串。
- endptr:用于指向未转换部分的指针。如果转换成功,指向字符串中第一个非数字字符的位置。
- base:指定基数,比如值为16意味着输入字符串被视为十六进制数。
main函数整体逻辑: 首先判断argc是否为5个,不是则输出错误信息并退出程序,然后分别将四个参数使用strtol函数转换为整数,分别存储到v10、v11、v12和v4中。接着将v4减去25923传入函数f,并将返回值存储到v9中。然后通过一系列运算条件做判断,如果不满足则输出相应错误信息并退出程序。最后如果满足求和运算,则输出成功信息。
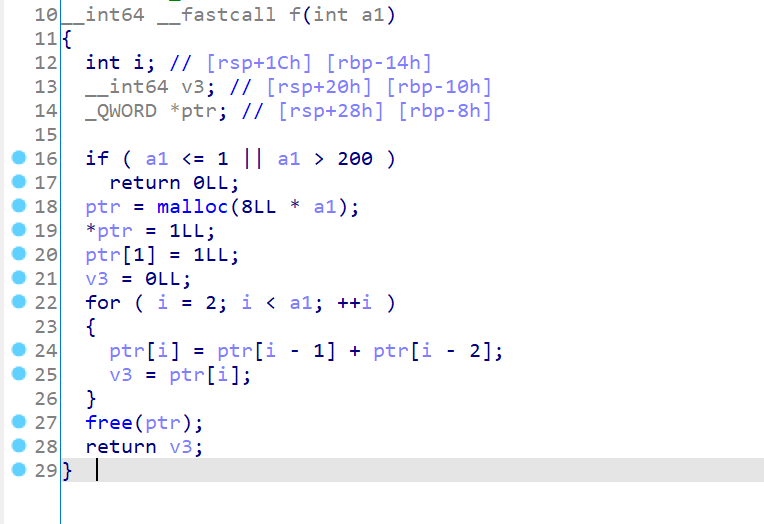
因为逆向中一般和算法有关,上面出现的都是一些正常的简单判断逻辑,这里的函数f是关键,分析可知f包含着斐波那契数列算法:
 关于斐波那契数列,其中每个数都是前两个数的和。数列的定义如下:
关于斐波那契数列,其中每个数都是前两个数的和。数列的定义如下:
- 初始条件:
- (
F(0) = 0) - (
F(1) = 1)
- (
- 递推关系:
- (
F(n) = F(n-1) + F(n-2)) (对于 (n \geq 2)) 伪代码中,首先将从main接收过来的整型参数a1(v4)作为需要计算的斐波那契数列中的第几个数,首先判断参数是否在规定范围(1,200]内,然后用malloc动态分配内存空间存放斐波那契数列的值,接着用for循环根据斐波那契数列的递推关系,直到计算出第a1个数的值停止循环,最后释放内存并把返回的计算结果赋给main的v9。f中我们无法算出项数a1(v4)和对应的数列值v3,回到main中结合所有判断条件看看有无新发现,即使不明白题意,先抽丝剥茧,发现合并同类项后最终可以得到只含v4和v9的表达式,如下: 到这一步,可以借助在线的斐波那契数列计算网站,生成指定数量的数列,然后看哪一项的值和这里v9的粗略值591286729879(因为v4/3几乎可以忽略不计,即使v4项数大)最为接近,从而我们就可以大致推出来v4的值是多少,我们生成60项,最终在58项时看到了一样的值,因此此时v4
到这一步,可以借助在线的斐波那契数列计算网站,生成指定数量的数列,然后看哪一项的值和这里v9的粗略值591286729879(因为v4/3几乎可以忽略不计,即使v4项数大)最为接近,从而我们就可以大致推出来v4的值是多少,我们生成60项,最终在58项时看到了一样的值,因此此时v4≈58,v9≈591286729879 发现还可以推算出来其他参数的粗略值:
这里要注意根据ida的伪代码,v4还要进行处理。
- (
 到这一步,可以借助在线的斐波那契数列计算网站,生成指定数量的数列,然后看哪一项的值和这里v9的粗略值591286729879(因为v4/3几乎可以忽略不计,即使v4项数大)最为接近,从而我们就可以大致推出来v4的值是多少,我们生成60项,最终在58项时看到了一样的值,因此此时v4
到这一步,可以借助在线的斐波那契数列计算网站,生成指定数量的数列,然后看哪一项的值和这里v9的粗略值591286729879(因为v4/3几乎可以忽略不计,即使v4项数大)最为接近,从而我们就可以大致推出来v4的值是多少,我们生成60项,最终在58项时看到了一样的值,因此此时v4 发现还可以推算出来其他参数的粗略值:
发现还可以推算出来其他参数的粗略值: 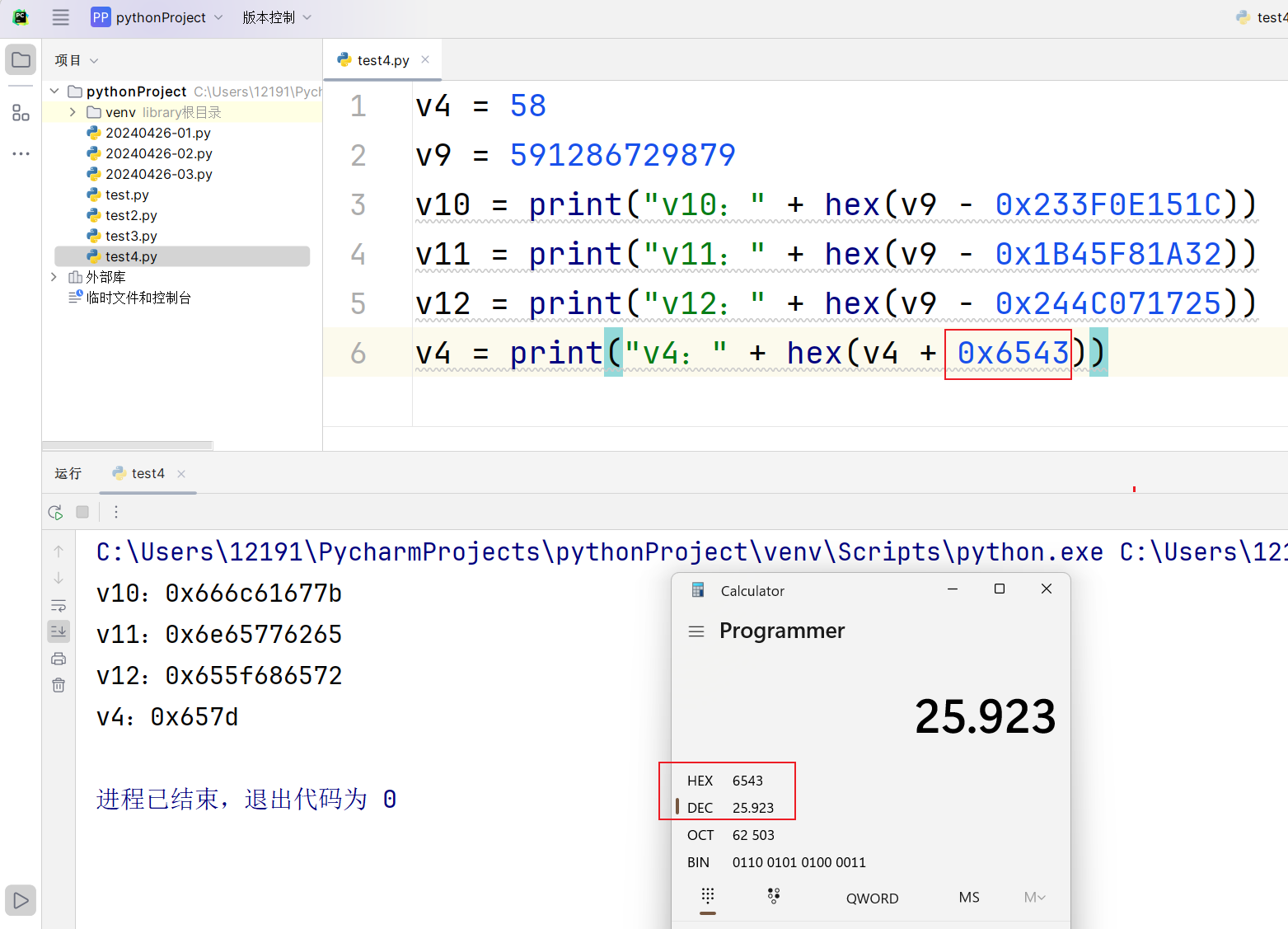 这里要注意根据ida的伪代码,v4还要进行处理。
这里要注意根据ida的伪代码,v4还要进行处理。所以到这一步就知道了题目的用意,是想让我们通过斐波那契数列算法,结合已知的表达式,逆向还原出函数的各个传参值,这题的核心就是数学中的解方程和估算。那么此时我们只要将还原出的参数分别按照定义好的参数位置摆放,执行程序时传参,就可以输出最后的成功语句,注意都要是十六进制,这样才能满足表达式中的计算:
 根据成功语句提示,把这些参数组合在一起,解码成字符串就可以得到flag,而要把十六进制转换成字符串,显然要借助编码来完成转义,比如ascii码,每两个十六进制数字代表一个字符(字节),可以将其分组再转换,首先要将十六进制字符串转换为字节流,再将字节流解码为
UTF-8
字符串,可以得到可读的文本格式,因为字节流才是计算机处理数据的基本单位,能够准确表示原始数据:
根据成功语句提示,把这些参数组合在一起,解码成字符串就可以得到flag,而要把十六进制转换成字符串,显然要借助编码来完成转义,比如ascii码,每两个十六进制数字代表一个字符(字节),可以将其分组再转换,首先要将十六进制字符串转换为字节流,再将字节流解码为
UTF-8
字符串,可以得到可读的文本格式,因为字节流才是计算机处理数据的基本单位,能够准确表示原始数据:
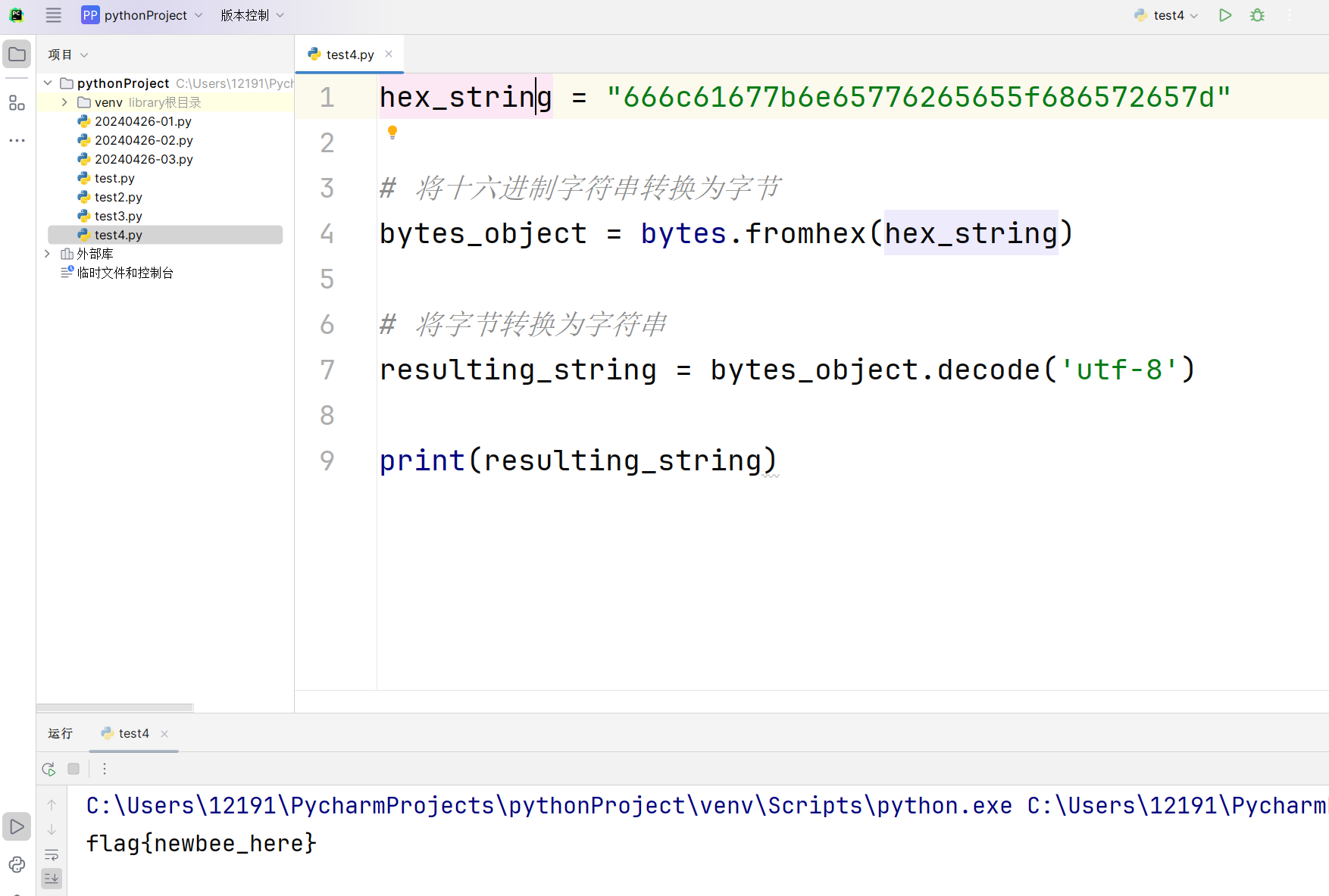 这里的编码用ascii解码也能得到同样结果:
这里的编码用ascii解码也能得到同样结果:
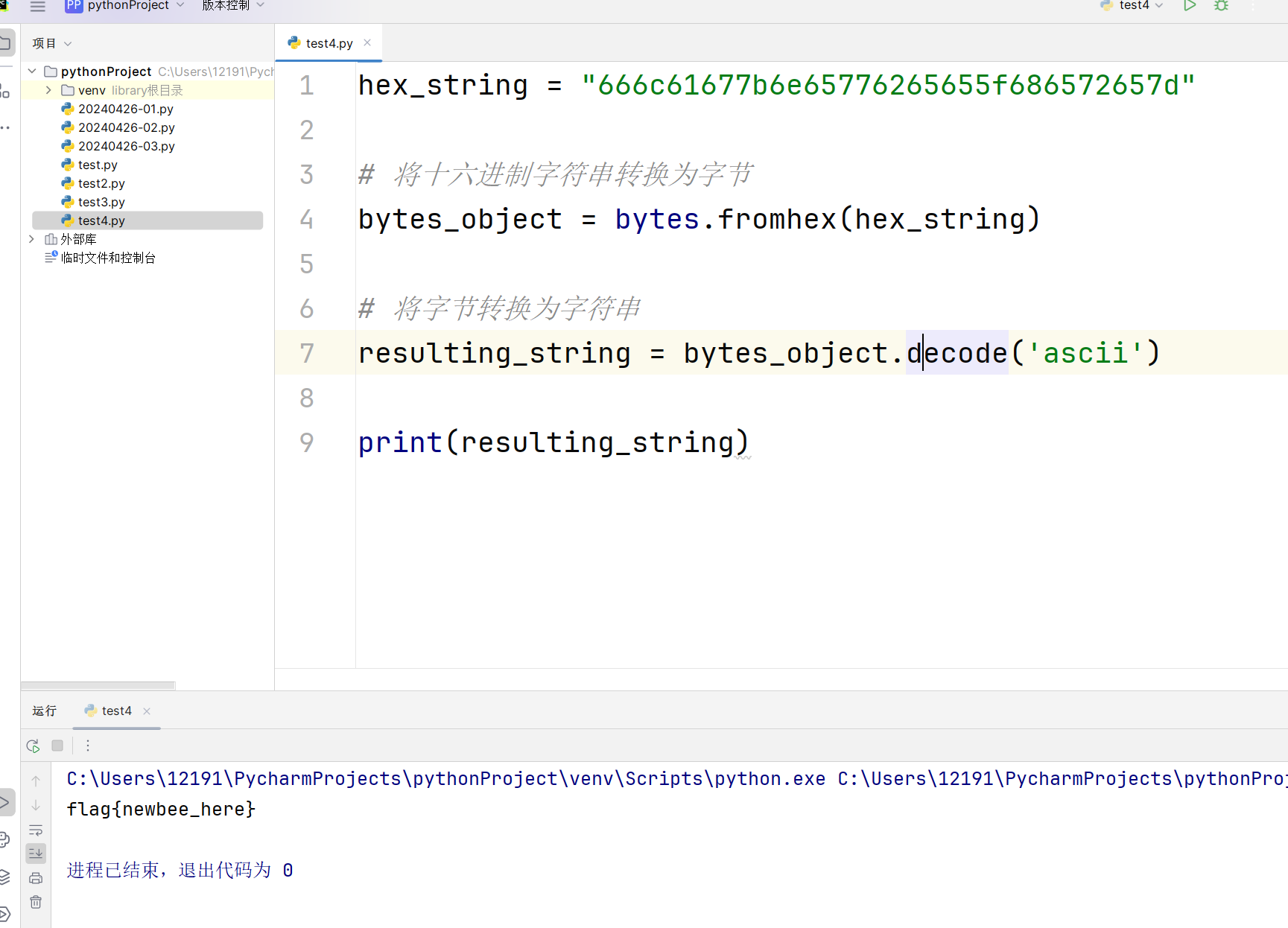
flag白给
考察点:upx脱壳、ollydbg基本使用、windows PE基本逆向
运行程序,初步观察意图: 
 也就是要输入正确的序列号才能给flag,这也看起来像逆向中基本的软件破解类型。
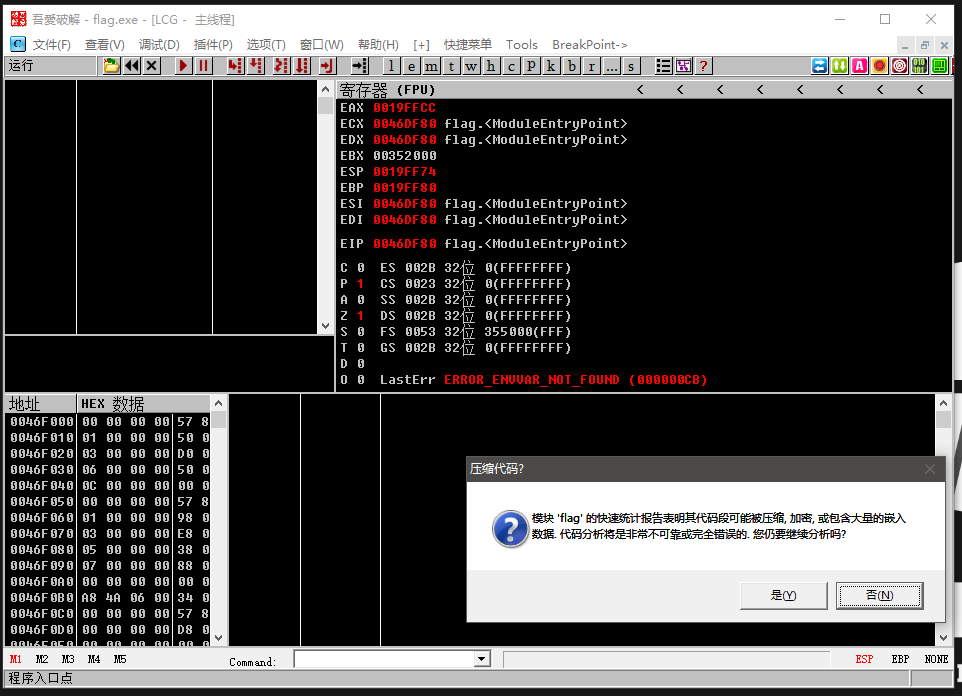
但是当丢到ida后发现找不到main函数,并且反编译后发现逻辑也很奇怪,不像是程序的正常逻辑,此时猜测可能是做了加密混淆被加壳了,既然静态分析遇到阻碍,尝试丢到动态调试器ollydbg中,弹出的警告窗也告知我们这个程序很有可能被处理过:
也就是要输入正确的序列号才能给flag,这也看起来像逆向中基本的软件破解类型。
但是当丢到ida后发现找不到main函数,并且反编译后发现逻辑也很奇怪,不像是程序的正常逻辑,此时猜测可能是做了加密混淆被加壳了,既然静态分析遇到阻碍,尝试丢到动态调试器ollydbg中,弹出的警告窗也告知我们这个程序很有可能被处理过:
 丢到查壳工具如Exeinfo PE:
丢到查壳工具如Exeinfo PE:  分析出是upx壳,并且告知签名像是来自于UPX
packer,还提供解该upx壳的方式和链接:
分析出是upx壳,并且告知签名像是来自于UPX
packer,还提供解该upx壳的方式和链接:
unpack "upx.exe -d" from http://upx.github.io or any UPX/Generic unpacker
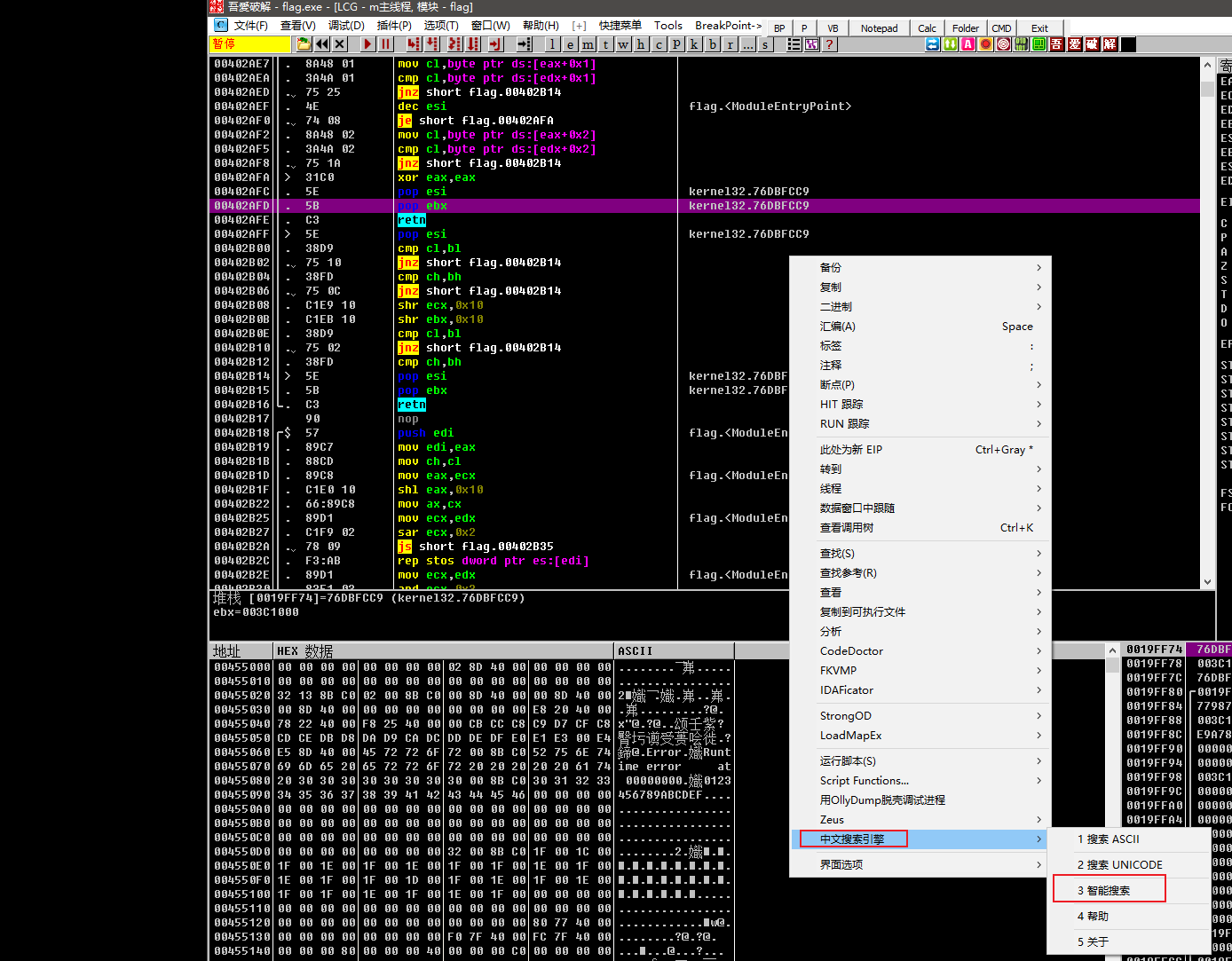
尝试脱upx壳:  重新丢到ida后发现函数和各个显示项就正常了,也能反编译出正常逻辑的伪代码,shift+F12后没有发现和flag相关的字符串,我们现在逆向破解的目的就是找到输入序列号弹出提示弹窗对应的逻辑代码,看看能不能修改其逻辑达到逆向破解的效果,而提示符是中文的,要运行程序后才能显示,显然此时用动态调试器更合适,丢到OD,根据弹窗逻辑搜索字符串“错误”,发现附近有其对立的词“成功”:
重新丢到ida后发现函数和各个显示项就正常了,也能反编译出正常逻辑的伪代码,shift+F12后没有发现和flag相关的字符串,我们现在逆向破解的目的就是找到输入序列号弹出提示弹窗对应的逻辑代码,看看能不能修改其逻辑达到逆向破解的效果,而提示符是中文的,要运行程序后才能显示,显然此时用动态调试器更合适,丢到OD,根据弹窗逻辑搜索字符串“错误”,发现附近有其对立的词“成功”:
 双击该位置,就会跳转到对应反汇编代码处:
双击该位置,就会跳转到对应反汇编代码处:
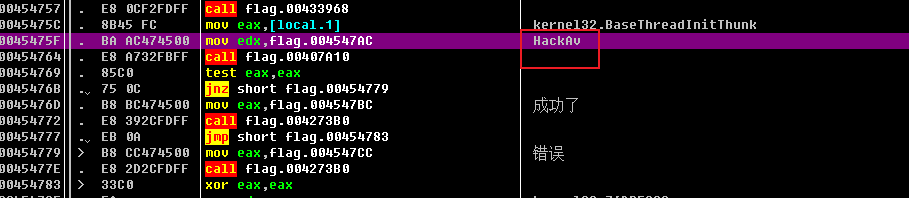 由该片段的反汇编代码分析及推测,显然这里的
由该片段的反汇编代码分析及推测,显然这里的HackAv很可能就是正确的序列号,即flag。
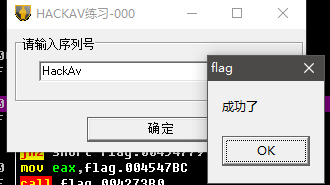
(未完待续)签退
考察点:pyc to py
关于
.pyc文件:.pyc文件是Python程序编译后的字节码文件,通常在模块导入时自动生成。它们的存在主要是为了提高程序的加载速度,因为解释器可以直接执行这些字节码而不需要再次编译源代码(.py文件)。.pyc文件是优化Python程序执行效率的一种方式,通过减少重复编译的需求来加快程序启动速度。然而,它们并非必需,缺少.pyc文件时,Python解释器会直接从.py源文件运行程序。
如果是windows使用pycdc和pycdas,可以用visual studio来编译安装: 
 然后再切换编译安装pycdas:
然后再切换编译安装pycdas:  快捷键用
快捷键用ctrl+F5。
然后尝试用安装好的pycdc直接反编译,看是否能直接生成py源码:  这里反编译成功了。如果不能,可能还需要配合pycdas反汇编来进一步分析字节码。
观察源代码似乎是一个加密算法,其中这里的flag实际上可能只是加密中的密钥或密文,而不是最终的flag。深入分析下反编译后的源码:
这里反编译成功了。如果不能,可能还需要配合pycdas反汇编来进一步分析字节码。
观察源代码似乎是一个加密算法,其中这里的flag实际上可能只是加密中的密钥或密文,而不是最终的flag。深入分析下反编译后的源码:
1 | # Source Generated with Decompyle++ |
加密算法分析
逆向思路
逆向解密编写
1 | import string |

内部赛
(未完待续)真的是签到
描述:flag 格式 ctfshow{XX} zip
考察点:
拿到的文件名是zip,通过010editor检查其文件头,确实是zip压缩包文件,将其重命名为xx.zip,然后解压,提示需要密码,先看看是否是伪加密,找到压缩源文件目录区:
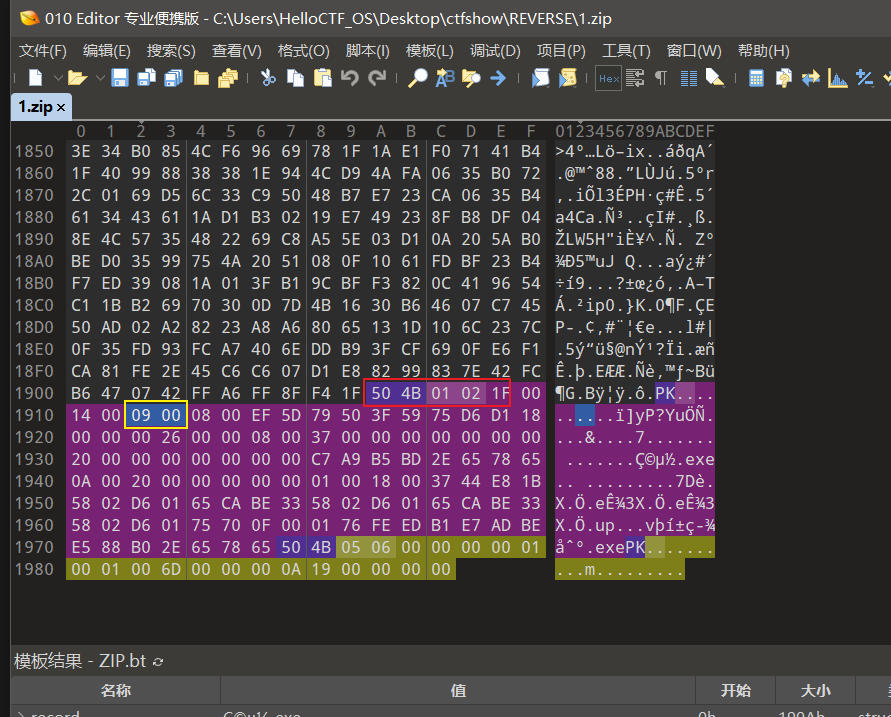 这里的全局方式位标记是奇数,说明可能是伪加密,尝试改成0000,覆盖原来的zip文件,成功解压:
这里的全局方式位标记是奇数,说明可能是伪加密,尝试改成0000,覆盖原来的zip文件,成功解压:
 分析该exe,存在asp压缩壳:
分析该exe,存在asp压缩壳:  用ask脱壳工具脱壳并检查:
用ask脱壳工具脱壳并检查: 
 未知保护但检测出了upx
packer的签名,说明可能还嵌套了一层upx壳,尝试upx脱壳:
未知保护但检测出了upx
packer的签名,说明可能还嵌套了一层upx壳,尝试upx脱壳:  直接用官方自带命令脱壳失败,说明它可能是个变种壳,即除了常规upx壳外还可能被
直接用官方自带命令脱壳失败,说明它可能是个变种壳,即除了常规upx壳外还可能被UPXR、UPXSCREAMBLE等做了其他处理,可以先尝试用upxfix解决这些干扰后再重新用官方命令脱壳,然而和官方命令的输出一样提示该文件不是upx壳:
 不要盲目绝对相信输出,也有可能只是程序做了防护措施或加了干扰,此时可以尝试搜索报错中的输出,并没有找到什么很有价值的信息,但部分文章提示到可以尝试看看文件中是否包含UPX的魔术字符,显然上面的检测工具能检测到签名也是和魔术字符有关。把解完asp壳的exe丢到010
editor:
不要盲目绝对相信输出,也有可能只是程序做了防护措施或加了干扰,此时可以尝试搜索报错中的输出,并没有找到什么很有价值的信息,但部分文章提示到可以尝试看看文件中是否包含UPX的魔术字符,显然上面的检测工具能检测到签名也是和魔术字符有关。把解完asp壳的exe丢到010
editor: 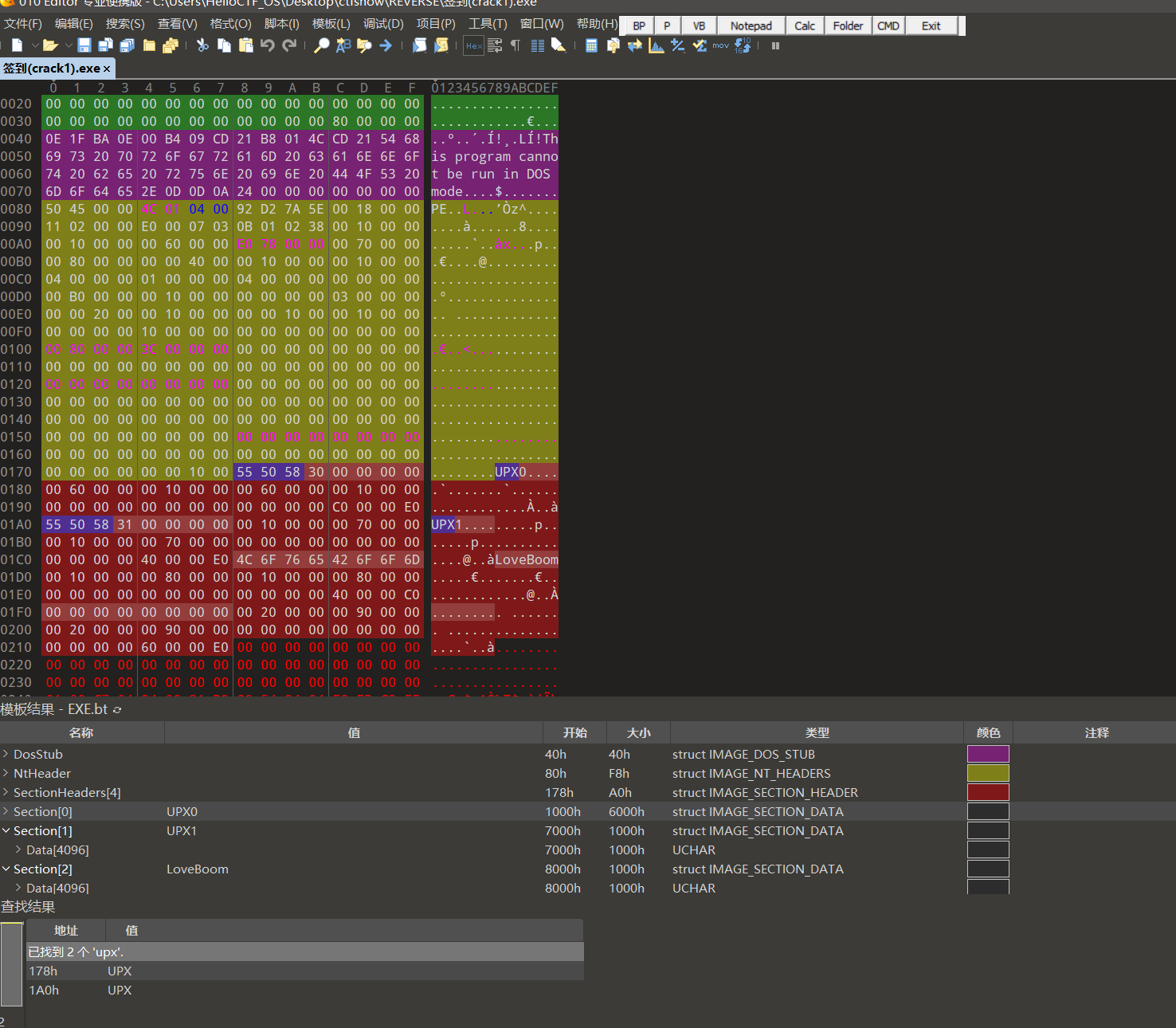 确实有,但由于经验尚浅,暂时看不出其他更多额外隐藏特征。
最后的办法只能用动态调试器手动尝试脱壳了:
确实有,但由于经验尚浅,暂时看不出其他更多额外隐藏特征。
最后的办法只能用动态调试器手动尝试脱壳了:
批量生产的伪劣产品
描述:flag 格式ctfshow{XXX} checkme.apk - 蓝奏云
考察点:AndroidManifest.xml文件和<activity>的基本认识
用jadx反编译后,查看AndroidManifest.xml文件,关注主要的组件:
 不同组件对应不同的类,可以分别定位过去查看一下:
其中在类a中直接能搜索到flag:
不同组件对应不同的类,可以分别定位过去查看一下:
其中在类a中直接能搜索到flag: 
AndroidManifest.xml是 Android 应用的核心配置文件,它告诉操作系统:这个 App 包含什么组件、具备哪些权限、对外暴露什么功能,以及 启动逻辑和入口 是什么。可以看作是每个 Android App 的“身份证”和“功能说明书”,不写或写错它,App 根本无法运行或安装。 AndroidManifest.xml 中的<activity>标签用于声明应用中的一个 Activity 组件,即用户界面中的一个屏幕。系统通过该标签了解应用中有哪些活动页面,以及每个页面的属性和行为。
来一个派森
描述:flag格式ctfshow{} checkme.exe - 蓝奏云
考察点:exe to py、base58编码
派森的谐音显然是python,可以推测这是用python写完然后打包成exe的程序。
可用pyinstxtractor/pyinstxtractor-ng来提取:  默认生成在工具同目录下:
默认生成在工具同目录下:  接着pyc转py:
接着pyc转py: 

1 | def b58encode(tmp=None): |
加密算法分析
首先对tmp(即flag转换后的ASCII 码列表)中的每个字符temp,将原字节序列转换为大整数并拼接,因为需要先将普通字符串转换为字节序列(ASCII 码),再视为大整数后,才能进行 Base58 编码。
这里实现拼接用到了temp = temp * 256 + tmp[i + 1],即左移8位(256=2^8)后,把序列中的下一个temp字符拼接上来构成大整数。例如,字符串 "abc" 的
ASCII 码是 [97, 98, 99],转换为大整数的过程:
temp = 97('a')temp = 97 * 256 + 98 = 24930('a'左移 8 位 +'b')temp = 24930 * 256 + 99 = 6382179('ab'左移 8 位 +'c')- 最终大整数是
6382179(即0x616263,对应"abc"的十六进制表示)。 可以发现按这个顺序是大端序(高位字节在前),符合人类阅读书写习惯,且大端序是网络传输和常见编码的标准顺序。
同理,假设用十进制模拟(类比字节是 0~9 的数字): 拼接
序列[1, 2, 3] 成数字 123:
正确方法(左移):1 * 10 + 2 = 12,再
12 * 10 + 3 = 123,也就是以进制为基准进行计算,最后实现拼接。
错误方法(右移):1 / 10 + 2 = 0 + 2 = 2,再 2 / 10 + 3 = 3,得到
3(这相当于提取数字了而不是拼接)。 所以:
- 左移(
* 256):是拼接字节的正确操作,保留高位腾出空间用于低位扩展,可以发现左移实际上就相当于让其变成更高进制数(比如原先在个位的1左移后就变成10) - 右移(
/ 256):是分解字节的操作(如解码时),不能用于拼接。
计算机存储数字时,高位在左,低位在右,拼接需要向左扩展空间。
Base58 编码通常用于将大整数(如比特币地址、哈希值)转换为可读字符串,注意只有大整数才能作为Base58 编码的输入。
对于:
1 | tmp = [] |
temp是前面已经进行base58编码后的字符串,ord(temp[i]) ^ i,对字符
temp[i] 的 ASCII 码与索引 i
按位做异或运算,例如,假设 temp[0] = 'A'(ASCII
码 65),索引 i = 0:65 ^ 0 = 65,结果仍为A;temp[1] = '4'(ASCII
码 52),索引 i = 1:52
的二进制:00110100,1
的二进制: 00000001,异或结果: 00110101(十进制 53,对应字符 '5')。接着通过append()将异或后的结果拼接,然后存放于tmp列表。最后,将tmp列表与预定义好的check做比对,如果都匹配,则b58encode返回1,说明flag正确。
逆向思路
显然根据上述加密算法,对check列表逆着推导还原就行,由于异或本身就是可逆的,所以将check异或后再base58解码就能得到flag。
逆向解密编写
1 | # Base58 解码函数(将 Base58 字符串还原为原始字节序列) |

(未完待续)屏幕裂开了
描述:你的手机屏幕能承受住那么多次点击吗? ClickStorm.apk
考察点:






